

When building knowledge base applications based on Retrieval Augmented Generation (RAG), document preprocessing and slicing (Chunking) is a critical step in determining the final retrieval results. Open Source RAG engine (loanword) RAGFlow Provides a variety of slicing strategies, but its official documentation lacks clear explanations on the details of the methods and specific cases, which brings a lot of confusion to developers.
Through a series of benchmarks, this article aims to provide insights into the RAGFlow The working mechanism and core differences between the different slicing methods in the The test will be organized around the following common questions:
- How will the chapter table of contents of a document be handled when sliced? Will it be treated as a separate block, or merged with the body text?
- How will images embedded in body text be attributed when sliced?
MANUAL、BOOK、LAWSWhat is the specific slicing basis for the equal slicing method?TABLEHow does the method ensure that table header information is retained for each row of data when slicing by row?QACan the slicing method beTABLEMethods of substitution?
RAGFlow The slicing methods can be broadly categorized as follows:
- Generalized approach (
General): Covers all file types and slices based on "length + delimiter", which is widely applicable but less accurate. - Document structuring methods (
MANUAL,BOOK,LAWS): Slices documents with a clear hierarchical structure (e.g. DOCX, PDF) based on their table of contents or specific tags. - Table Structuring Methods (
TABLE,QA): For tabular data (e.g., XLSX), processing by rows or specific columns. - Scenario-specific methods (
ONE,RESUME,PAPER,PRESENTATION): Designed for special purposes such as single documents, resumes, essays and presentations.
This analysis will focus on the most common and confusing "document structuring methods" and "table structuring methods".
Slicing by document structure: MANUAL, BOOK, LAWS
All three methods are suitable for processing structured documents, but their slicing logic and granularity are different. In order to visualize the comparison, the test uses "Tax Collection and Management Law of the People's Republic of China.docx" as a sample, which contains a clear chapter structure.
The original document structure is intercepted below:

MANUAL method: based on the "Title" style.
MANUAL The method splits the document strictly according to the "Heading" style defined in Word or PDF (e.g. Heading 1, Heading 2). It slices down to the finest granularity of the heading level. It is worth noting that only the "style" is recognized as the title of the text will trigger the cut, ordinary bold or enlarged font text (such as the text of the "Article 15", "Article 16 Normal bolded or enlarged text (e.g. "Article XV", "Article XVI" in the text) will be treated as body text.
Test Documentation Usage MANUAL The slicing result of the method is shown below:

The results of the analysis show that the document is sliced into a total of 6 chunks (Chunks). Each chunk inherits all the titles of its parent directories up to the root title of the document. For example, the content block under "Chapter 2 Tax Administration" will contain two headings, "Tax Collection and Administration Law of the People's Republic of China" and "Chapter 2 Tax Administration".
If there is directly attached body content under the top-level header, this will also be cut into a separate block.

BOOK methodology: based on "table of contents + paragraph"
BOOK The method uses a deeper semantic slicing strategy. It first splits by chapter table of contents and then further slices the body content within each chapter by semantics (subtopics or paragraphs). This allows BOOK The slicing granularity of the method is the finest of the three.
utilization BOOK method processes the same document with the following results:
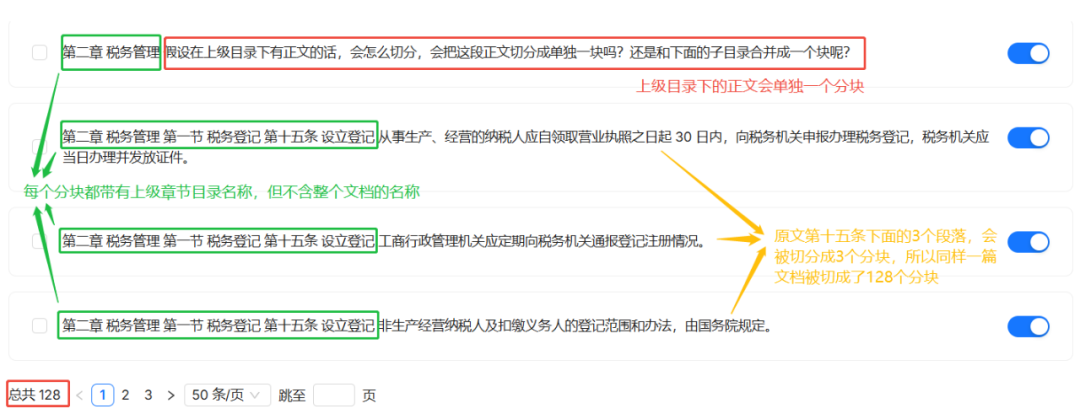
与 MANUAL The core difference between the methods is that the three paragraphs under "Article 15" are finely sliced into three separate chunks. The entire document is eventually cut into 128 chunks.
