

随着 wan2.1 等视频模型的出现,本地化视频生成的技术生态正逐步走向成熟。以往,高性能硬件是搭建视频工作流的主要障碍,但随着云端计算资源的普及和模型优化技术的发展,现在即便是没有顶级显卡的用户,也能够通过租用云端 4090 显卡等方式,深入学习和探索 wan2.1 视频工作流。
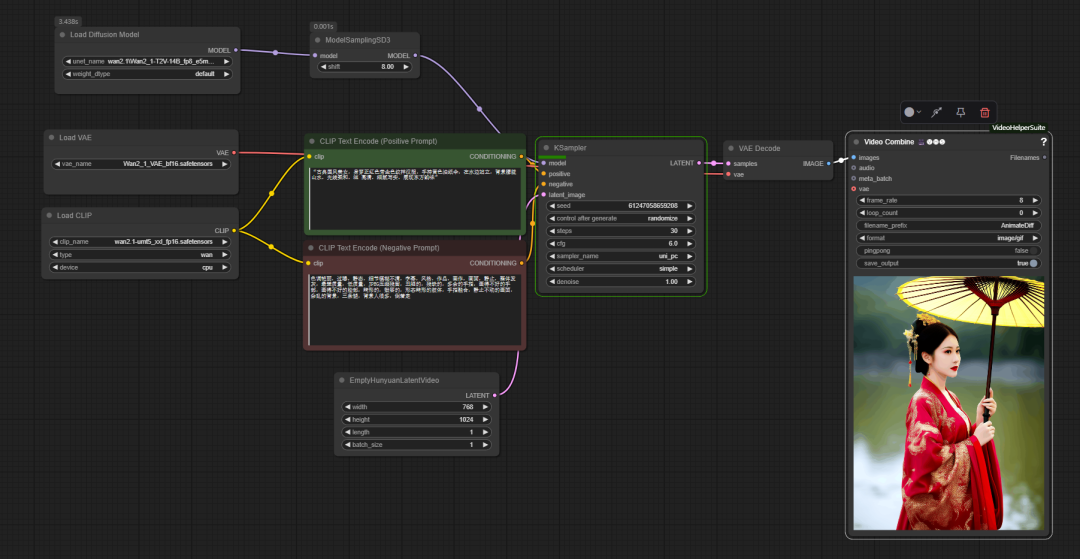
在 ComfyUI 的官方基础工作流中,wan2.1 的使用与传统文生图流程相似,但增加了一个关键节点 model sampling sd3。该节点用于调整 UNet 的“内部位移” (internal shift) 时间步位置,其默认推荐值为 8。这个参数能够影响模型对提示词的理解和控制力,从而优化生成画面的细节。
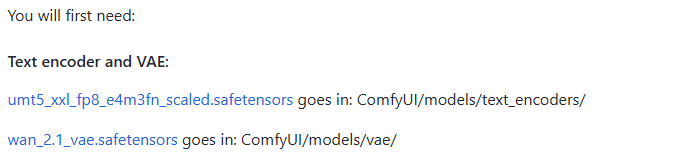
要运行 wan2.1 模型,必须配备对应的 unmt5 文本编码器和 wan2.1 VAE (变分自编码器)。VAE 由编码器 (Encoder) 和解码器 (Decoder) 两部分组成。编码器负责将输入图像压缩到低维的潜在空间,而解码器则从潜在空间中采样并将其还原为图像。
