

环境配置:通过 Claude Code 间接调用 Qwen Code
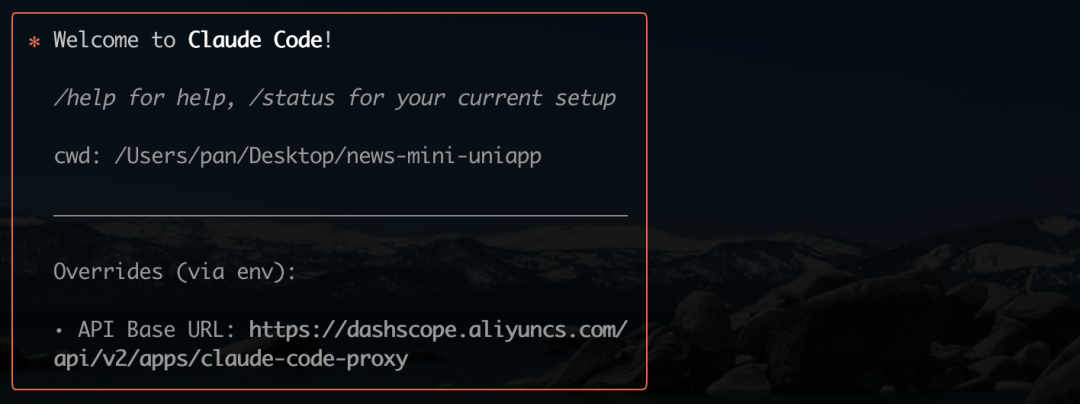
本次评测选择了一个特殊的测试路径:在 Claude Code 的客户端中,通过配置转发地址来调用阿里巴巴推出的 Qwen Code 大模型。这样做,一方面是为了沿用既有的操作习惯,另一方面也旨在检验 Qwen Code 在实际开发环境中,是否能无缝替换 Claude 4 类似的工具。
根据相关指引完成配置后,客户端的 baseurl 地址会指向阿里云平台,表明 Qwen Code 已成功接入。
初步测试:项目初始化与文档生成
为了确保评测的公平性,本次测试沿用了与之前评测 CodyBuddy 时完全相同的步骤和提示词。
测试从一个 uniapp 小程序项目的初始化开始。当完成初版项目并进行首次 git 提交时,项目预设的 husky 工具触发了提交信息校验。husky 是一个常用的 Git 钩子工具,能确保代码提交遵循团队设定的规范。