In the context of contextual inheritance, theBOOK Each block of the method will likewise contain its parent directory title, but unlike the MANUAL Unlike this, it does not contain the top-level headings of the document. This design may be more suitable for focusing on specific section content in a search rather than the context of the entire document.
LAWS methodology: based on "section clause" labeling
LAWS method is designed for legal or regulatory documents, and recognizes specific tags such as "Chapter X", "Article X", etc. by regular expressions to slice and dice, ignoring the text's "title" style or table of contents level. or the table of contents level of the text.
utilization LAWS method processes the document and slices the result to 87 blocks.

LAWS The methodology is characterized as follows:
- identifier:: Even though "Article 15" and "Article 16" are in the normal body style in the document, they are successfully cut because they match the "Article" markup.
- paragraphing: with
BOOKDifferent.LAWSThere will be no re-slicing of multiple paragraphs under articles, but rather they will be combined in the same block. - contextualization:
LAWSThe contextualization is very unique. Instead of embedding the higher-level catalog headings directly into each article block, it aggregates the catalog headings at each level into a separate block (as shown in the green wireframe above) to achieve separation of content from the catalog index.
Comparison Summary of Three Document Slicing Methods
Based on the above tests, the characteristics of the three methods can be summarized as follows:
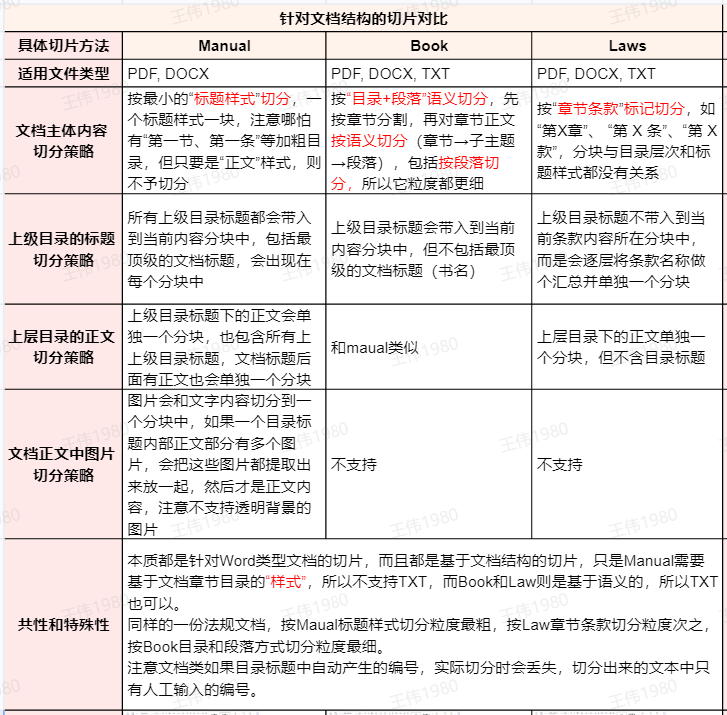
It is worth adding thatMANUAL The application of the method is very clear, that is, product manuals, technical documents and other documents with a standard "title" style hierarchy. And LAWS Specializing in laws, regulations, and policy documents.BOOK On the other hand, with its fine-grained segmentation at paragraph level, it is more suitable for long reports or books that require deep semantic understanding and Q&A.
