



DeepSeek-OCR 是由深度求索(DeepSeek-AI)公司开发并开源的一款光学字符识别(OCR)工具。 它提出了一个名为“上下文光学压缩”的新方法,从大语言模型(LLM)的角度来重新看待视觉编码器的角色。 这个工具不是简单地识别图片中的文字,而是先将文档页面这样的长文本内容渲染成图像,再将图像压缩成一组数量较少的“视觉令牌”(vision tokens)。 然后,语言模型解码器从这些视觉令牌中重建出原始文本。这种方式能够将输入令牌的数量减少7到20倍,从而让大模型能用更少的计算资源处理超长文档,提高了处理效率和速度。 该项目遵循MIT开源许可协议。
功能列表
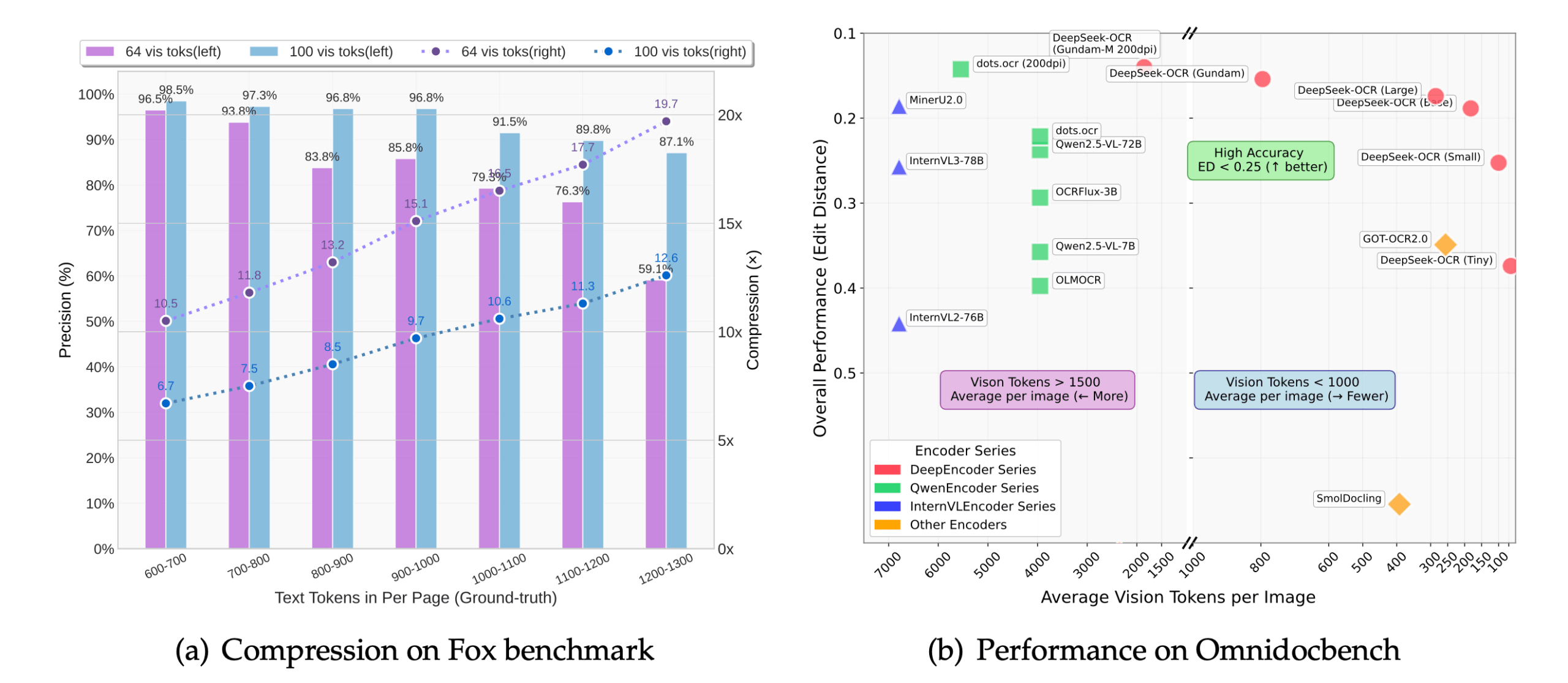
- 上下文光学压缩:通过将图像压缩成视觉令牌,大幅减少模型处理的数据量,降低了内存使用并提升了推理速度。
- 高精度识别:在10倍压缩率下,依然可以达到97%左右的识别准确率,能够保留文档的布局、排版和空间关系。
- 结构化输出:能够将文档,特别是包含复杂布局(如表格、列表、标题)的页面,直接转换为Markdown格式,保留了原文的结构。
- 多种任务支持:通过修改输入提示词(Prompt),模型可以执行不同的任务,例如:
- 将整个文档转换为Markdown。
- 对图片进行通用OCR识别。
- 解析文档中的图表。
- 详细描述图片内容。
- 多种分辨率模式:支持从512×512到1280×1280的多种固定分辨率,以及一个动态分辨率模式,用于处理超高分辨率的文档。
- 高性能推理:集成了vLLM和Transformers框架,在A100-40G的GPU上处理PDF文件时,速度可达约2500 tokens/秒。
- 手写体识别:在光照和分辨率良好的情况下,对手写内容的识别效果优于许多传统OCR工具。
使用帮助
DeepSeek-OCR的安装和使用主要面向开发者,需要一定的编程基础。以下是详细的操作流程,主要分为环境配置、安装和代码推理三个部分。
第一步:环境准备
官方推荐的环境为CUDA 11.8以及PyTorch 2.6.0。 开始之前,你需要安装Git和Conda。
- 克隆项目仓库
首先,从GitHub上克隆DeepSeek-OCR的官方代码库到你的本地电脑。打开终端(命令行工具),输入以下命令:git clone https://github.com/deepseek-ai/DeepSeek-OCR.git执行后,会在当前目录下创建一个名为
DeepSeek-OCR的文件夹。 - 创建并激活Conda环境
为了避免与你电脑上其他Python项目产生依赖冲突,建议创建一个独立的Conda虚拟环境。# 创建一个名为deepseek-ocr的Python 3.12.9环境 conda create -n deepseek-ocr python=3.12.9 -y # 激活这个新创建的环境 conda activate deepseek-ocr激活成功后,你的终端提示符前面会出现
(deepseek-ocr)字样。
第二步:安装依赖
在激活的Conda环境中,需要安装模型运行所需的Python库。
- 安装PyTorch
根据官方要求,安装适配CUDA 11.8的PyTorch版本。pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118 - 安装其他核心依赖