文本编码器 (Text Encoder) 的作用则是将输入的文本提示词,转化为模型能够理解的特征向量。这个过程主要包括两个步骤:
- 提取文本的语义信息特征,例如“1个女孩”。
- 将这些语义信息转化为高维的嵌入向量 (embedding vector)。
生成模型 (如 UNet) 依据这些嵌入向量,在潜在空间中生成符合文本描述的图像特征,从而决定画面中物体的种类、位置、颜色和姿态。
与静态的文生图工作流不同,视频生成流程的最后一步是 Video Combine (视频合成) 节点。
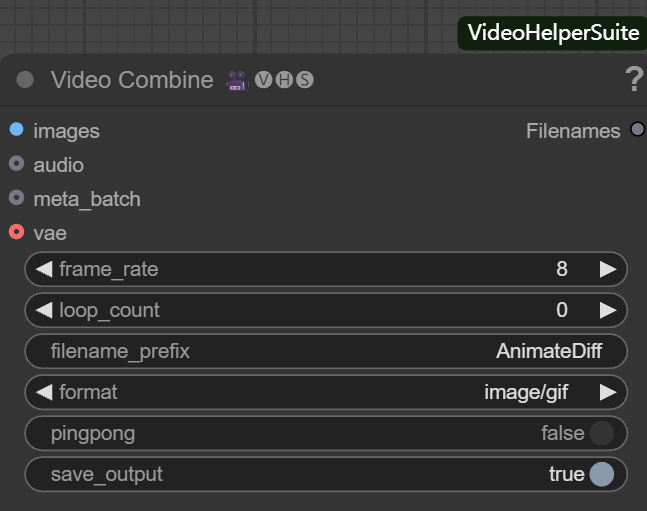
该节点负责将图像序列整合成视频或动图文件。其主要参数包括:
- frame_rate (帧率): 决定视频播放的流畅度,例如设置为
8,表示每秒播放 8 帧。 - loop_count (循环次数):
0代表无限循环,适用于 GIF 动图;1则代表播放一次后停止。 - filename_prefix (文件名前缀): 为输出文件设定前缀,如
AnimateDiff,便于管理。 - format (输出格式): 可选择
image/gif输出动图,或video/mp4等视频格式。 - pingpong (往返循环):
