



memUは、AIパートナーのために設計されたオープンソースの記憶フレームワークである。 現在の大きな言語モデルは一般的に記憶が短く、ユーザーとの長期的なつながりを築くことができないが、memUはAIにとってインテリジェントな「記憶フォルダ」のような役割を果たし、AIがユーザーのアイデンティティ、好み、過去の会話を記憶し、ユーザーとの交流を続ける中でユーザーとともに「成長」していくことを可能にする。「フレームワークの核となるのは、自律的なメモリーである。 フレームワークの中核にあるのは自律的なメモリー・エージェントで、どの情報を記録、修正、アーカイブするかを自動的に決定し、断片的な会話を構造化されたメモリー・ファイルに統合する。 このようにして、memUは、従来のメモリ・ソリューションの高コスト、低精度、困難な管理という問題を解決し、開発者が本当にあなたを知り、あなたを記憶するパーソナライズされたAIアプリを簡単に構築できるようにすることを目指している。
機能一覧
- AIコンパニオンに最適化このフレームワークは、AIコンパニオンやAIロールプレイングなど、長期的なインタラクションを必要とするアプリケーションシナリオを中心に設計されており、適応性の高い記憶能力を提供します。
- 高精度と低コストLocomoベンチマークでは、memUは92%のメモリー精度を達成し、最適化されたオンライン・プラットフォームはメモリー機能の呼び出しコストを最大90%削減した。
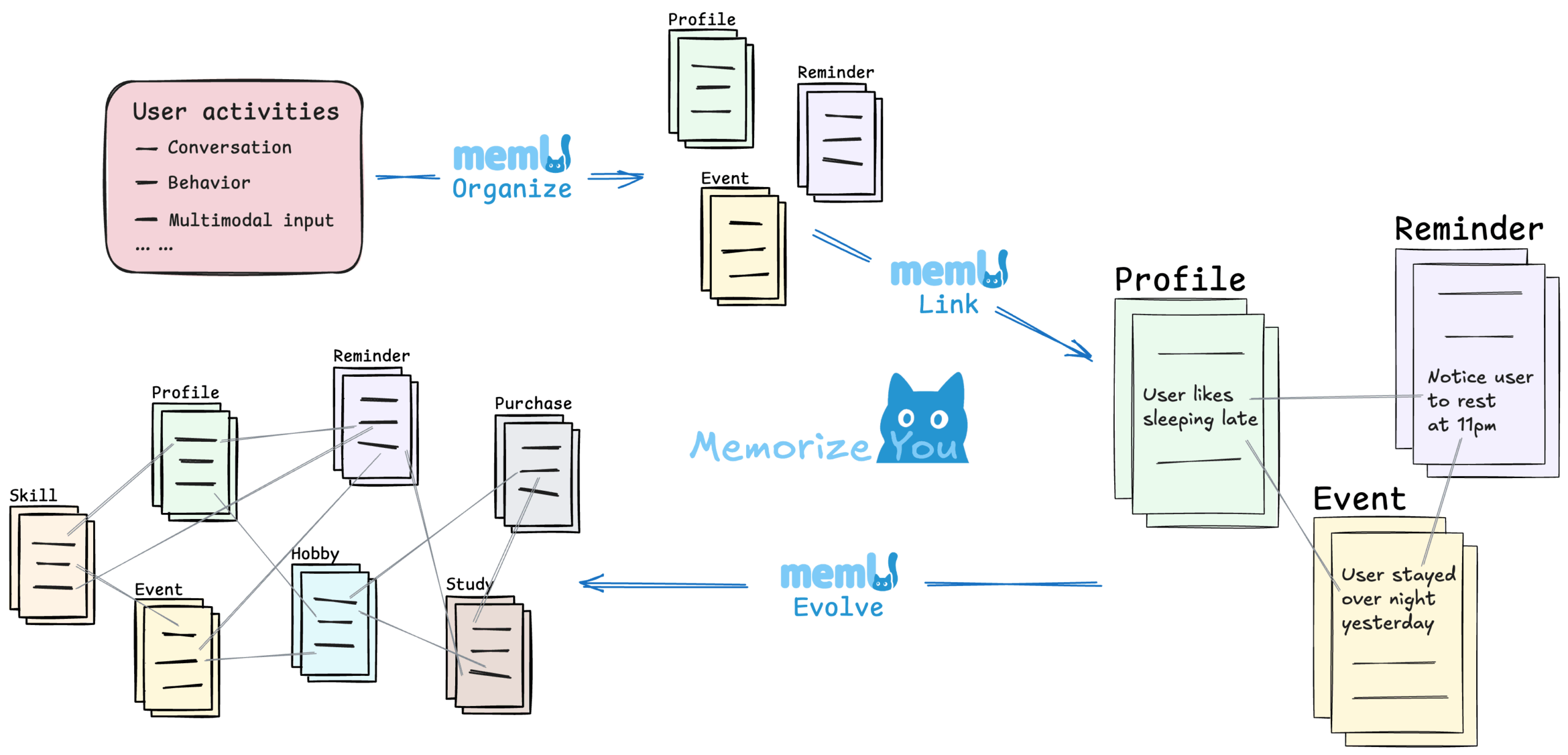
- インテリジェント・メモリー・ファイル・システム単純な情報の保存ではなく、4つのコア・メカニズムによってメモリーをインテリジェントに管理する:
- オーガナイズメモリーファイルは、メモリーエージェントが自動的に管理します。
- リンク関連する記憶を自動的に関連付けて知識グラフを形成し、検索を簡単な想起に変えます。
- 進化するAIはオフラインでも自己反省を行い、既存の記憶を分析することで新たな洞察を生み出し、知識ベースをより賢くする。
- 決して忘れない人間の記憶習慣を模倣し、重要な情報はすぐに利用でき、重要でない情報はフェードアウトする。
- 高度な検索戦略セマンティック検索、ハイブリッド検索、文脈検索のサポートにより、AIは必要な情報を迅速かつ正確に見つけることができます。
- 柔軟な展開オプション:
- クラウド版開発者がサーバーやメンテナンスの問題を心配することなく、すぐに統合できるAPIサービスを提供します。
- エンタープライズ・エディション最高レベルのセキュリティとカスタマイズを必要とする組織には、商用ライセンス、プライベートな展開、専用のテクニカルサポートを提供します。
- コミュニティ版(近日公開)開発者は、データやカスタマイズの要件を完全にコントロールしながら、ローカルにデプロイすることができます。
ヘルプの使用
memUの核となるアイデアは、AIを記憶するプロセスを、コンピュータのファイルを管理するように直感的かつ自動化することだ。開発者はもはや、断片化されたチャットログや複雑なベクトルデータを手作業で処理する必要はなく、memUのメモリーエージェントに任せることができる。現在、memUを使い始める最も早い方法は、同社が提供するクラウドベースのサービスだ。