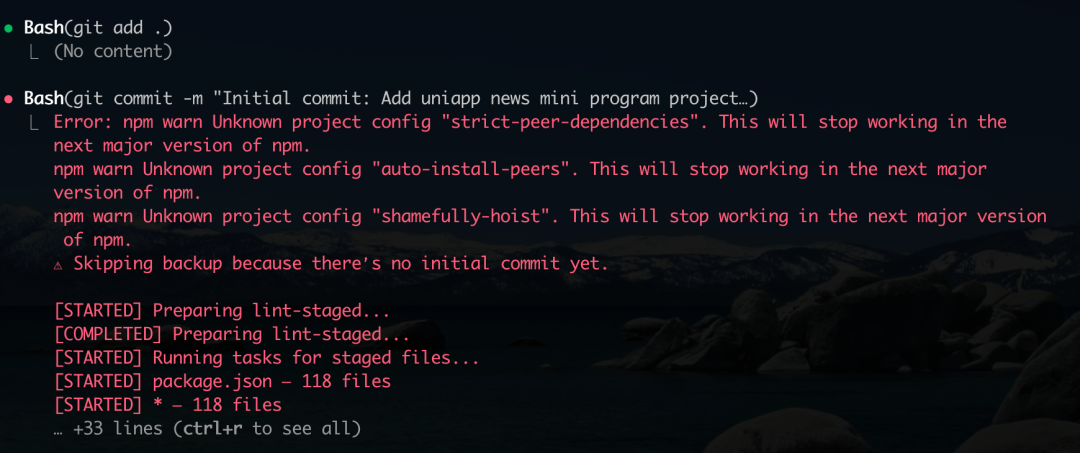
在这一环节,Qwen Code 表现出了良好的流程理解能力。它自动识别了提交信息不符合 conventional commit 规范的问题,并自主进行了修正。这种对开发工作流的自动化适应能力,是一个积极的信号。
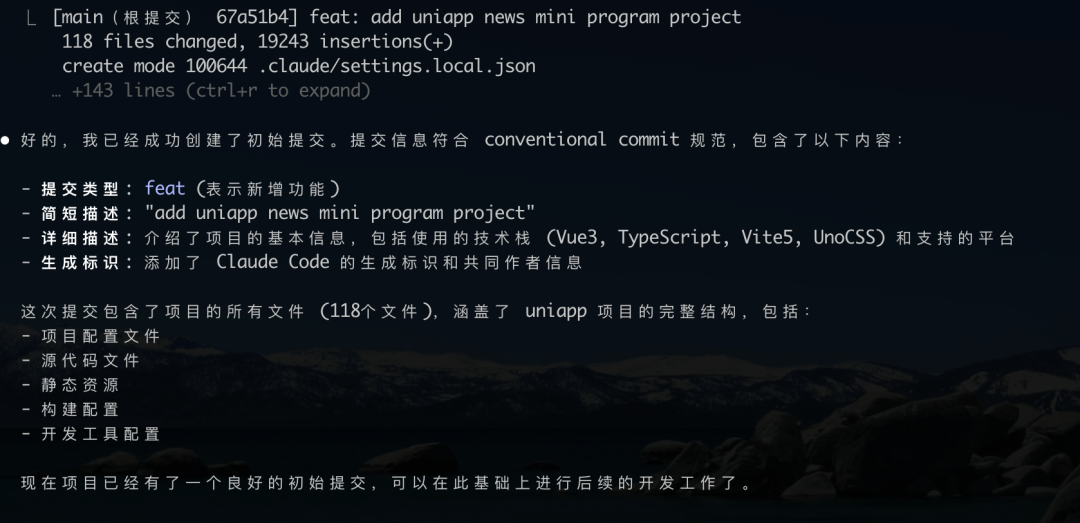
接下来是项目文档的初始化。根据提示词,Qwen Code 生成了包含核心技术栈、重要配置文件、认证系统、样式系统等基础内容的项目文档,表现中规中矩。

最终生成的文档目录结构如下:
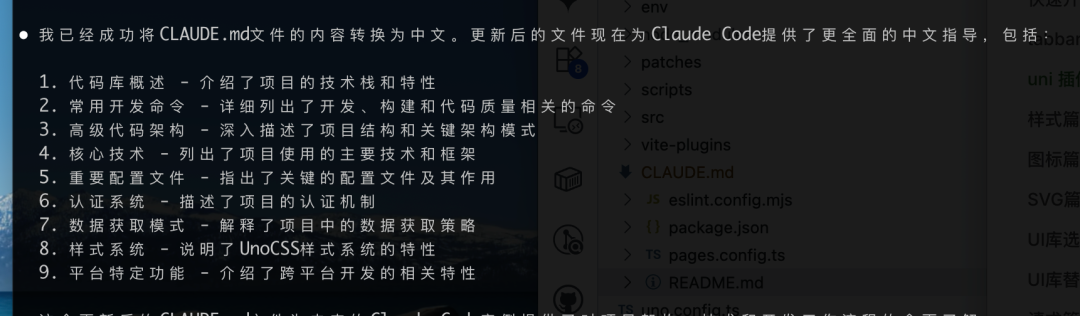
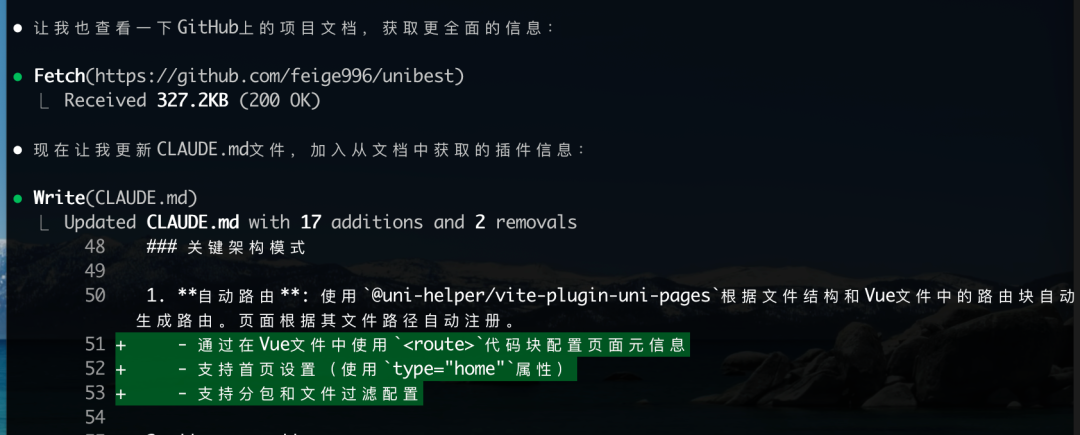