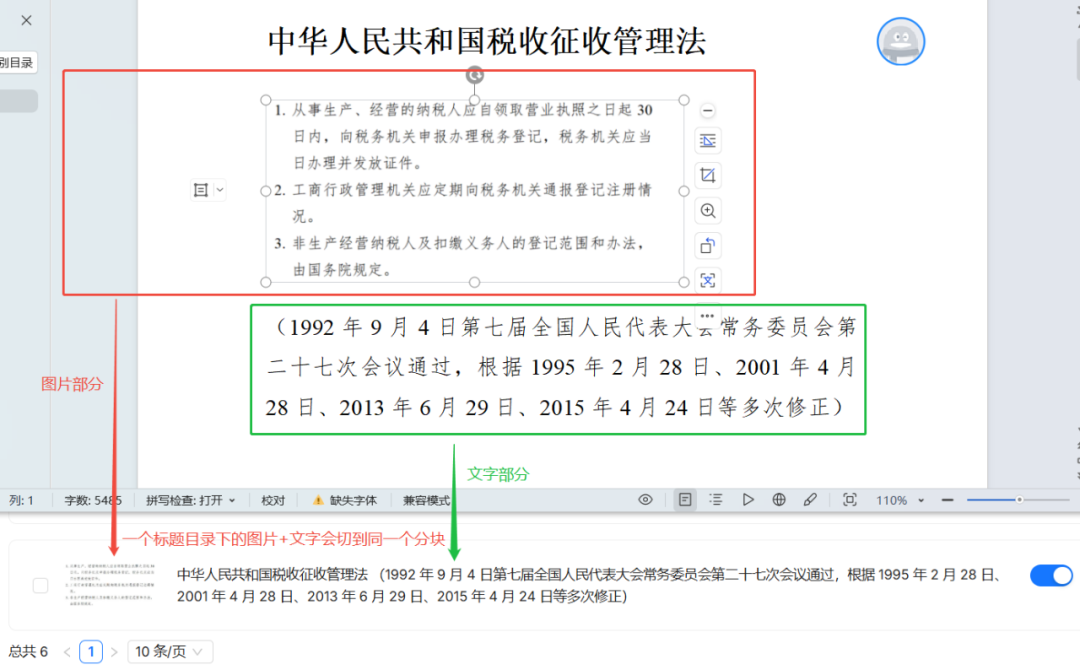
In addition, the test found that MANUAL method is able to document the picture and its neighboring text content cut into the same block, which is very useful for graphic document processing.
Slicing by table structure: TABLE, QA
Next, we turn to validating the slicing method on table-like data such as Excel files.
TABLE method
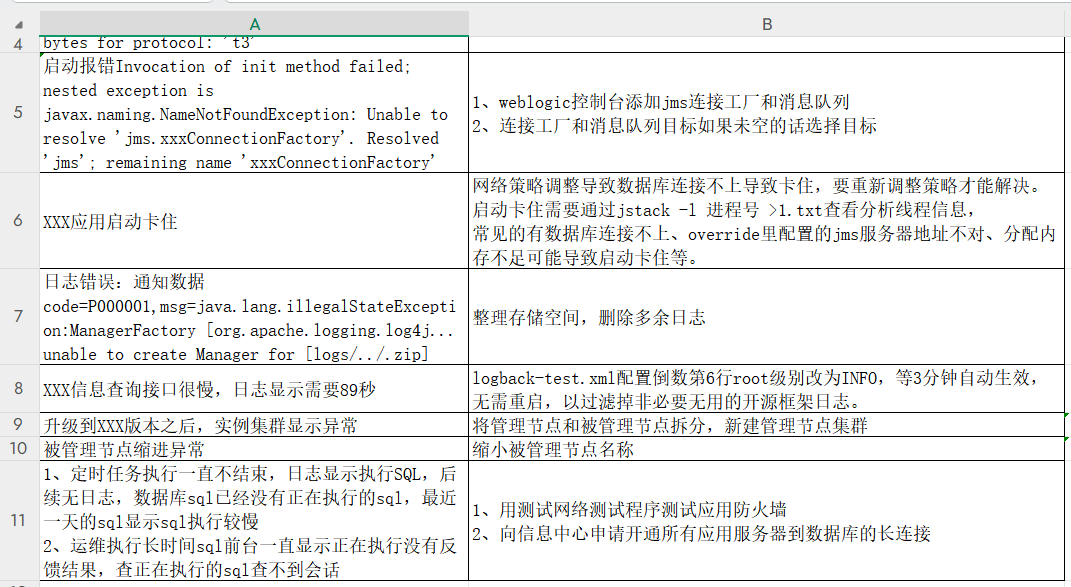
The test uses an O&M knowledge form that contains fields for product, region, business domain, problem description, cause, and solution.