false为常规顺序播放,true则实现从头到尾再到头的往返播放。 - save_output (保存输出): 设置为
true时,执行节点后会自动保存文件。
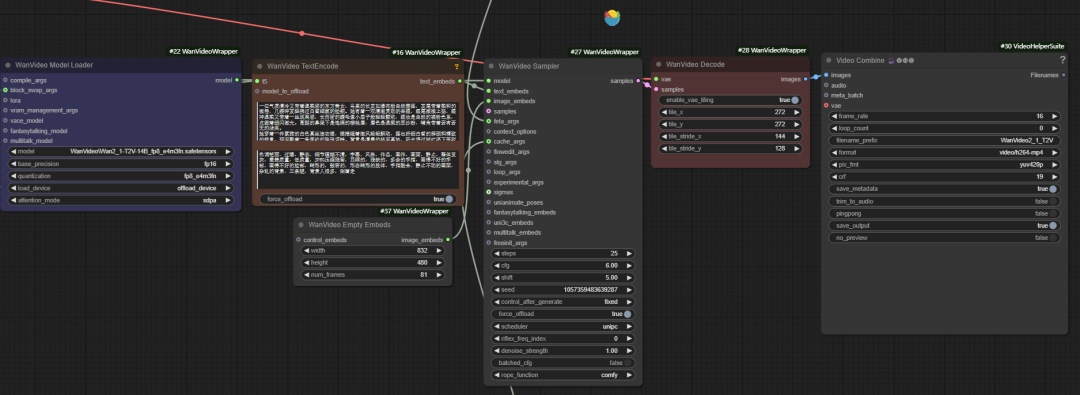
官方工作流仅实现了基础功能,在显存优化、视频增强等方面存在局限。为此,开发者“K神”创建了 wanvideo wrapper 工具包,提供了一系列优化节点。
优化的核心:wanvideo wrapper
wanvideo model loader
wanvideo model loader 是一个功能强大的模型加载节点,它不仅可以加载 wanvideo 模型,还提供了丰富的优化选项。
- 模型精度 (Base Precision): 用户可以选择不同的模型精度,如
fp32、bf16、fp16。fp32(32位浮点数) 精度最高,但显存占用和计算开销最大;fp16(16位浮点数) 则能显著降低显存占用并提升速度,但可能牺牲部分精度。 - 量化 (Quantization): 通过
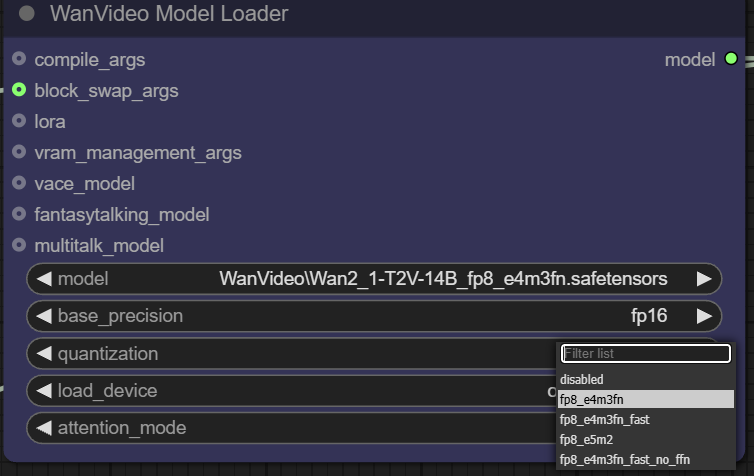
quantization选项,可以将模型量化以进一步压缩。例如,fp8_e4m3fn格式使用8位浮点数表示,极大地降低了显存需求,尤其适合显存有限的设备,但通常需要模型预先支持量化。