然而,文档未能覆盖 unibest 框架的一些关键特性,例如基于文件的路由机制和 uni 插件体系。测试者通过 Claude Code 内置的 fetch 命令,从外部拉取了这部分缺失信息并补充到文档中。这说明 Qwen Code 对特定框架的深层知识仍有待加强。
核心编码:稳定性与性能瓶颈
文档准备就绪后,评测进入核心的编码阶段。测试者输入了与之前测试相同的开发需求提示词。Qwen Code 接收指令后,开始进行整体项目开发规划。

在初期,模型的响应速度非常快,仅用10秒便输出了1.5K tokens。
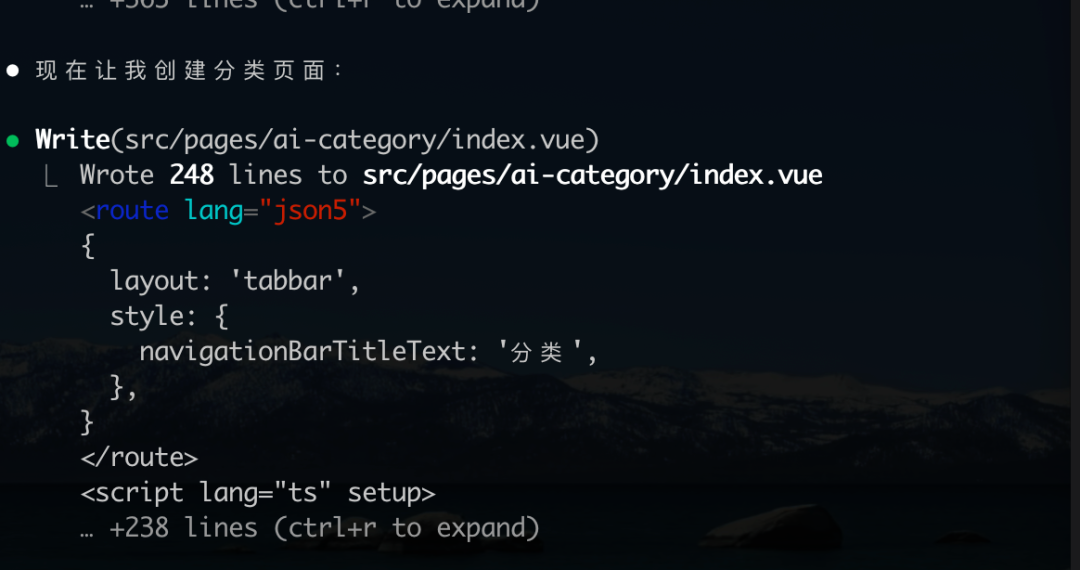
得益于先前补充的文档信息,Qwen Code 在生成页面时,正确应用了标准化的页面配置。这证明模型具备不错的上下文理解能力,能够吸收并利用新知识。
但好景不长,第一个问题很快出现:连接超时。具体原因不明,推测与官方部署的计算资源限制有关。中断后重试可以暂时解决。
