

検索拡張世代(RAG)システムを構築する際、開発者はしばしば以下のような混乱したシナリオに遭遇する:
- ページをまたぐテーブルのヘッダーが前のページに残され、データが無関係になる。
- このモデルは、不鮮明なスキャンでも自信を持って完全なエラーを出す。
- 数式中の和記号 "Σ "が誤って "E "と認識された。
- 文書中の透かしや脚注は、あたかも本文であるかのように抽出され、情報の正確性を阻害する。
システムが正しい答えを出せなかったとき、その問題を直接ラージ・ランゲージ・モデル(LLM)のせいにするのは早計かもしれない。ほとんどの場合、問題の根本は文書解析の初期段階の失敗にある。
製薬分野のアプリケーションシナリオを想像してみよう。副作用を文書化したPDFは、通常2段組のレイアウトで、ページ間にフローティングテキストボックスがあります。最大99%のテキスト抽出精度を謳うオープンソースツールを使って解析すると、以下のような断片的な結果が得られるかもしれない:
第一页末尾:...注意事项(不完整)
第二页开头:特殊人群用药...(无上下文)
在 RAG インデックスが作成されると、これらの2つの意味的に無関係なテキストセグメントは異なるチャンクに切り分けられる。ユーザーが "Contraindications to the use of drug X in patients with hepatic insufficiency"(肝不全患者における薬剤Xの使用禁忌)とクエリすると、システムはキーワード "contraindications "を含む段落だけを検索することができる。しかし、重要な文脈上の見出し「特別な集団に対するOCK」がその段落から欠落しているため、モデルは完全で正確な答えを提供することができません。
このことは、文書解析の品質が、直接的に次の文書の品質を左右することをよく示している。 RAG システム性能の上限。
なぜ文書の解析はこれほど複雑なのか?
文書解析は単一のアルゴリズムツールではなく、複雑なソリューションの集合である。その複雑さは、以下のような多次元的な課題の組み合わせに起因する:
- ファイルフォーマットPDF、Word、Excel、PPT、Markdown、その他のフォーマットはそれぞれ異なる方法で扱われます。
- ビジネス学術論文、ビジネスレポート、財務諸表など、さまざまな文書に対応する独自のレイアウトスタイル。
- 言語タイプ異なる言語の認識は、モデル学習のための対応するコーパスに依存します。
- ぶんしょようそ段落、見出し、表、数式、コーナーなどの要素を正確に削減することは、以下のような問題を解決するための重要な要素である。
LLMエッセイの階層構造を理解する鍵。 - ページレイアウト1段組、2段組、多段組の混在などのレイアウトは、読み順の正しい復元に直接影響する。
- 画像の内容テキスト
OCR手書き認識や画像解像度の最適化は、テキストが混在するシナリオでは特に問題となる。 - テーブル構造テーブルのセル結合、クロスページ、入れ子などの複雑な構造により、その解析はテキストや画像とは異なります。
- 追加能力インテリジェントなチャンキングは構文解析の自然な一部ではありませんが、高品質のチャンキング、特に非常に大きなテーブルのチャンキングは、Q&Aの結果を大幅に改善することができます。
単一のツールで上記の次元のすべてに秀でることはできません。そのため、何も考えずにオープンソースのツールを選ぶと、どちらか一方を見失い、高品質なアプリケーションのニーズを満たすことが難しくなることが多い。
文書解析ツールを科学的に評価するには?
完璧な汎用ツールなど存在しない以上、与えられたシナリオに最適な選択をどのように評価するのか。上海人工知能研究所の研究成果が、その参考となる。この研究成果は、コンピューター・ビジョンのトップ・カンファレンスである CVPR 2024 の専門評価を開始した。 PDF 文書解析能力のベンチマークOmniDocBench。
OmniDocBench 20万ドルから PDF 文書から視覚的特徴を抽出し、クラスター分析によって有意な差別化を持つ6000ページをフィルタリングし、最終的に981ページにきめ細かな注釈を付けた。アノテーションの次元は非常に豊富で、レイアウトの境界ボックス、レイアウト属性、読み順、階層関係などをカバーしている。
評価指標について。OmniDocBench テキスト、表、数式、読み順などの異なる次元に対して、正規化編集距離(NED)、ツリー編集距離に基づく類似度(TEDS)、および BLEU その他多くのアルゴリズムを駆使して、包括的で公平な評価を行う。
各次元でのリーダーは誰か?
