

在构建基于大型语言模型(LLM)的知识库问答应用时,开发者普遍会采用检索增强生成(RAG)技术。然而,RAG 的实际效果常常受限于一个核心矛盾:如何平衡检索的精确性与上下文的完整性。如果文本切片(Chunk)过小,虽然能精准命中用户查询,但提供给 LLM 的上下文不足,导致回答质量下降;如果切片过大,虽然上下文完整,却可能引入过多噪声,反而降低了检索的准确度。
为了应对这一挑战, Dify 在 1.9.0 版本中引入了名为 Parent-child-HQ 的内置知识处理流水线模板。该模板采用“父子分块”(Parent-Child Chunking)策略,通过一种巧妙的层级化分块方法,试图同时实现鱼与熊掌兼得。本文将从核心理念、实践配置以及源码实现三个层面,深入剖析这一功能。
核心理念:父子分块策略
“父子分块”策略的核心思想是将文本信息结构化为两个层级进行处理,从而解耦检索匹配与内容生成这两个环节对文本粒度的不同要求。
- 子块(Child Chunks)用于精确匹配:原始文档被拆分成一系列细粒度的、内容高度集中的“子块”。这些子块通常是一句话或一个短段落,专门用于和用户的查询向量进行语义相似度计算。由于其粒度小,能够实现非常精确的匹配。
