


书写是人类历史的基石,而铭文作为最早的书写形式之一,为我们提供了洞察古代文明的直接窗口。从皇帝的法令、阵亡士兵的墓志铭,到日常的商业交易和墙壁涂鸦,这些刻在石头、金属或陶器上的文字,是罗马帝国日常生活的快照。 [1, 2] 然而,由于风化、破损和人为破坏,大量的铭文变得残缺不全,给历史学家的解读工作带来了巨大挑战。
传统的数字化方法通常停留在文字匹配层面,难以应对破损文本修复、断代和地理归属等需要复杂推理的任务。历史学家必须依赖个人经验,在浩如烟海的文献中进行耗时的比对。
为了解决这一难题,Google DeepMind 与诺丁汉大学等机构的研究团队推出了一个名为 Aeneas 的多模态生成式 AI 模型。该模型发表在《自然》期刊上,旨在协助历史学家处理公元前 7 世纪至公元 8 世纪的拉丁铭文。 [1]

Aeneas 如何修复历史的碎片
每年大约有 1500 条新的拉丁铭文被发现,但解读工作充满困难。 [1] 文本的缺失部分长度和内容都未知,这使得修复工作如同大海捞针。
Aeneas 的设计思路正是为了应对这一挑战。它是一个多模态模型,能够同时分析铭文的图像和转录文本,这在同类工具中尚属首次。 [2]
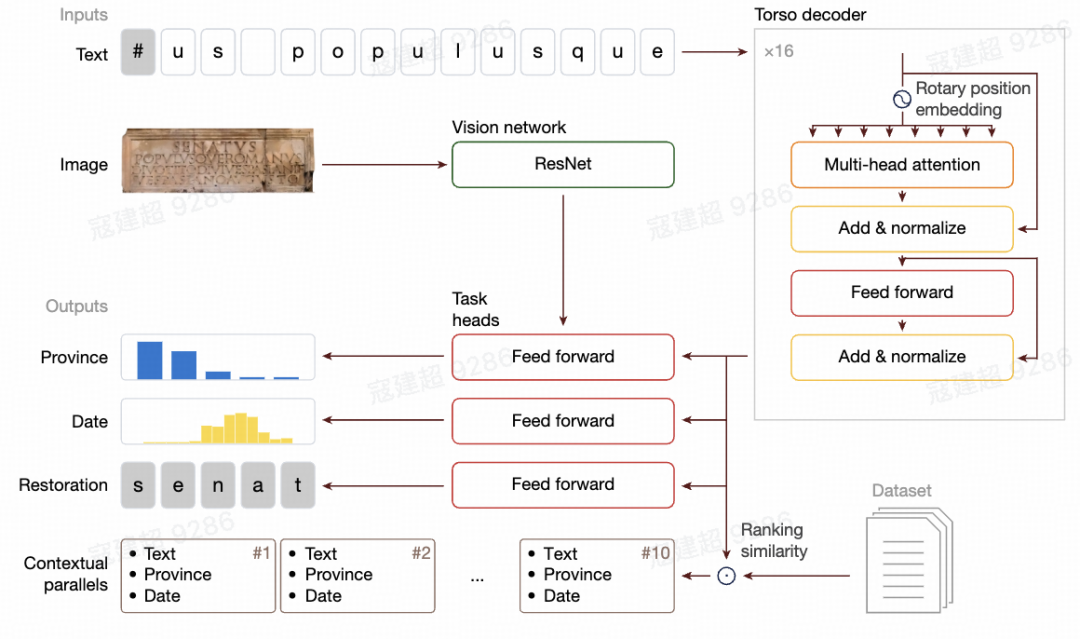
其核心能力体现在以下几个方面:
- 未知长度的文本修复:相较于其前辈——专注于古希腊语的
Ithaca模型,Aeneas最大的突破之一是能够修复未知长度的文本缺口。 [4, 5] 这对于处理严重受损的铭文至关重要。例如,面对一块残破的军事文书,Aeneas可以提出高概率的修复建议,而无需事先知道缺失了多少个字符。 - 上下文平行检索:模型能够迅速在其训练数据库(涵盖超过 17.6 万条拉丁铭文)中检索出与待研究铭文在内容、风格或来源上相似的“平行文本”。 [2, 3] 这极大地缩短了历史学家原本需要数周甚至数月才能完成的比对工作。
- 多模态分析:通过结合文本和图像信息,
Aeneas在判断铭文的地理来源方面表现优于纯文本模型。石材的类型、雕刻的风格等视觉线索,为模型的判断提供了额外依据。 [2]

人机协作:1+1>2 的实证
为了检验 Aeneas 的实战效果,研究团队进行了一项人机协作实验。实验邀请了 23 位不同水平的铭文专家与 Aeneas 互动。
结果相当惊人:
- 断代精度:
Aeneas对铭文年代的预测平均误差仅为 13 年,中位误差为 0 年,几乎与历史学家给出的范围完全一致。 [4] - 协作效率:在
Aeneas的辅助下,历史学家在文本修复和地理归属等任务上的表现,均超过了人类或 AI 单独工作时的水平。在 90% 的案例中,历史学家认为Aeneas提供的平行文本是极具价值的研究起点。 [5]
这些数据表明,Aeneas 并非要取代历史学家,而是要成为一个强大的“研究伙伴”,将专家从繁琐的数据比对中解放出来,专注于更高层次的分析与解读。

AI 在人文学科的未来
Aeneas 的出现,标志着 AI 在人文学科的应用进入了一个新阶段。它不仅仅是一个检索工具,更是一个能够生成假设、模拟专家分析过程的“思考”工具。
当然,模型也存在局限性。目前,能够匹配到高质量图像的铭文数据仅占 5%,这限制了其多模态能力的充分发挥。 [5] 此外,如何更好地处理历史年代的不确定性(例如,一个跨度很大的时间范围),也是未来需要改进的方向。
尽管如此,Aeneas 的应用潜力远不止于拉丁铭文。其架构可以适配任何古代语言和书写媒介,无论是莎草纸、手稿还是古代钱币。 [2] 这为考古学、古典学乃至更广泛的人文研究领域,都带来了新的可能性。
这类工具的出现,正在促使研究者反思自身的工作方式。当 AI 能够高效处理海量、破碎的信息时,历史学家的核心价值将更多地体现在提出正确的问题、解释复杂的历史因果链,以及进行具有思辨性的批判分析上。 Aeneas 的意义,或许不在于它给出了多少答案,而在于它能激发学者们提出多少新的问题。
