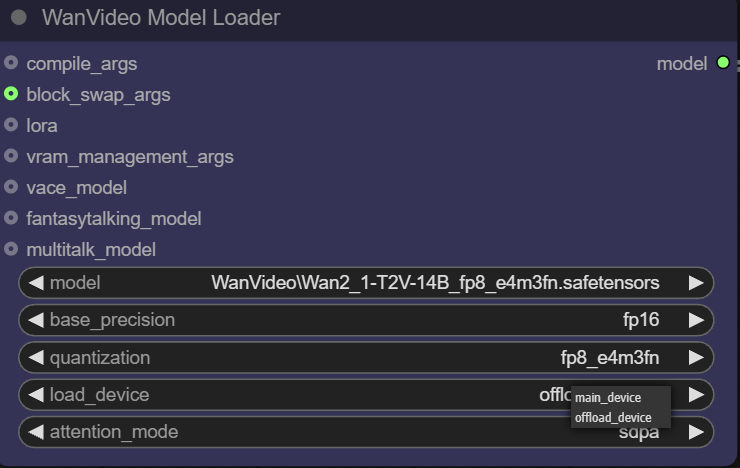
- 设备加载 (Load Device):
main device通常指代 GPU,而offload device指代 CPU。此功能允许将模型部分组件卸载到 CPU,以节约宝贵的显存资源。
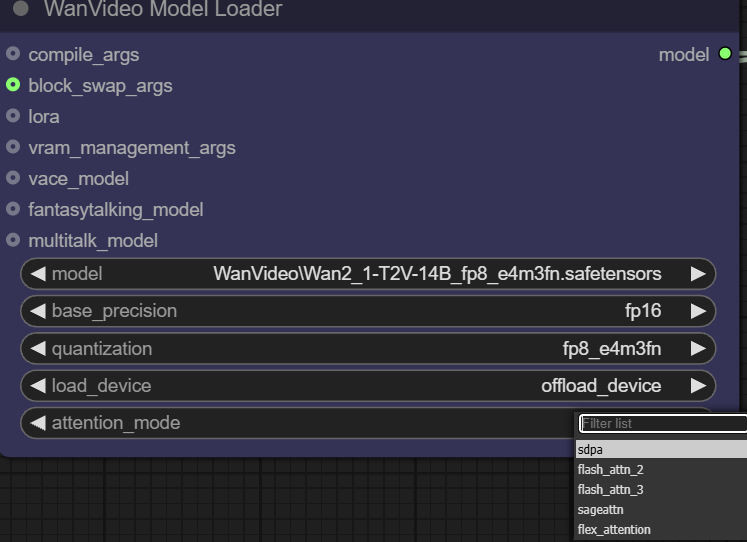
- 注意力机制 (Attention Mode): 此选项允许用户选择不同的注意力机制实现方式,以平衡性能和显存。注意力机制是Transformer模型的核心,它决定了模型在生成内容时如何“关注”输入信息的相关部分。
该加载器还提供了多个输入接口用于高级优化:
- 编译参数 (compile args): 此接口可用于配置
torch.compile或xformers等编译优化。xformers是一个专门用于优化 Transformer 计算的库,而torch.compile是 PyTorch 2.0 引入的即时编译器。如果环境中安装了Triton编译器,可以获得约30%的速度提升。
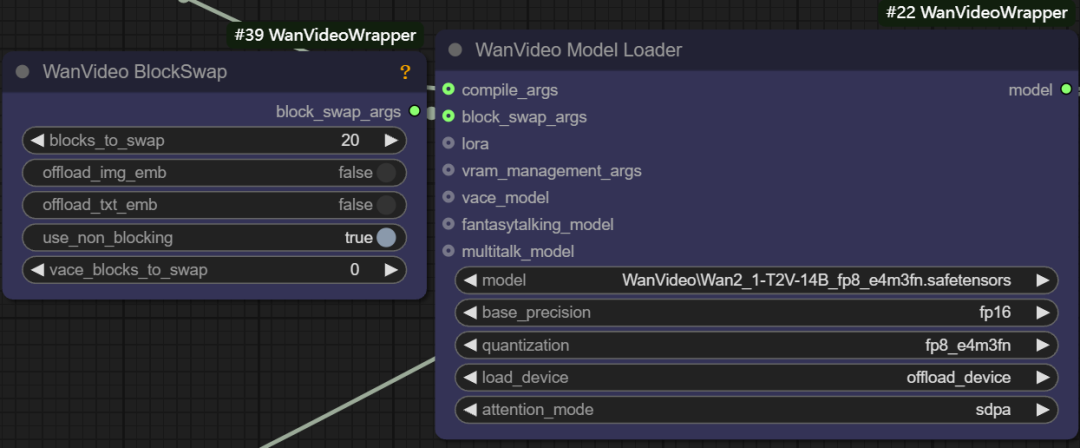
