



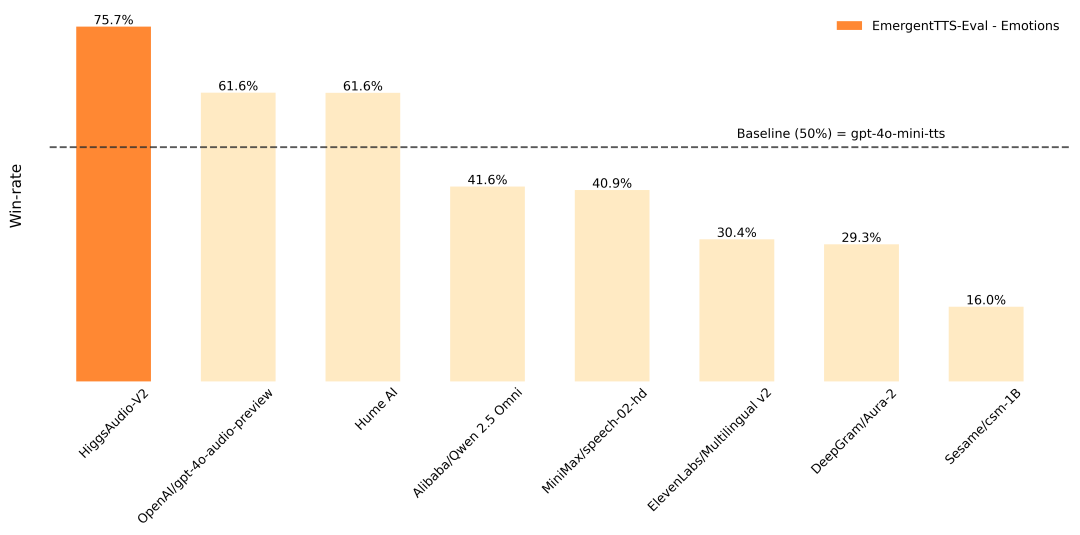
Higgs AudioはBoson AIによって開発されたオープンソースの音声合成(TTS)プロジェクトで、高品質で感情豊かな音声と多言語ダイアログの生成に重点を置いています。このプロジェクトは、1000万時間を超える音声データトレーニングに基づいており、ゼロサンプル音声クローニング、自然なダイアログ生成、多言語音声出力をサポートしています。Higgs Audio v2は、革新的なDual-FFNアーキテクチャとUnified Audio Phrase Splitterを使用して、テキストと音声の両方の情報を効率的に処理し、リアルな音声効果を生成します。EmergentTTS-Evalベンチマークでは、感情表現の勝率が75.7%と、他のモデルを大きく上回る好成績を収めています。このプロジェクトは、開発者、研究者、クリエイター向けに詳細なコードとインストールガイドを提供しており、音声コンテンツ制作、バーチャルアシスタント、教育分野で広く利用されています。
機能一覧
- 高品質な音声の生成:テキストを、幅広いイントネーションと感情表現をサポートする、自然で感情豊かな音声に変換します。
- マルチロールダイアログ生成:自然なダイアログの間、中断、重複をシミュレートするマルチロールスピーチ生成をサポートします。
- ゼロサンプルのボイスクローニング:追加トレーニングなしで、リファレンス音声からターゲットキャラクターの声を素早く生成します。
- 多言語サポート:英語、中国語、ドイツ語、韓国語、その他の言語での音声生成をサポート。
- 音楽と音声の組み合わせ:BGMと音声を同時に生成することができ、オーディオストーリーテリングや没入型体験に適している。
- 効率的な推論: Jetson Orin Nanoのようなエッジデバイスでの実行を低リソースフットプリントでサポートします。
- オープンソースコード:完全なコードベースとAPIを提供し、開発者が開発をカスタマイズできるようサポートする。
ヘルプの使用
設置プロセス
Higgs AudioはGitHubでホストされているオープンソースプロジェクトで、インストールプロセスは簡単ですが、いくつかの開発環境のサポートが必要です。以下は、異なる環境に適用可能な詳細なインストール手順です:
1.コードベースのクローン化
まず、Higgs AudioのGitHubリポジトリをローカルにクローンする:
git clone https://github.com/boson-ai/higgs-audio.git
cd higgs-audio
2.構成環境
Higgs Audioは、仮想環境、Conda、uvなど、いくつかの環境設定方法を提供しています。Python 3.10以上を推奨します。以下は仮想環境を設定する手順です:
python3 -m venv higgs_audio_env
source higgs_audio_env/bin/activate
pip install -r requirements.txt
pip install -e .
コンダを使うなら:
conda create -n higgs_audio_env python=3.10
conda activate higgs_audio_env
pip install -r requirements.txt
pip install -e .
