

近日,AI 应用“问小白”宣布推出其自研的新一代原生 Agent 大模型 O3,并已开放部分用户进行内测。据官方介绍,O3 的核心特性在于其深度推理与多轮验证能力,旨在解决当前大语言模型普遍存在的“AI幻觉”、信息碎片化和答案获取效率低下的问题。

与传统单轮问答式 AI 不同,O3 的工作流更像一个自动化研究员。当接收到用户任务后,它会自主进行推理分析,规划信息检索路径,并通过多轮网络搜索来获取和验证数据。在必要时,模型还会调用不同工具进行交叉比对,最终生成一份整合了文本、图表和图片的综合性报告。
痛点:AI为何常常答非所问?
当前主流大模型在处理复杂问题时,用户常面临以下困境:
- 答案支离破碎:模型返回的信息不完整,用户需要通过多次追问才能拼凑出全貌。
- 信息可信度低:由于依赖单次搜索或固化知识库,模型容易产生事实性错误,即“AI幻觉”。
- 内容缺乏深度:生成的回答往往停留在信息罗列,缺乏结构化的深度分析。
- 表达生硬机械:回答语言模式化,带有明显的“AI味”,缺少自然感。
O3 模型的设计初衷正是为了应对这些挑战。
O3 的核心能力:从“搜索”到“研究”
O3 通过引入 Agent 工作流,在四个核心方面展现出其差异化优势。
- 精准可信:内置多轮验证机制
传统模型常因单次搜索而遗漏关键信息,而 O3 采用“思考-搜索-验证”的循环工作模式。它会自动查询多个可信数据源,进行交叉验证,从而提升答案的准确性。
案例对比
- 任务:“小米手机2024年Q1销量”
- 传统 AI:可能需要用户追问“具体数据是多少?”、“同比增长了多少?”、“主要增长来自哪个市场?”。
- O3:直接生成一份包含关键数据的微型报告,指出其出货量为4080万台(引用 IDC 数据),同比增长12.3%,并点明东南亚市场是主要增长贡献区。
- 深度高效:生成研报级分析内容
针对需要深度分析的复杂问题,O3 能够在短时间内输出结构清晰、信息饱和的答案,内容覆盖宏观趋势、细分要点和未来展望,避免了信息的碎片化。
案例对比
- 任务:“欧盟2030碳关税应对策略”
- 传统 AI:可能仅罗列政策条文,需要用户进一步提问以获取行业影响和实施细节。
- O3:可输出一份完整的策略框架,包括战略路径、行业影响矩阵分析以及实施时间线。
- 自然生动:优化语言与叙事风格
O3 在语言生成上进行了特别优化,通过引入类比、情感和叙事节奏,使其输出的文本更接近人类作家的写作风格,尤其在处理长文本创作任务时,效果更为明显。
案例对比
- 任务:“写一部关于冥王星外神秘行星的8000字科幻小说”
- 传统 AI:往往只能分段输出,故事连贯性差,语言风格单一。
- O3:能够生成包含完整世界观设定、情节发展和科学细节的统一故事文本。
- 图文联动:智能适配呈现方式
根据问题类型,O3 会智能选择最适合的展示方式,灵活运用图片、表格、饼图等可视化工具,帮助用户快速抓住信息重点。
案例对比
- 任务:“4人4000块预算的暑假行程规划”
- 传统 AI:可能仅输出文字形式的景点列表。
- O3:倾向于生成图文并茂的方案,例如包含景点照片、格式化的行程表以及预算分配饼图。
技术解析:O3 如何实现自主“思考”?
根据“问小白”技术团队的介绍,O3 的实现主要依赖两大核心技术:基于知识图谱的 Agentic 任务合成和端到端的 Agent 强化学习。
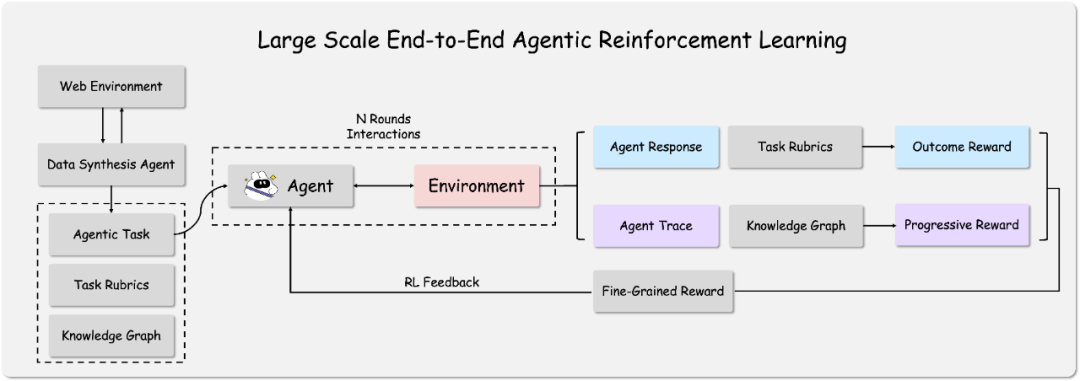
其技术路径可以理解为两个阶段:
- 任务生成与规划:在模型训练前,一个“数据合成 Agent”会通过与网络环境的交互来构建知识图谱。基于这些知识图谱,系统能生成一系列复杂的、需要多步推理和工具调用的“代理任务”,并为这些任务设定精细的评分标准。这确保了模型在训练阶段接触到的任务足够复杂且贴近真实世界。
- 强化学习与优化:在训练中,
O3Agent 会自由地与环境交互,尝试解决任务并记录其行为轨迹。完成任务后,系统会使用预设的评分标准和知识图谱来评估其答案质量与信息获取的完整度。评估分数将作为奖励信号,通过强化学习(RL)来优化 Agent 的行为策略,使其学会如何根据不同任务高效地调整搜索策略、调用工具并最终解决问题。
这种端到端的强化学习方式,是当前业界探索解决 AI 可靠性和自主性问题的关键方向之一。
应用场景与体验入口
O3 的能力使其可以应用于多种场景,例如为职场人提供行业研究、为创业者提供市场分析,或成为内容创作者的协作伙伴。
目前,O3 模型正在内测阶段,用户可通过“问小白”的网页版或 App 查看自己是否获得体验资格。
网页端
手机端
随着 O3 这样原生 Agent 大模型的出现,AI 正在从一个被动的“问答机器”向一个主动的“任务解决者”进化。虽然目前仍处于早期阶段,但这种技术路径无疑为解决当前 AI 应用的诸多瓶颈提供了有价值的探索。






