- 块交换参数 (block swap args): 当显存不足以容纳整个模型时,此功能允许将模型的部分“块” (blocks) 暂存到 CPU。例如,设置
blocks to swap为20,意味着将模型的20个块移出GPU,在需要时再通过非阻塞方式传回。转移的块越多,显存节省越明显,但数据来回传输会牺牲一定的生成速度。
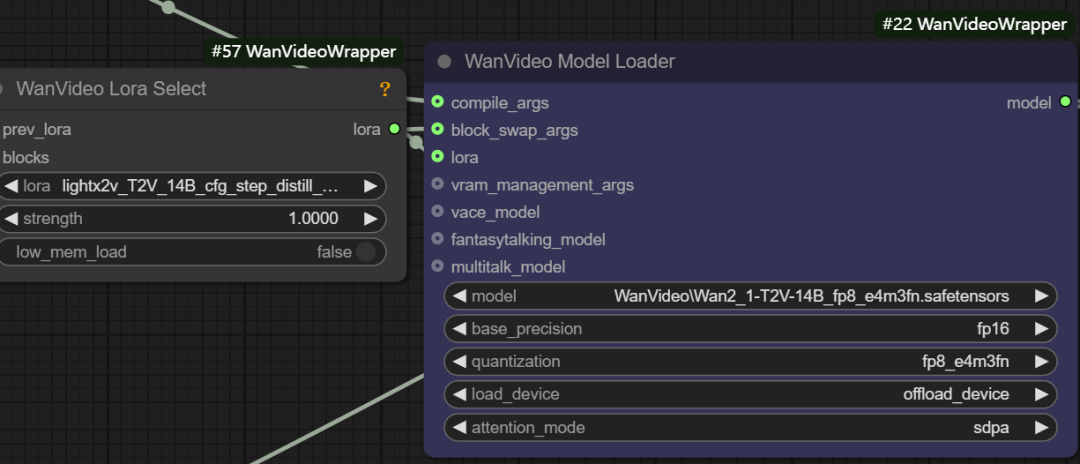
- LoRA 加载: 此接口可连接
wanvideo lora select节点,用于加载各类 LoRA 模型,例如用于加速文生视频的light x2v t2vLoRA。
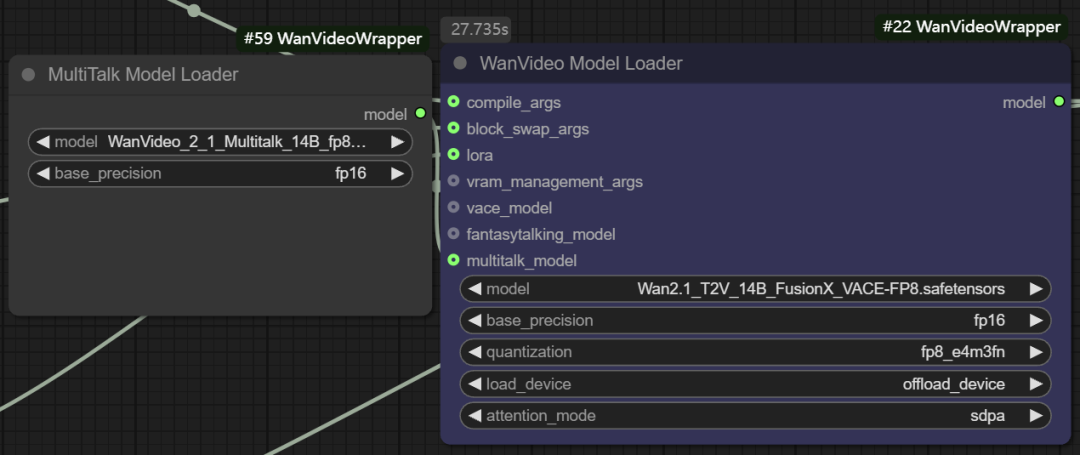
- Multitalk 功能模型: 该节点还支持加载
Multitalk、Fantasytalking等数字人模型,这些都是由开发者整合进wanvideo wrapper的新兴开源项目。
wanvideo sampler
wanvideo sampler 是基于 wan2.1 模型定制的视频采样节点,是生成视频序列帧的核心。
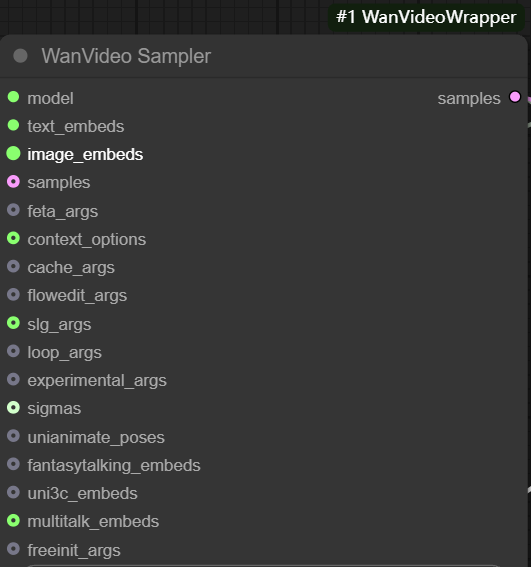
其主要输入包括:
- model: 连接来自