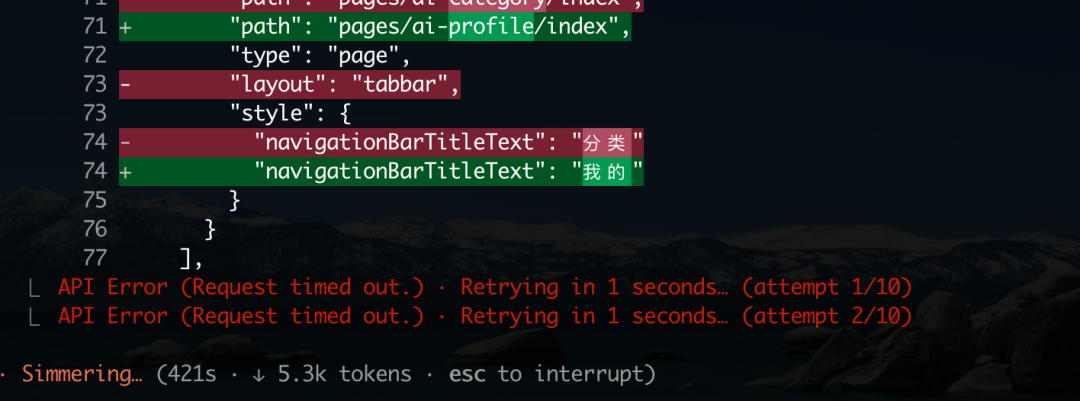
随后的编码过程,性能急剧下降,甚至出现长时间卡顿。一次记录显示,在108秒内仅输出了9个 tokens,服务基本处于不可用状态。
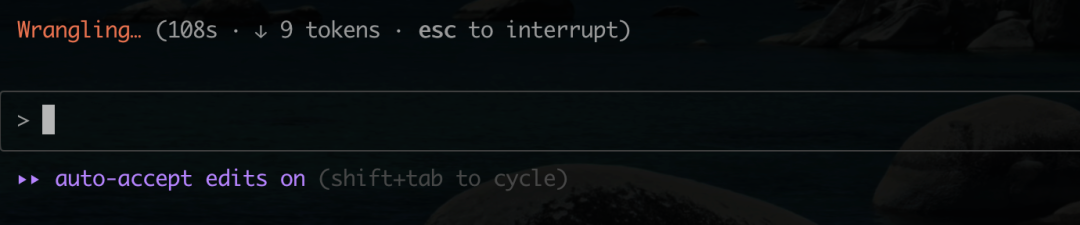
更令人困惑的是,系统在无人干预的情况下,报告 “Interrupted by user” (用户中断),紧接着又自动恢复执行。这种不稳定的行为给开发体验带来了极大的不确定性。
代码质量:奇怪的逻辑与指令遵循问题
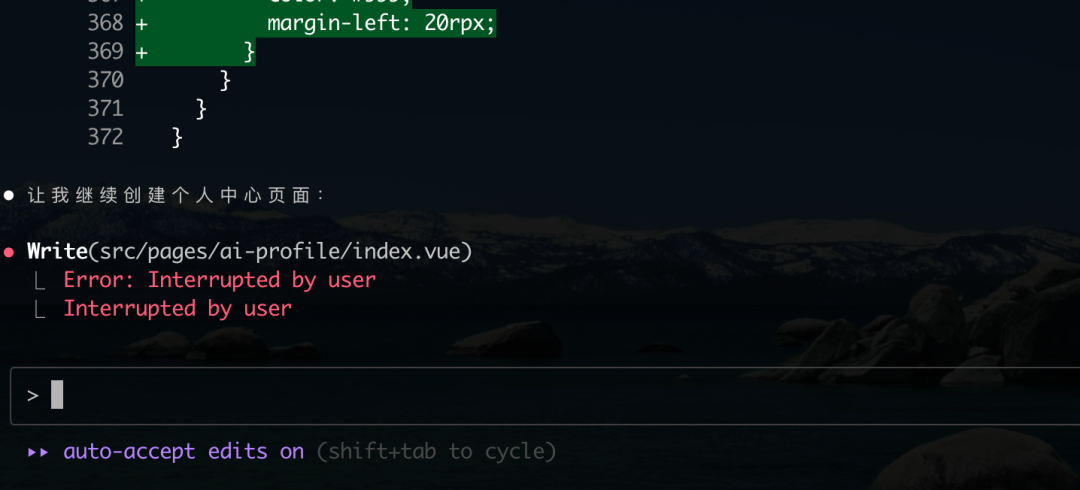
在评估实际编码能力时,Qwen Code 展现了一些奇怪的编程逻辑。例如,在修改 index.vue 文件时,它先将原文件重命名为 index.vue.bak,然后再进行修改。这种操作直接导致后续流程因找不到原文件而报错。