- 父块(Parent Chunks)用于提供完整上下文:每个子块都归属于一个范围更大的“父块”,这个父块可能是一个完整的段落、一个章节,甚至是整篇文档。当系统通过子块锁定最相关的匹配项后,实际送入 LLM 进行内容生成的,是包含这些子块的完整“父块”。
这种机制确保了 LLM 在回答问题时,能够“阅读”到匹配信息所在的最完整的原始语境,从而生成逻辑连贯且信息丰富的回答。
这一高级策略依赖向量检索来计算语义相似度,因此仅支持 Dify 知识库中的 HQ(高质量) 索引模式。高质量模式会将文本通过 Embedding 模型向量化,支持向量检索和混合检索;而经济型模式仅基于关键词构建倒排索引,无法满足父子分块的运行要求。

实践指南:配置 Parent-child-HQ 知识库
要在 Dify 中使用该功能,首先需要安装 Parent-child-HQ 这个知识库处理流程模板。
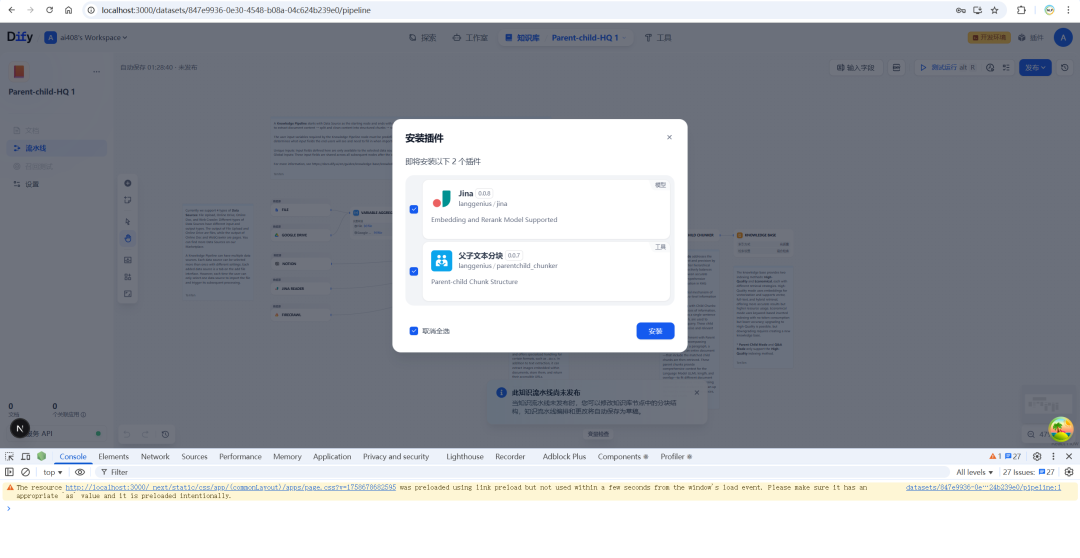
安装后,流水线中最核心的节点是“父子文本分块”。
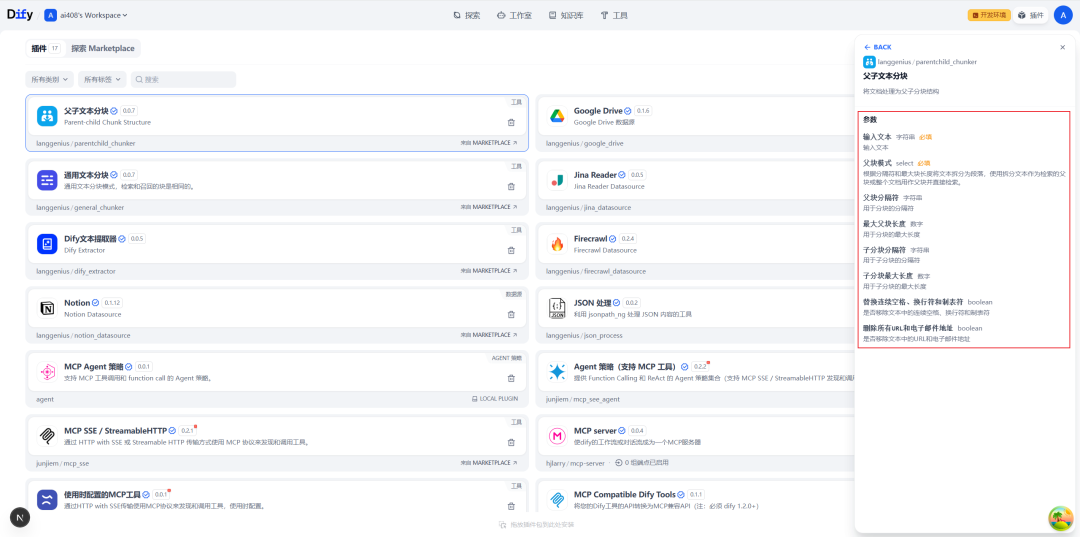
分块节点配置
在该节点的设置界面中,可以详细定义父块与子块的分割规则。
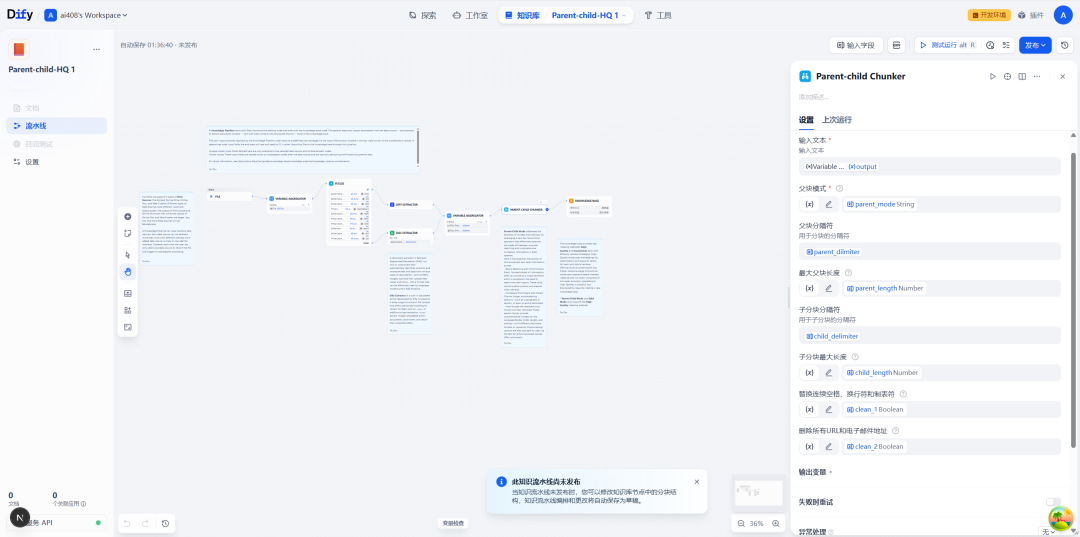
| 配置项 | 说明 |
|---|---|
| 父分块分隔符 | 定义如何切分出父块。通常使用 \n\n(两个换行符)来按段落分割。 |