wanvideo model loader的模型。 - text embeds (文本嵌入): 连接
wanvideo text encode的输出,将使用unmt5编码的文本向量传入。
- image embeds (图像嵌入): 用于实现图像到视频的生成。该工作流通常先用
wanvideo clipvision encode提取参考图的CLIP特征,再通过wanvideo image to video encode节点利用 VAE 将图像特征编码为模型可用的向量表示。
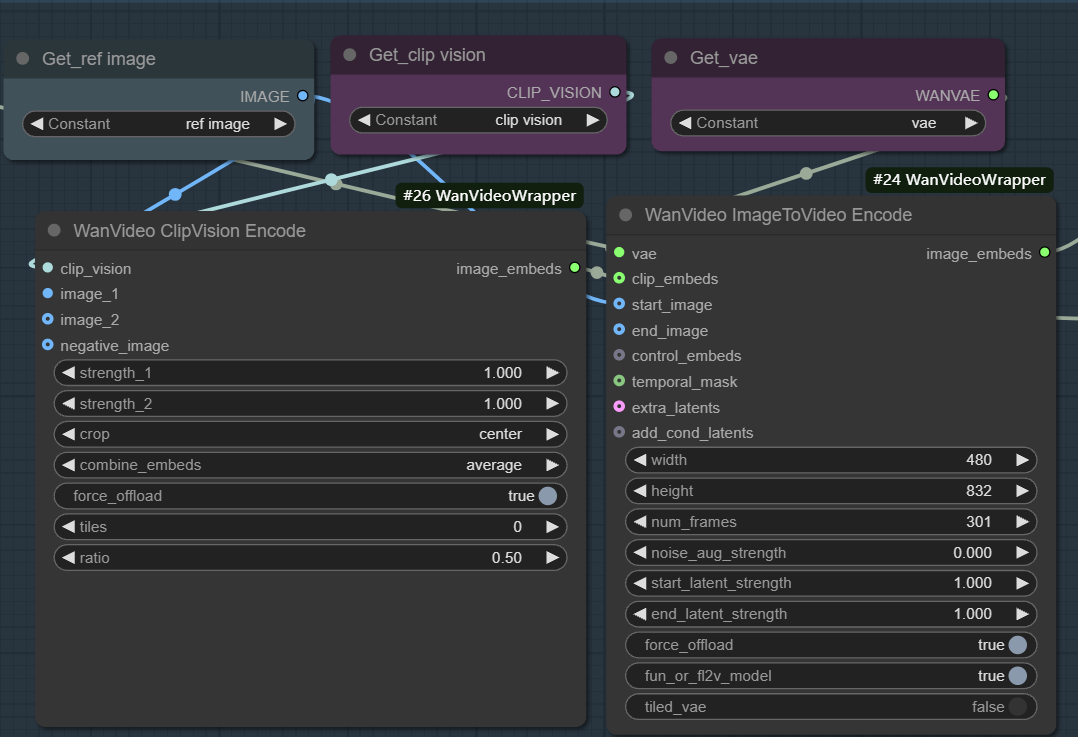
这个过程的本质是,首先将静态图像的视觉和语义信息转化为特征向量,然后采样器将这些特征作为引导条件,从噪声开始迭代去噪,最终生成内容和风格与参考图一致的连续视频帧。通过调整权重、噪声和帧数等参数,可以精确控制参考图的影响力以及视频的多样性。
- samples: 此输入端理论上可以接收上一阶段的采样结果,作为扩散迭代的起点,但其
latent格式与标准文生图的latent不兼容。 - feta args: 用于连接视频增强节点,提升视频细节、帧对齐和时序稳定性。
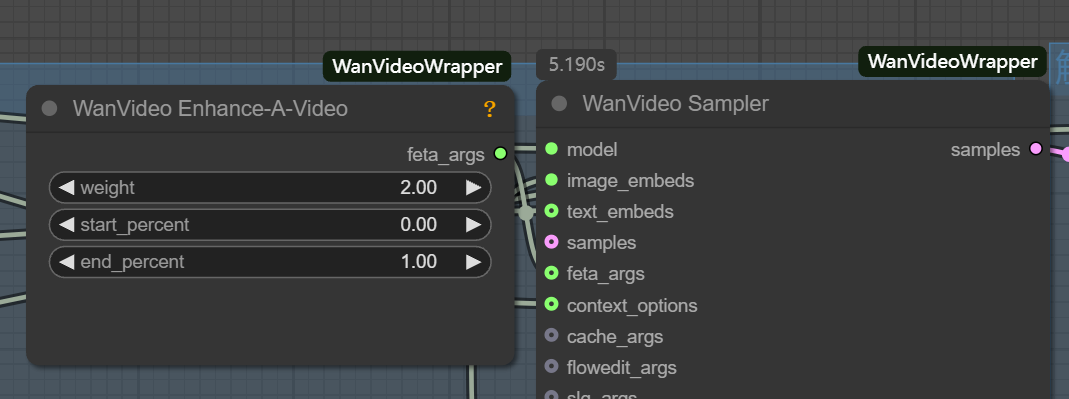