项目依赖vLLM库进行高性能推理,同时需要安装requirements.txt文件中列出的其他包。# 进入项目文件夹 cd DeepSeek-OCR # 安装vLLM(注意:官方提供了编译好的whl文件链接,也可以自行编译) # 示例是下载官方提供的whl文件进行安装 pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl # 安装requirements.txt中的所有依赖 pip install -r requirements.txt - 安装Flash Attention(可选但推荐)
为了获得最佳的运行速度,推荐安装Flash Attention库。pip install flash-attn==2.7.3 --no-build-isolation注意: 如果你的GPU不支持或安装失败,也可以不安装此库。后续在代码中需要移除
_attn_implementation='flash_attention_2'这个参数,模型虽然可以运行,但速度会慢一些。
第三步:运行推理代码
DeepSeek-OCR提供了两种主流的推理方式:基于Transformers库的单次推理和基于vLLM的高性能批量推理。
方式一:使用Transformers进行快速推理(适合单张图片测试)
这种方式代码简单,非常适合快速测试模型效果。
- 创建一个Python文件,例如
test_ocr.py。 - 将以下代码复制到文件中。这段代码会加载模型,并对一张指定的图片进行OCR识别。
import torch from transformers import AutoModel, AutoTokenizer import os # 指定使用的GPU,'0'代表第一张卡 os.environ["CUDA_VISIBLE_DEVICES"] = '0' # 模型名称 model_name = 'deepseek-ai/DeepSeek-OCR' # 加载分词器和模型 tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) # 加载模型,使用flash_attention_2加速,并设置为半精度(bfloat16)以节省显存 model = AutoModel.from_pretrained( model_name, trust_remote_code=True, _attn_implementation='flash_attention_2', use_safetensors=True ).eval().cuda().to(torch.bfloat16) # 定义输入的图片路径和输出路径 image_file = 'your_image.jpg' # <-- 将这里替换成你的图片路径 output_path = 'your/output/dir' # <-- 将这里替换成你的输出文件夹路径 # 定义提示词,引导模型执行特定任务 # 这个提示词告诉模型将文档转换为Markdown格式 prompt = "<image>\n<|grounding|>Convert the document to markdown. " # 执行推理 res = model.infer( tokenizer, prompt=prompt, image_file=image_file, output_path=output_path, base_size=1024, image_size=640, crop_mode=True, save_results=True, test_compress=True ) print(res) - 运行代码