OmniDocBench 評価報告書からは興味深い傾向が見て取れる。

(出典:https://arxiv.org/abs/2402.07626)
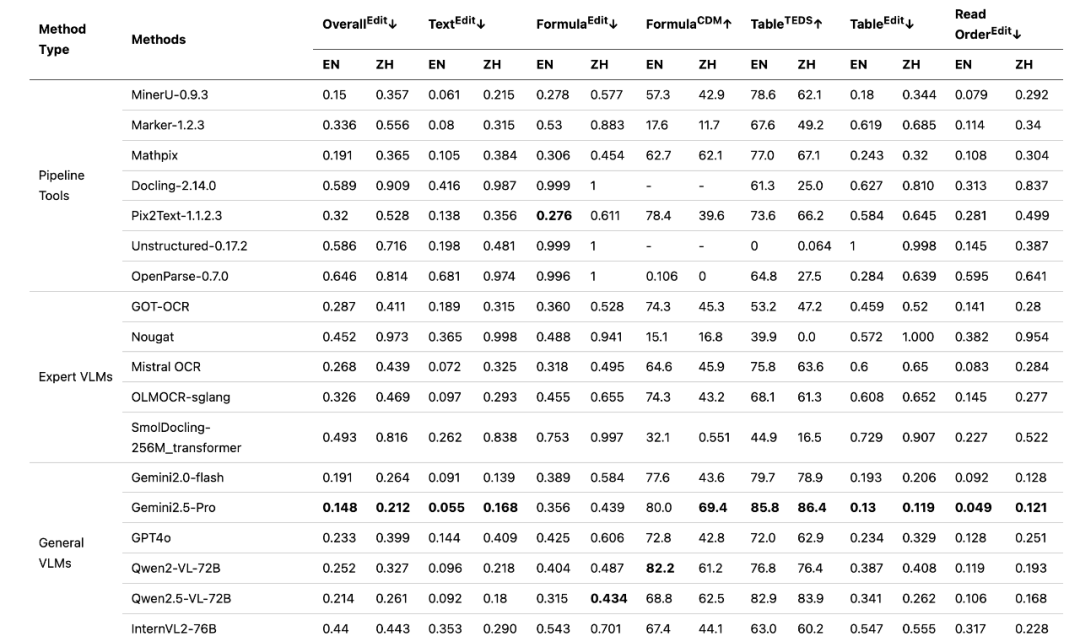
(出典:https://github.com/opendatalab/OmniDocBench/blob/main/README_zh-CN.md)
このプロジェクトの初期の論文グラフでは、さまざまなタイプの従来の文書解析ツールが、さまざまな次元で競合していた。しかし、一般的な視覚的マクロモデル(たとえば Gemini 1.5 Pro)がレビューの対象となったが、その強力な総合力により、すべての指標でトップのポジションを獲得することができた。
このアドバンテージは、以下の点に起因する。 Gemini このようなネイティブのマルチモーダル・マクロモデルは、画像とテキスト情報をエンドツーエンドで処理し、ドキュメントの全体的なレイアウトとセマンティクスをよりよく理解することができる。しかし、この強力な機能には高いコストがかかる。
以 Gemini 1.5 Pro たとえば、走り書きの手書き文字は正確に認識できたが、複数のセルとコーナーラベルが結合された複雑な表を扱ったときには、やはり大きな解析エラーが発生した。
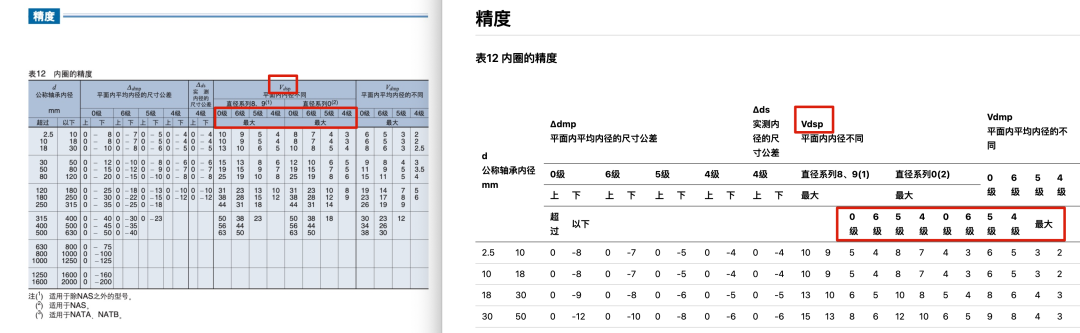
使用 Gemini 1.5 Pro 複雑なテーブルを解析する際のエラーの例)
より重大なのはコストの問題である。このページを解析するだけでも PDF費用は約1.2元だった。コストの主な原因は、以下のモデル出力である。 Token これは、大規模な文書処理を必要とする組織にとっては大きなオーバーヘッドである。