- wanvideo context options: 这是确保视频帧间连贯性的关键控制器。它通过控制模型在生成当前帧时参考上下文信息的方式,解决了独立帧生成导致的画面断层和动作不自然的问题。
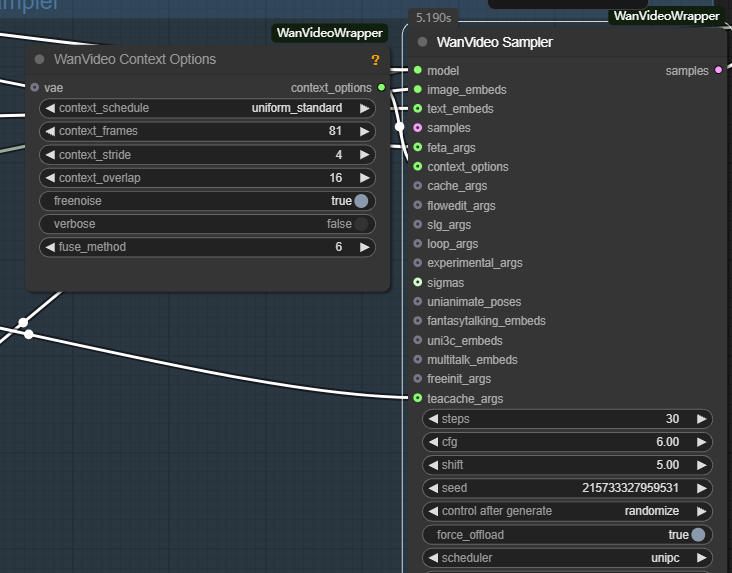
主要参数如下:
- context_frames (上下文帧数): 定义模型一次性参考的相邻帧数量。数值越大,运动和场景变化的连贯性越好,但计算量也相应增加。
- context_stride (上下文步长): 控制采样参考帧的间隔。步长越小,参考越密集,细节过渡更平滑;步长越大,计算效率更高。
- context_overlap (上下文重叠): 定义相邻参考窗口之间的重叠帧数。更高的重叠能确保帧间过渡更平滑,避免窗口切换时的画面突变。
视频模型在文生图领域的潜力
值得一提的是,将 wan2.1 工作流的输出帧数设为1,它便可以成为一个强大的文生图工具,其生成效果在某些方面甚至优于 Flux 等专用图像模型。视频模型由于额外处理了时序维度,其对图像内部结构和细节的理解可能更胜一筹。这预示着视频模型在未来可能成为静态图像生成领域的一支重要力量。





