| 父分块最大长度 | 单个父块的最大字符数限制。 |
| 子分块分隔符 | 定义在父块内部如何进一步切分子块。可使用 \n(单个换行符)按行分割。 |
| 子分块最大长度 | 单个子块的最大字符数限制。 |
| 父块模式 | 定义父块的范围,提供 paragraph(段落)和 full_doc(完整文档)两种模式。 |
其中,“父块模式”决定了上下文的宏观边界:
- 段落模式 (
paragraph mode):将文本按分隔符(如段落)拆分为多个父块。这是最常用的模式,在精度和上下文范围之间取得了很好的平衡。 - 整文模式 (
full_doc mode):将整个文档视为一个巨大的父块(超过 10,000 tokens 的部分将被截断)。该模式适用于需要全局上下文的特定场景。
此外,预处理选项还支持移除文本中的多余空格、URL 和电子邮件地址,以提升数据质量。
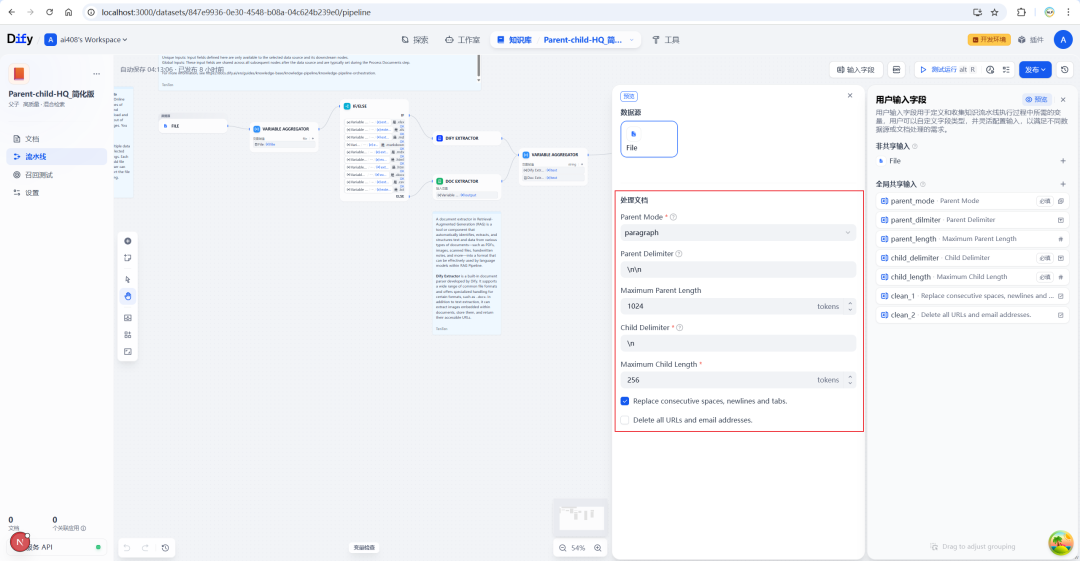
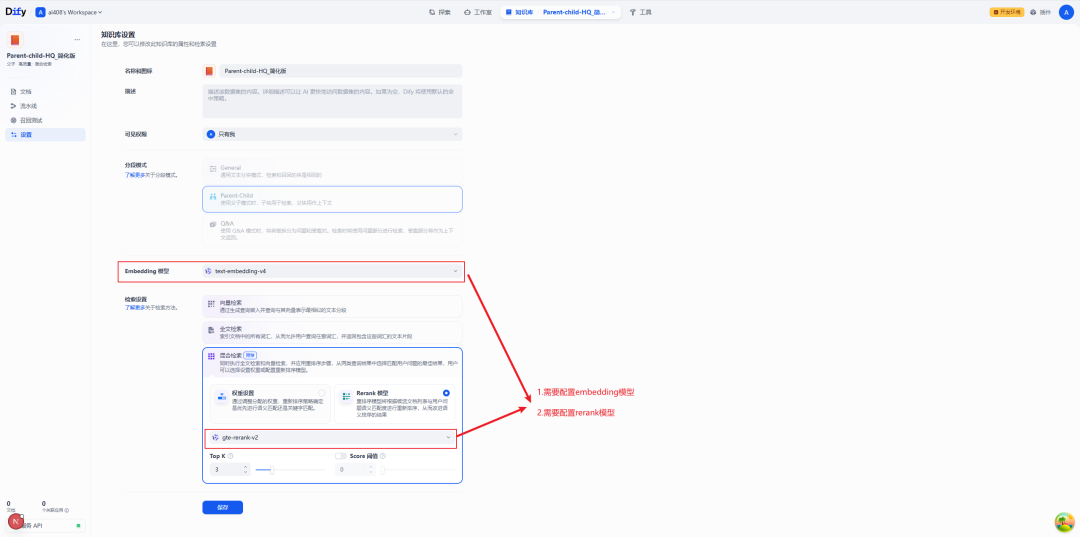
设置高质量索引
如前所述,Parent-Child 模式必须配合 HQ 索引使用。因此,需要在知识库的设置中配置好 Embedding 模型和 Rerank 模型。
调试与运行
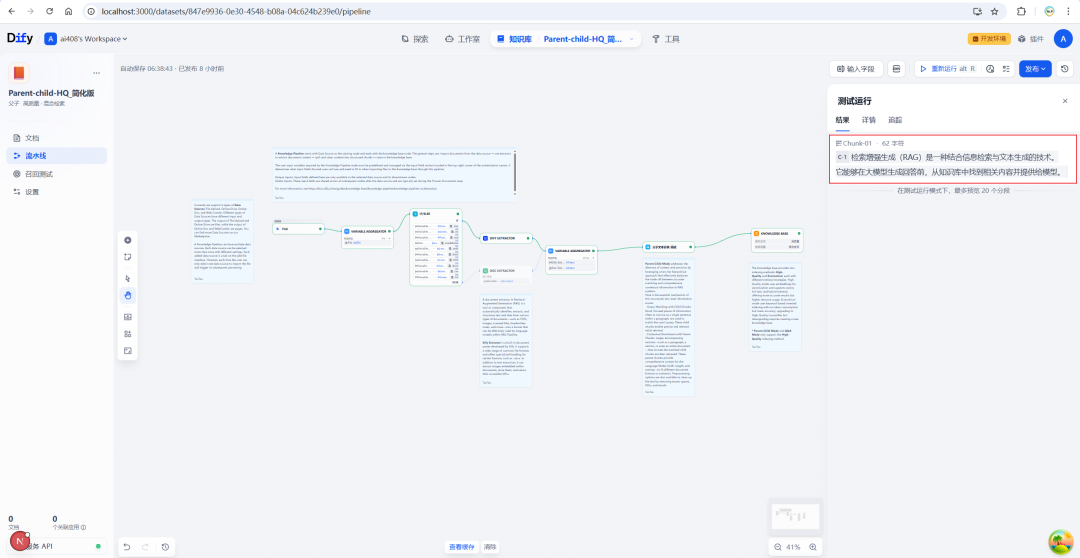