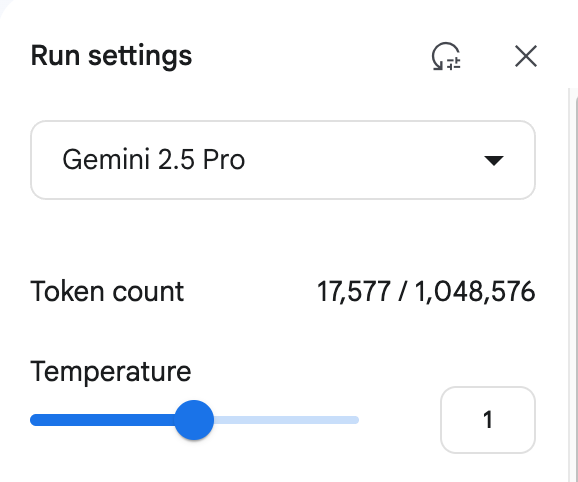
使用 Gemini 1.5 Pro (文書解析のコスト消費例)
だからGemini すべてのシナリオに対応する万能の解毒剤ではないその中で Gemini それ以上に、業界は unstructured.io、Marker 和 PyMuPDF そのほかにも、特定のタスクやコスト管理により有利な、優れたオープンソースや商用ソリューションが数多くある。正しい選択は、アプリケーションのシナリオを明確に定義し、パフォーマンス、コスト、特定のニーズのバランスを見つける必要性から始まる。
実践的アドバイス
構築または最適化する場合 RAG システムを構築する際、開発者は以下のステップを参考にして、文書解析の問題を克服することができる:
- 診断ドキュメント・ライブラリ契約書、報告書、スキャンなどの文書を見直し、複雑な表、数式、特定のページレイアウトが主な課題であるかどうかを明確にします。
- ターゲット検証比較
OmniDocBenchまたはその他のレビュー・レポートの中から、特定の次元に秀でたツールを1つか2つ選び、的を絞った検証を行い、ビジネス・ニーズに最も適したソリューションを見つける。 - フロンティアから目を離さない文書解析技術はまだ急速に進化しています!
OmniDocBenchこのようなベンチマーク調査や新しい構文解析ツールは、システムのパフォーマンスを継続的に最適化するのに役立ちます。
関連研究
OmniDocBench論文:https://arxiv.org/abs/2402.07626






