高スループット・シナリオの場合、以下の使用を推奨する。 vLLM エンジン参考 examples/vllm フォルダで、以下のコマンドを実行してAPIサーバーを起動する:
python -m vllm.entrypoints.openai.api_server --model bosonai/higgs-audio-v2-generation-3B-base --tensor-parallel-size 4 --gpu-memory-utilization 0.9
ハードウェア要件最高のパフォーマンスを得るためには、少なくとも24GBのビデオメモリを搭載したGPU(NVIDIA RTX 4090など)を推奨します。Jetson Orin Nanoのようなエッジデバイスは、より小さなモデルも実行できます。
3.インストールの検証
インストールが完了したら、以下のPythonコードを実行して、環境が正しく設定されていることを確認する:
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine
engine = HiggsAudioServeEngine(
"bosonai/higgs-audio-v2-generation-3B-base",
"bosonai/higgs-audio-v2-tokenizer",
device="cuda"
)
output = engine.generate(content="Hello, welcome to Higgs Audio!", voice_profile="neutral")
音声ファイルが出力されれば、インストールは成功です。
機能 操作の流れ
Higgs Audioの主な機能には、音声合成、複数文字のダイアログ生成、ボイスクローンなどがあります。以下はその手順です:
1.音声合成
ヒッグス・オーディオは、テキストを自然な音声に変換し、感情表現を voice_profile パラメーターコントロール。例えば、「緊急」トーンの音声を生成する場合:
curl http://localhost:8000/v1/audio/generation -H "Content-Type: application/json" -d '{"text": "Security alert: Unauthorized access detected", "voice_profile": "urgent"}'
ユーザーはさまざまな感情ラベルを指定することができる(たとえば happy、sad、neutral)、このモデルは自動的にテキストの意味論に従ってトーンとテンポを調整する。
2.マルチ・アクター・ダイアログ生成
Higgs Audioは、現実のシナリオにおける自然なやり取りをシミュレートする複数キャラクターのダイアログを生成するのが得意です。ユーザーは、例えば文字タグを含むテキストを提供する必要があります:
dialogue = """
SPEAKER_0: Hey, have you tried Higgs Audio yet?
SPEAKER_1: Yeah, it’s amazing! The voices sound so real!
"""
output = engine.generate(content=dialogue, multi_speaker=True)
このモデルは、文字タグに基づいてさまざまな音声を生成し、間やトーンの変化を自動的に加えるので、オーディオブックやゲームのセリフに適している。
3.ゼロサンプル音声クローニング
ユーザーは参照音声を提供することができ、モデルはその音声特徴を複製します。例
output = engine.generate(
content="This is a test sentence.",
reference_audio="path/to/reference.wav",
voice_profile="cloned"
)
リファレンス音声は、5~10秒の長さのクリアなシングルボイスを推奨します。クローン音声は、パーソナライズされた音声生成に使用できます。
4.多言語サポート
Higgs Audioは多言語音声生成に対応しています。ユーザーはテキストの言語内容を指定するだけで、モデルが自動的に適応します。例えば
output = engine.generate(content="你好,欢迎体验Higgs Audio!", voice_profile="neutral")
現在、英語、中国語、ドイツ語、韓国語に対応しているが、中国語の数字や記号の扱いには制限がある可能性があり、さらに最適化する必要がある。
5.音楽と音声の統合
ヒッグス・オーディオは、没入型体験のためにBGM付きの音声を生成する。ユーザーはテキストに音楽タグを追加する必要があります:
content = "[music_start] The stars shimmered above. [music_end] This is a magical night."
output = engine.generate(content=content, background_music=True)
このモデルは、タグに基づいてBGMを生成し、音声とブレンドする。
使用上の注意
- ハードウェアの最適化GPU上で実行することで、推論速度を大幅に向上させることができます。エッジデバイスでは、リソース使用量を減らすために、より小さなモデルを使用する必要がある。
- 入力フォーマットテキスト入力は、効果的な生成を確実にするために、複雑な記号や書式エラーを避け、明確にする必要があります。
- リファレンス・オーディオボイス・クローニングには、バックグラウンド・ノイズによる干渉を避けるため、高品質のリファレンス・オーディオが必要です。
- 多言語主義漢数字やパーセンテージ記号は生成不良につながる可能性があるため、複雑な記号は避けることが推奨される。
アプリケーションシナリオ
- オーディオブック制作
Higgs Audioは、書籍のテキストを感情豊かなオーディオブックに変換します。マルチキャラクターのダイアログやサウンドトラックをサポートしており、高品質のオーディオブックを制作する出版社や個人のクリエイターに適しています。 - 教育コンテンツ制作
教師はHiggs Audioを使って、歴史上の人物の吹き替え音声や多言語指導音声を作成し、授業の没入感と双方向性を高めることができます。 - ゲーム開発
開発者は、マルチキャラクター・ダイアログ機能を使用して、ゲーム体験を向上させる自然な中断や感情表現をサポートするゲーム用のダイナミックなキャラクター・ボイスを生成することができます。 - バーチャルアシスタント開発
企業は、顧客サービスやスマート・デバイス向けに、パーソナライズされた音声を持つHiggs Audioをベースにしたバーチャル・アシスタントを開発することができる。 - アフレコ
Higgs Audioのボイスクローニングと多言語サポートは、異なるキャラクターや言語に素早く適応し、映画やテレビ制作のボイスオーバーを生成するのに理想的です。
QA
- Higgs Audioはどの言語に対応していますか?
現在、英語、中国語、ドイツ語、韓国語などをサポートしており、将来的にはさらに多くの言語に対応する予定だ。 - 音声クローニングの安定性を最適化するには?
感情的なコントロールを維持するために、生成された音声を参照として直接使用することは避け、5~10秒の長さで、明確な一人用の参照音声を提供する。 - 動作にはGPUが必要ですか?
GPUは性能を向上させるが、より小型のモデルは、軽量アプリケーション用のJetson Orin Nanoのようなエッジ・デバイスで動作させることができる。 - 中国語音声生成の限界とは?
中国語の数字や記号は生成不良を引き起こす可能性があるため、入力テキストを簡略化することをお勧めします。 - 複数のキャラクターが登場する台詞で、声の違いをどのように扱っていますか?
テキストに文字タグ(例:SPEAKER_0)を追加することで、モデルは自動的に異なる音声を生成し、対話の自然なリズムをシミュレートする。




























