



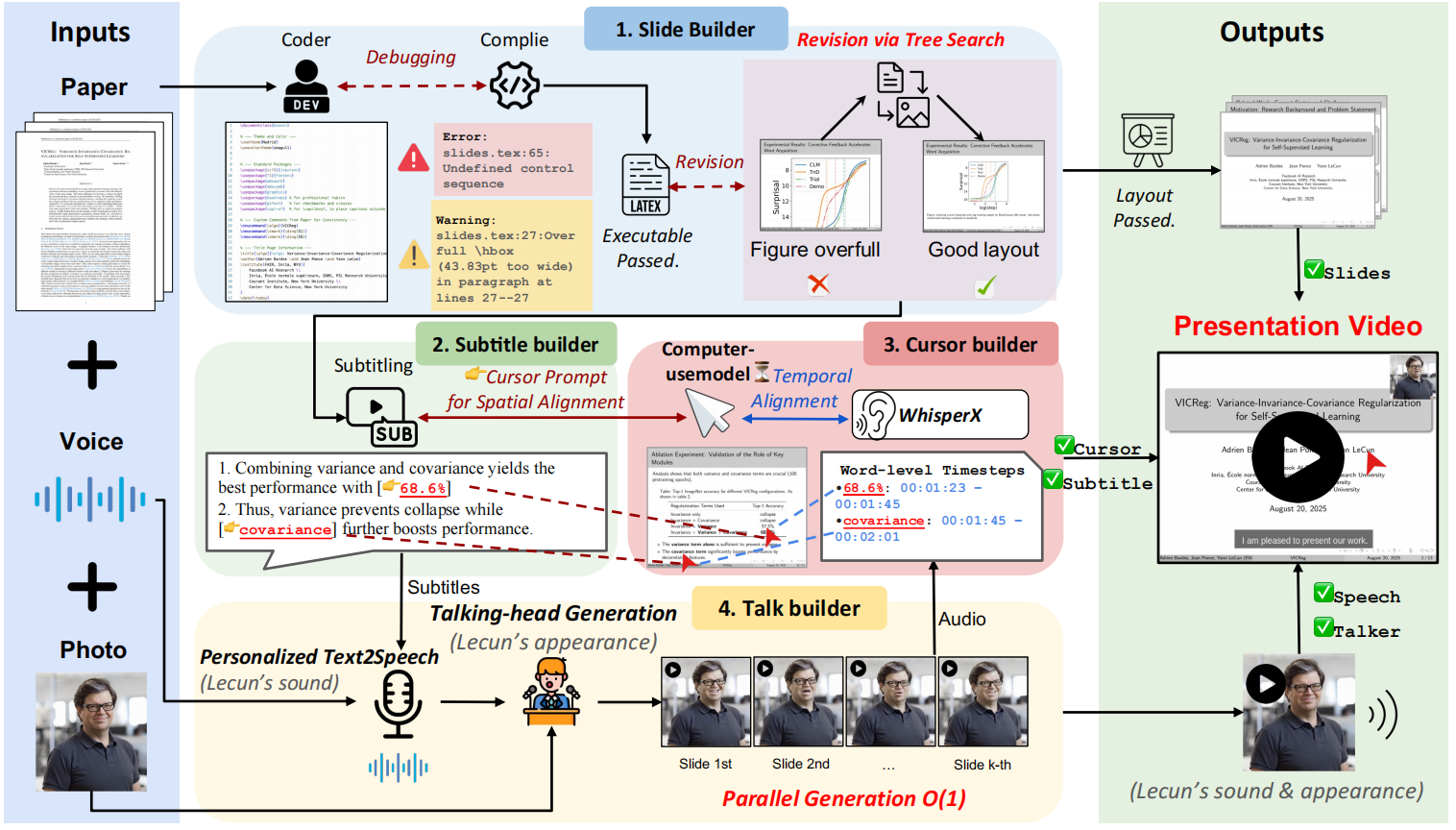
Paper2Video 是一个开源项目,旨在将研究人员从准备学术演讲视频的繁重工作中解放出来。 该项目核心是一个名为 PaperTalker 的多智能体框架,它能接收一篇用 LaTeX 编写的论文、一张演讲者的参考图片和一段参考音频,然后全自动地生成一个完整的演讲视频。 PaperTalker 会自动完成从内容提取、幻灯片(Slides)制作、字幕生成、语音合成、鼠标轨迹、到虚拟数字人演讲视频渲染的整个流程。 为了科学地评估生成视频的质量,该项目还提出了一个名为 Paper2Video 的评测基准,包含101篇论文及对应的作者演讲视频,并设计了多个评估维度来衡量视频能否准确传达论文信息。
功能列表
- 多智能体协作:使用包括幻灯片生成器、字幕生成器在内的多个智能体分工协作,完成复杂的视频生成任务。
- 自动化幻灯片生成:直接从 LaTeX 论文源码中提取核心内容,自动生成适用于演讲的幻灯片,并能通过编译反馈优化排版布局。
- 语音与字幕合成:根据幻灯片内容生成对应的演讲稿,并利用文本转语音(TTS)技术合成音频,同时生成时间戳精确对齐的字幕。
- 鼠标轨迹模拟:分析演讲内容和幻灯片元素,自动生成模拟真人的鼠标移动和点击轨迹,用于在讲解时指引观众的注意力。
- 虚拟数字人生成:仅需一张演讲者的正面照片,即可生成一个在视频中进行演讲的虚拟数字人(Talking Head),让视频更具表现力。
- 并行处理:对每一页幻灯片的相关生成任务(如语音、鼠标轨迹等)进行并行处理,大幅提升视频生成的效率。
- 两种生成模式:提供包含虚拟数字人的完整模式和不含虚拟数字人的快速模式,用户可以根据需求进行选择。
使用帮助
Paper2Video 提供了一个自动化的管道,可以将 LaTeX 格式的论文项目、演讲者图片和音频样本合成为一个完整的学术演讲视频。
1. 环境准备
开始前,需要准备好项目运行所需的环境。推荐使用 Conda 创建独立的 Python 环境以避免包版本冲突。
主要环境安装:
首先,克隆项目代码并进入 src 目录,然后创建并激活 Conda 环境。
git clone https://github.com/showlab/Paper2Video.git
cd Paper2Video/src
conda create -n p2v python=3.10
conda activate p2v
接着,安装所有必需的 Python 依赖包和 LaTeX 编译器 tectonic。
pip install -r requirements.txt
conda install -c conda-forge tectonic
虚拟数字人环境安装(可选):