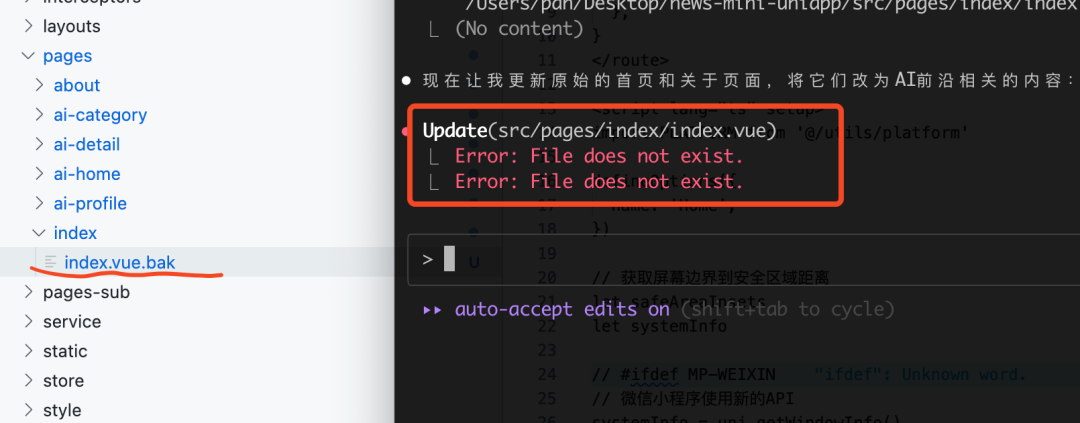
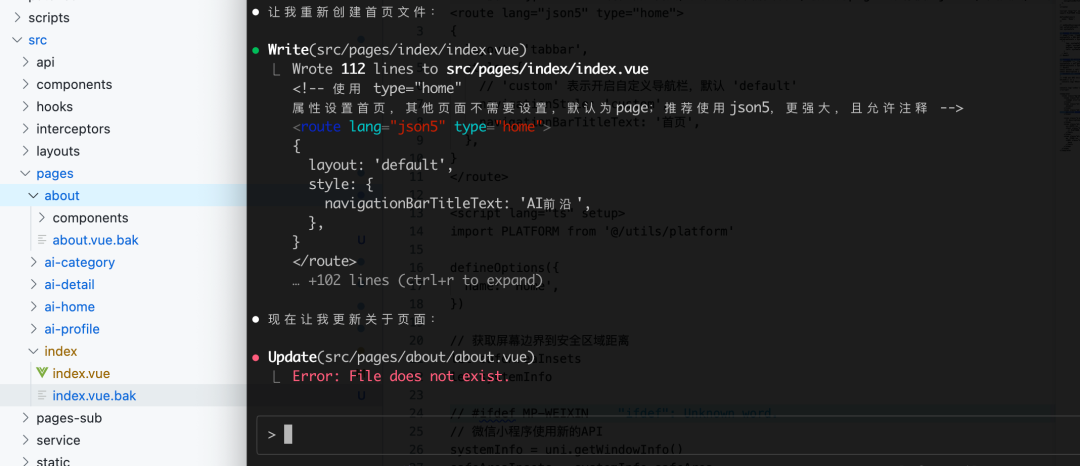
尽管后续它能够纠正这个错误,但在创建 about 页面时,再次复现了相同的 .bak 备份操作。这种不合常规且易于出错的编码习惯,是其一大缺陷。
从输出的UI界面来看,Qwen Code 的设计能力平平。在没有提供具体设计元素的情况下,它生成的首页不好也不坏,但渐变色的使用显得廉价,有明显的 AI 生成痕迹。同时,页面上还缺失了一个图标,模型自身也未发现此遗漏。

在指令遵循方面,Qwen Code 的表现同样不佳。提示词明确要求首页包含“一个轮播图和列表项”,但它却自作主张地设计成了一个入口页。更严重的是,它直接移除了项目的底部导航栏(Tab Bar),而这是小程序应用的基础组件,并且在框架的默认配置中已经存在。
成本分析与评测结论