以下は、クラウド版memUにアクセスし、利用するための詳細な手順である:
ステップ1: アカウントの作成とAPIキーの取得
- まず、memUの公式アプリケーションプラットフォームにアクセスする必要があります:
https://app.memu.so。 - ウェブサイト上で登録手続きを完了し、新しいアカウントを作成してください。
- ログインしたら、プラットフォームのダッシュボードまたは設定メニューで、「APIキー」または同様のオプションがあるページを見つける(通常、リンクは次のとおり)。
https://app.memu.so/api-key/)。 - Generate a new API Key (API Key)をクリックし、このキーをコピーします。このキーは、アプリケーションがmemUクラウドサービスと通信するための唯一の認証情報ですので、大切に保管してください。
ステップ2:PythonプロジェクトにmemUクライアントをインストールする
開発環境で、ターミナルかコマンドラインツールを開きpipコマンドで memU 用の公式 Python ライブラリをインストールしてください。
pip install memu-py
このライブラリーは、memU APIとの複雑なやり取りをすべてカプセル化し、数行のシンプルなコードで強力なメモリーを実装できる。
ステップ3:対話メモリーを実装するコードでmemUを呼び出す
インストールが完了したら、コードを MemuClient を使い始める。以下は、台詞の一部をmemUに与えて記憶させる方法を示す基本的な例である。
import os
from memu import MemuClient
# 建议将API密钥存储在环境变量中,而不是硬编码在代码里
# 在终端中设置环境变量: export MEMU_API_KEY='你的API密钥'
api_key = os.getenv("MEMU_API_KEY")
# 1. 初始化客户端
# base_url 指向 memU 的云端API地址
memu_client = MemuClient(
base_url="https://api-preview.memu.so",
api_key=api_key
)
# 2. 准备你要记忆的对话内容
# 它可以是一段简单的文本,包含了用户和AI的交流
conversation_text = """
用户: "嘿,今天天气真不错!"
AI助手: "是啊,阳光明媚,很适合出去散步。你有什么计划吗?"
用户: "我打算下午去公园跑步,顺便买杯咖啡。"
AI助手: "听起来很棒!记得带上防晒霜。你最喜欢哪种咖啡?"
用户: "我最喜欢拿铁。"
"""
# 3. 调用 memorize_conversation 函数
# 这个函数会将对话内容发送给 memU 的记忆代理进行处理
memu_client.memorize_conversation(
conversation=conversation_text,
user_id="user_001", # 唯一的用户ID,用于区分不同用户
user_name="张三", # 用户的名字或昵称
agent_id="assistant_001", # AI伴侣的唯一ID
agent_name="贴心小助" # AI伴侣的名字
)
print("对话已成功记忆!")