如果不需要生成虚拟数字人演讲视频(即运行快速版),可以跳过此步骤。虚拟数字人功能依赖 Hallo2 项目,需要为其创建一个独立的环境。
# 在 Paper2Video 项目根目录下
git clone https://github.com/fudan-generative-vision/hallo2.git
cd hallo2
conda create -n hallo python=3.10
conda activate hallo
pip install -r requirements.txt
安装完成后,你需要记下这个 hallo 环境的 Python 解释器路径,后续运行时会用到。可以通过以下命令查找路径:
which python
2. 配置大语言模型 (LLM)
Paper2Video 的内容理解和生成能力依赖于强大的大语言模型。你需要配置你的 API 密钥。项目推荐使用 GPT-4.1 或 Gemini 2.5-Pro 以获得最佳效果。
在终端中导出你的 API 密钥作为环境变量:
export GEMINI_API_KEY="你的Gemini密钥"
export OPENAI_API_KEY="你的OpenAI密钥"
3. 执行视频生成
Paper2Video 提供了两个主要的执行脚本:pipeline_light.py 用于快速生成(不含虚拟数字人),pipeline.py 用于生成包含虚拟数字人的完整版视频。
最低硬件要求:推荐使用至少配备 48GB显存的 NVIDIA A6000 GPU 来运行此流程。
快速模式(不含虚拟数字人)
这个模式会跳过耗时较长的虚拟数字人渲染步骤,快速生成带有配音、字幕和鼠标轨迹的幻灯片视频。
执行以下命令:
python pipeline_light.py \
--model_name_t gpt-4.1 \
--model_name_v gpt-4.1 \
--result_dir /path/to/output \
--paper_latex_root /path/to/latex_proj \
--ref_img /path/to/ref_img.png \
--ref_audio /path/to/ref_audio.wav \
--gpu_list [0,1,2,3,4,5,6,7]
完整模式(包含虚拟数字人)
这个模式会执行所有步骤,生成一个包含演讲者画面的完整视频。
执行以下命令:
python pipeline.py \
--model_name_t gpt-4.1 \
--model_name_v gpt-4.1 \
--model_name_talking hallo2 \
--result_dir /path/to/output \
--paper_latex_root /path/to/latex_proj \
--ref_img /path/to/ref_img.png \