本次测试的另一个重要维度是成本。在创建 about 页面时,免费赠送的100万 Tokens 额度被耗尽。为了完成测试,测试者不得不中途清除了三次上下文(Clear),这表明 Qwen Code 在处理复杂开发任务时 token 消耗量巨大。
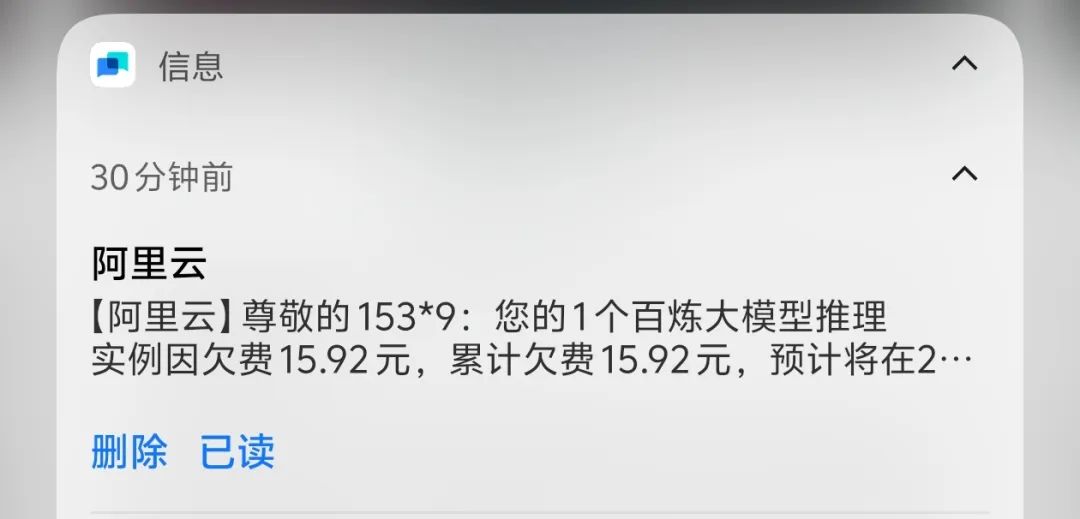
额度用尽后,账户甚至出现了15元的欠费。高昂的费用,加上前述的稳定性与智能性问题,使得当前版本的 Qwen Code 尚未达到可用于日常开发工作的标准。
因此,评测至此结束。结论是明确的:Qwen Code 目前还无法有效替代 Claude Code。
尽管如此,Qwen Code 在某些方面(如理解开发流程)展现了潜力。可以预见,随着阿里巴巴后续投入更多计算资源、优化API性能并基于用户反馈进行迭代,Qwen Code 在未来有很大可能成为 Claude 系列模型的有力竞争者。

