コード解釈:
MemuClient(...)memUサービスへのブリッジとなるクライアントインスタンスを作成する。memorize_conversation(...)これが核となる機能だ。主要なメタデータを含むダイアログ・テキストを受け取る:user_id和agent_idmemUはこの2つのIDを使って、各ユーザーと各AIパートナーに別々の「メモリーフォルダー」を作成する。 これにより、ユーザーAの記憶がユーザーBの記憶と混同されることはない。user_name和agent_name対話の役割を理解するために、AIに豊かな文脈を提供する。
このコードを実行すると、memUのメモリーエージェントは自動的に会話を分析する。ユーザー「張さん」の嗜好(例えば、晴れた日に公園で走るのが好き、ラテを飲むのが好き)の記録を作成し、ユーザーの専用メモリーファイルに保存することができる。次に「張さん」が「小助」と対話するとき、AIはmemUに問い合わせてこの情報を呼び出し、より温かく人間的な対話を行うことができる。
アプリケーションシナリオ
- AIコンパニオンとAIロールプレイング
これはmemUの最もコアな応用シナリオである。memUは、AIがユーザーの誕生日、趣味、重要な経験などを記憶することを支援し、すべての対話が「コールドスタート」ではなく、過去に基づいて行われるようにすることで、真の感情的な絆を確立します。これにより、すべての対話が「コールドスタート」ではなく、過去に基づいて行われるようになり、真の感情的な絆が確立される。 - AI教育
教育分野では、memUはAI家庭教師が各生徒の学習進捗状況、長所、短所を記憶するのに役立つ。例えば、ある生徒が特定の数学の概念を繰り返し間違えた場合、AI家庭教師はそれを記憶し、今後のレッスンで的を絞った個人指導や練習を行うことができる。 - AIカウンセリング
memUは信頼できる「カルテ」システムとして機能し、AIセラピストが来談者とのあらゆるコミュニケーションを安全に記録し、来談者の気分の変化や重要な人物や出来事への言及を記憶するのに役立つ。これにより、AIは長期間にわたって一貫した安定した共感的なサポートを提供することができる。 - インテリジェント・パーソナル・アシスタント
パーソナル・アシスタントのカテゴリーのAIは、多くの日常業務やユーザーの好みに対応する必要がある。memUを使えば、AIアシスタントはユーザーの通勤経路、よく使う会議ソフト、好きなテイクアウトの味、家族の誕生日などを記憶することができる。ユーザーが「明日の会議の手配を手伝って」と言えば、AIは自動的にユーザーの習慣を思い出し、よりスマートで思慮深い提案をすることができる。ユーザーが「明日の会議の手配を手伝って」と言うと、AIは自動的にユーザーの習慣を思い出し、より賢く思いやりのある提案をすることができる。
QA
- 質問:memUは従来のベクターデータベースとどう違うのですか?
答え:従来のベクトル・データベースは、主に低レベルの「情報の保存と検索」機能を提供しており、通常はテキスト・セグメントをベクトルに変換し、類似検索を実行する。memUは、より高度でインテリジェントな「メモリー管理フレームワーク」です。情報を保存するだけでなく、自動的に記憶を整理、リンク、反映、忘却し、ダイナミックに進化する知識グラフを形成するメモリー・エージェントを内蔵しており、人間の記憶に近い。 - 質問:memUのクラウドサービスで私のデータは安全ですか?
回答:機密データを扱うビジネスアプリケーションやシナリオのために、memUはプライベートデプロイメントをサポートするエンタープライズエディションを提供しています。 つまり、memUシステム全体を自社のサーバーにデプロイすることで、データのプライバシーとセキュリティを完全に管理することができます。コミュニティエディション(セルフホスト型)は、将来的にローカル展開オプションも提供する予定です。 - 質問:memUがサポートしている大きな言語モデルとは何ですか?
答え:memU自体は、大規模言語モデル(LLM)とアプリケーションの間に位置するメモリフレームワークであり、設計上モデルを問いません。LLM上に構築されたあらゆるAIエージェントに統合することができます。クラウドベースのサービスを利用する場合、memUプラットフォームがモデルの呼び出しとメモリ管理の詳細を引き受けますので、開発者は基盤となるモデルを直接操作する必要はありません。 - 質問:コミュニティ版(セルフホスト)のリリースはいつになりますか?
回答:GitHubのページによると、コミュニティ版の現在のステータスは「Coming Soon」です。 この機能に興味がある方は、GitHubのリポジトリをフォローするか、公式Discordコミュニティに参加して最新のリリース情報を入手することをお勧めします。


