完成所有配置后,可以通过调试功能测试分块效果。输入示例文本,运行流水线,可以清晰地看到原始文本是如何被组织成父子结构的。
最终的运行结果会以结构化的形式展示父块及其包含的子块列表。
架构深潜:代码层面的实现逻辑
为了更好地理解其工作原理,我们深入 parentchild_chunker 插件的源码进行分析。下图的 UML 时序图概括了插件从启动、接收数据到处理并返回结果的完整流程。
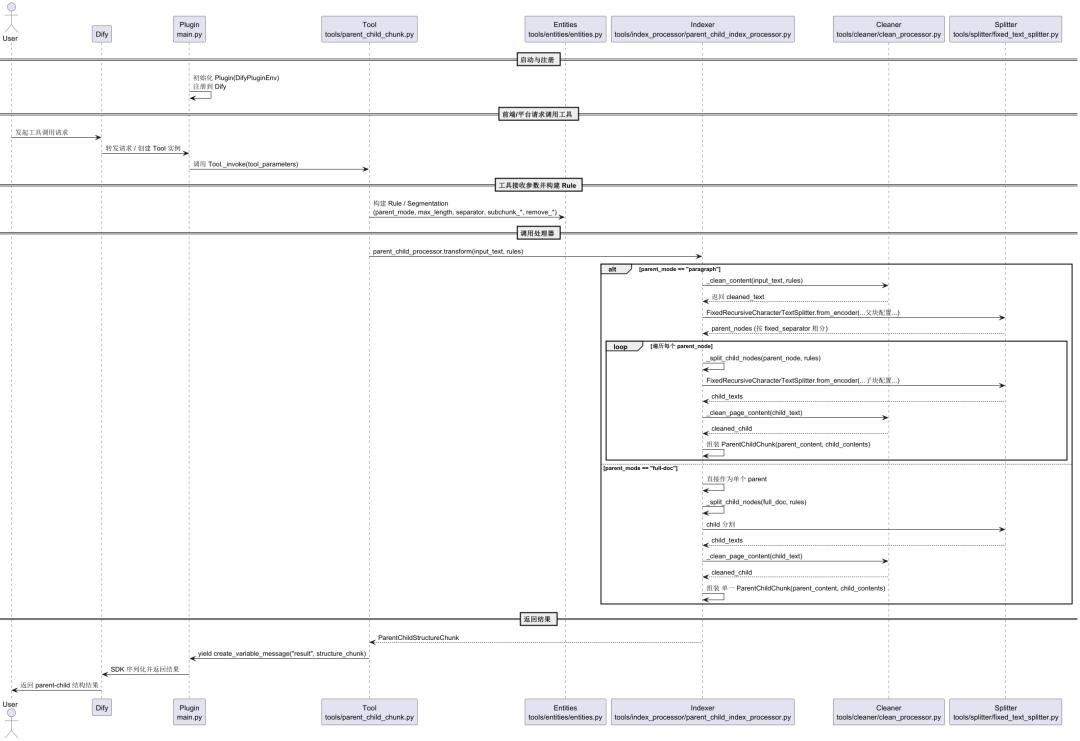
整个数据处理流程可以概括为以下几个关键步骤:
1. 插件启动与工具调用
当 Dify 平台启动时,main.py 文件作为插件入口,负责初始化并向 Dify 注册 ParentChildChunkTool 的能力。工具的前端表单、输入参数和输出格式由 tools/parent_child_chunk.yaml 文件定义。
当用户调用该工具时,Dify SDK 会实例化 tools/parent_child_chunk.py 中定义的 ParentChildChunkTool 类,并调用其 _invoke 方法,将前端传入的参数(如 input_text、parent_mode 等)传递进来。
2. 核心处理与文本清洗