--ref_audio /path/to/ref_audio.wav \
--talking_head_env /path/to/hallo2_env \
--gpu_list [0,1,2,3,4,5,6,7]
参数说明
model_name_t: 用于处理文本任务的大语言模型名称,例如gpt-4.1。result_dir: 输出结果的保存目录,包括生成的幻灯片、视频等。paper_latex_root: 你的 LaTeX 论文项目根目录。ref_img: 演讲者的参考图片,必须是正方形的人像照片。ref_audio: 演讲者的参考音频,用于克隆音色,推荐提供10秒左右的样本。talking_head_env: (仅完整模式需要)之前安装的hallo环境的 Python 解释器路径。gpu_list: 用于并行计算的 GPU 设备列表。
运行结束后,你可以在指定的 result_dir 目录中找到所有中间文件和最终生成的视频。
应用场景
- 学术会议报告
研究人员可以利用 Paper2Video,快速将自己的论文转化为视频报告,用于线上会议分享或作为会议提交材料。这大大节省了手动制作幻灯片和录制视频的时间。 - 研究成果传播
将复杂的论文内容制作成易于理解的视频,发布在社交媒体或视频平台,可以帮助研究成果触及更广泛的受众,提升学术影响力。 - 教育和课程材料
教师和学者可以将经典的或最新的学术论文转化为教学视频,作为课程材料,帮助学生更直观地理解前沿的科学知识。 - 论文预讲和排练
在正式进行线下答辩或报告前,作者可以使用该工具生成一个预览视频,检查报告的逻辑流程、时间控制和视觉效果,从而进行优化和迭代。
QA
- 这个项目解决了什么核心问题?
此项目主要解决学术演讲视频制作耗时耗力的问题。传统上,研究人员需要花费大量时间设计幻灯片、撰写讲稿、录音和剪辑。Paper2Video 通过自动化的方式,旨在将研究者从这项繁琐的任务中解放出来。 - 生成一个视频需要准备哪些输入文件?
你需要准备三样东西:一篇使用 LaTeX 格式编写的完整论文项目、一张演讲者的正面方形照片、以及一段约10秒的演讲者参考录音。 - 我对硬件要求不了解,我的普通电脑可以运行吗?
该项目对硬件的要求非常高,特别是GPU。官方推荐至少使用拥有48GB显存的 NVIDIA A6000 GPU。普通的个人电脑或笔记本电脑很可能无法运行完整的生成流程,特别是包含虚拟数字人渲染的部分。 - 如果我不想在视频中露脸,可以使用这个工具吗?
可以。项目提供了pipeline_light.py脚本,它会运行一个快速模式,生成包含所有核心元素(幻灯片、配音、字幕、鼠标轨迹)的视频,但不会包含虚拟数字人画面。这个模式对计算资源的要求也相对较低。