将一张需要识别的图片(例如your_image.jpg)放到与脚本相同的目录下,然后执行:python test_ocr.py程序运行结束后,识别出的文本会打印在终端,同时结果会保存在你指定的输出路径中。
方式二:使用vLLM进行批量推理(适合处理大量图片或PDF)
vLLM模式性能更强,适合生产环境。
- 配置文件修改
进入DeepSeek-OCR-master/DeepSeek-OCR-vllm目录,打开config.py文件,修改其中的输入路径(INPUT_PATH)和输出路径(OUTPUT_PATH)等设置。 - 执行脚本
该目录下提供了针对不同任务的脚本:- 处理流式图片数据:
python run_dpsk_ocr_image.py - 处理PDF文件:
python run_dpsk_ocr_pdf.py - 运行基准测试:
python run_dpsk_ocr_eval_batch.py
- 处理流式图片数据:
应用场景
- 文档数字化
将纸质书籍、合同、报告等扫描成图片后,使用DeepSeek-OCR可以快速将其转换为可编辑、可搜索的电子文本,并且能很好地保留原始的标题、列表和表格结构。 - 信息提取
从发票、收据、表单等图片中自动提取关键信息,例如金额、日期、项目名称等,实现自动化数据录入,减少人工操作。 - 教育和研究
研究人员可以利用此工具快速识别和转换论文、古籍、档案等文献资料中的文本内容,便于后续进行数据分析和内容检索。 - 无障碍应用
通过识别图片中的文字并生成详细描述,可以帮助视力障碍用户理解图像内容,例如读取菜单、路牌或产品说明书。
QA
- DeepSeek-OCR是免费的吗?
是的,DeepSeek-OCR是一个开源项目,遵循MIT许可证,用户可以免费使用、修改和分发。 - 它支持哪些语言?
该模型主要展示了其在处理英文和中文文档上的强大能力。由于其基于大语言模型,理论上具备多语言处理潜力,但具体效果需要根据实际测试来评估。 - 处理PDF文件的原理是什么?
DeepSeek-OCR本身处理的是图像。当输入PDF文件时,程序会先将PDF的每一页渲染(转换)成一张图片,然后逐页对这些图片进行OCR识别,最后将所有页面的结果合并输出。 - 没有NVIDIA的GPU可以使用吗?
官方文档和教程都基于NVIDIA GPU和CUDA环境。 虽然理论上模型可以在CPU上运行,但速度会非常慢,不适合实际应用。因此,强烈建议在配备NVIDIA GPU的设备上使用。 - “上下文光学压缩”有什么好处?
主要好处是效率。传统模型处理长文本时,计算量和内存占用会随着文本长度急剧增加。通过将文本图像压缩成少量视觉令牌,DeepSeek-OCR可以用更少的资源处理同样甚至更长的内容,使得在有限的硬件上处理大规模文档成为可能。