_invoke 方法的核心职责是调用 tools/index_processor/parent_child_index_processor.py 中定义的 ParentChildIndexProcessor。这是整个业务逻辑的中枢。
在分块之前,文本会首先经过 tools/cleaner/clean_processor.py 中的 CleanProcessor 进行清洗。该模块负责移除无效字符,并根据用户配置选择性地合并多余空格或移除 URL 和邮件地址,保证后续处理的文本质量。
3. 智能文本分割
文本分割是父子分块策略的技术核心,主要由 tools/splitter/ 目录下的多个分割器实现。其中,FixedRecursiveCharacterTextSplitter 是关键。
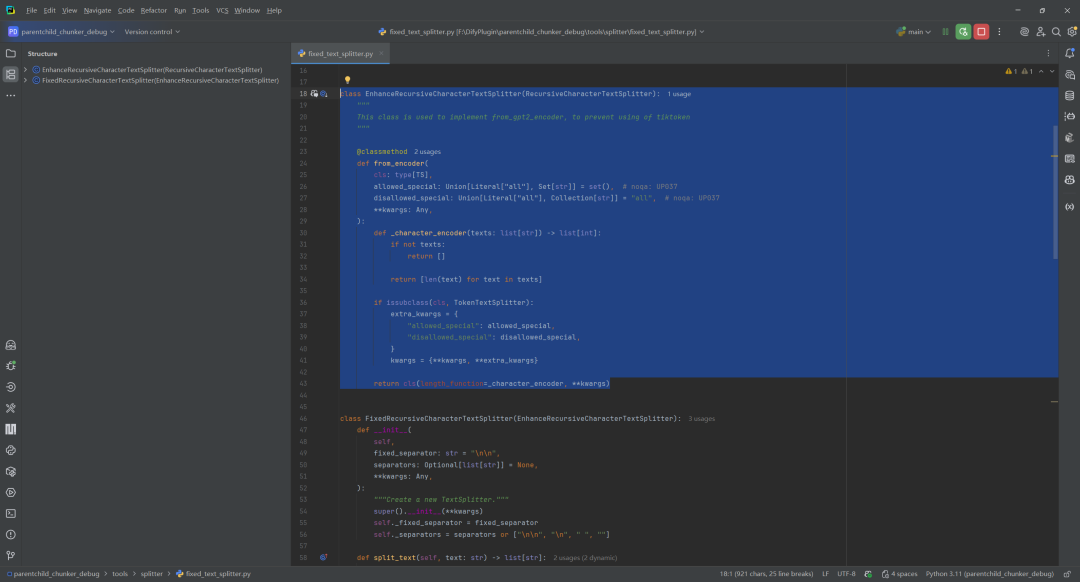
这里需要区分两个关键的类:
EnhanceRecursiveCharacterTextSplitter: 它的主要改进是提供了一种基于字符数(而非tiktoken)计算文本长度的方式,避免了对特定 tokenizer 的依赖。其分割逻辑与标准的递归字符分割器一致。FixedRecursiveCharacterTextSplitter: 该类在递归分割的基础上,增加了一个关键步骤——先使用一个固定的、高优先级的fixed_separator(例如代表段落的\n\n)进行初次分割。然后,仅对那些超出长度限制的块,再调用内部的递归逻辑进行细分。
这种“先粗分、后细化”的策略,完美匹配了父子分块的需求:首先通过 \n\n 划分出语义完整的父块(段落),然后再在父块内部使用更细的分割符(如 \n)切分出子块。
4. 数据结构构建与返回
经过清洗和分割后,ParentChildIndexProcessor 会根据 paragraph 或 full-doc 模式,将父块内容和其对应的子块内容列表组装成 ParentChildChunk 对象。这些对象最终被封装在 ParentChildStructureChunk 结构中。
这些数据结构的定义位于 tools/entities/entities.py,使用 Pydantic 模型确保了数据的规范性和一致性。
最后,ParentChildChunkTool 通过 yield self.create_variable_message(...) 将处理好的结构化数据返回给 Dify SDK,完成整个流水线节点的执行。
通过这种精心设计的处理流程和灵活的文本分割器,Parent-child-HQ 模板为开发者提供了一个强大而优雅的工具,有效解决了 RAG 应用中长期存在的上下文与精度权衡难题。





