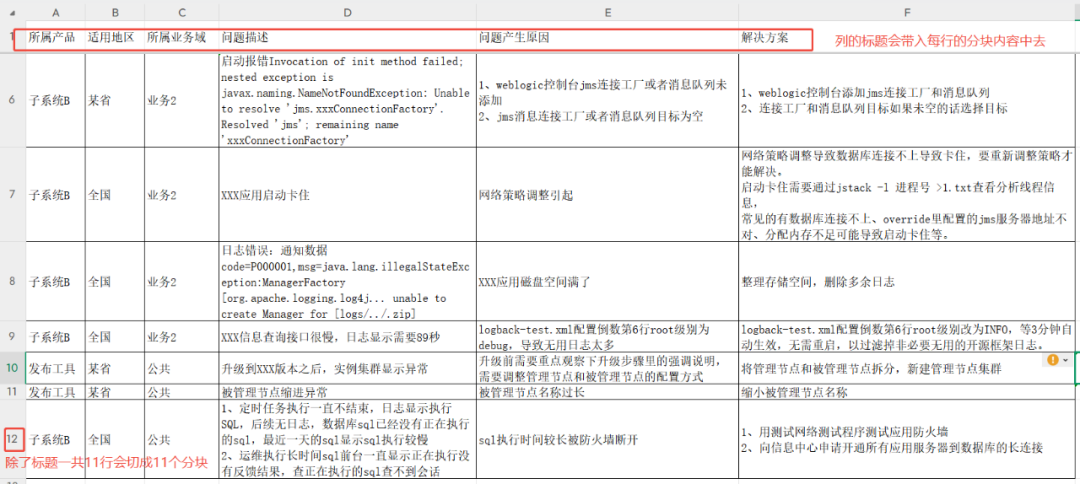
utilization TABLE When slicing by the methodRAGFlow The first row of the table is recognized as the column header. When processed, it slices through each row (except for the header row) and adds the column header information in full to each row's content block, forming a "Key: Value" format.
The result of the slicing is as follows, where each line becomes a separate block of knowledge with complete contextual information:

QA methodology
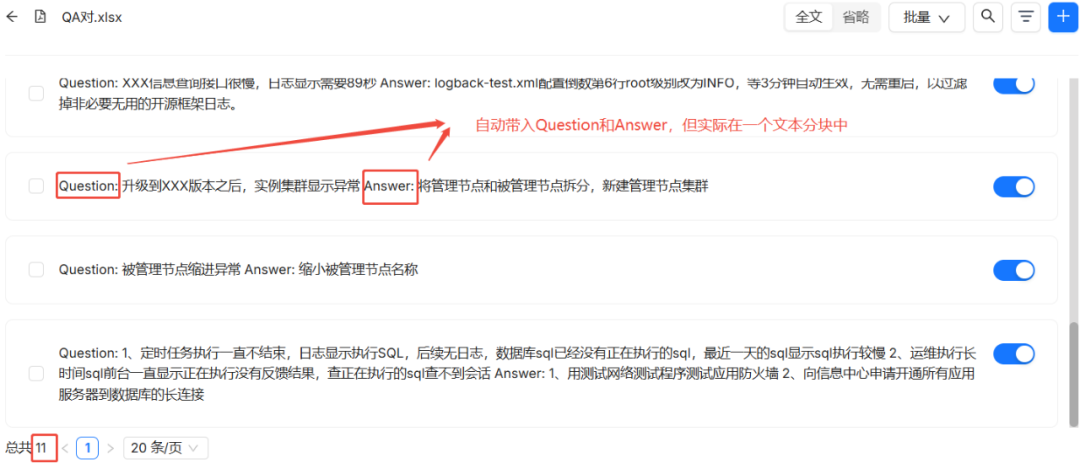
QA The method is a special-purpose form slice that recognizes the first two columns of the form as "Question" and "Answer" by default. If the previous O&M knowledge form is used directly for testing.RAGFlow Only the "Product" and "Region" columns will be extracted, ignoring all the rest of the information.
For accurate testing, we prepare a standard QA format form with only two columns, "Problem Description" and "Solution".
go through QA After the method is sliced, each line is also sliced into a block and automatically prefixed with "Question:" and "Answer:".
Comparison Summary of Two Form Slicing Methods
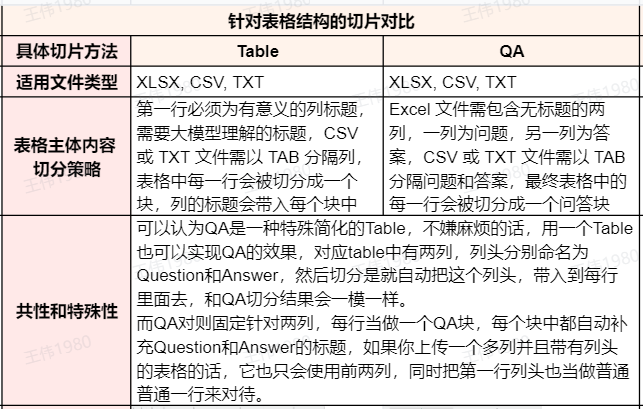
A deeper analysis reveals thatQA Methods are essentially TABLE A simplified special case of the method. The user is completely free to use the TABLE method implementation QA The effect of the table is simply to name the two columns "Question" and "Answer".
In practice, if a knowledge base requires semantic retrieval based on multi-dimensional information such as problem description, cause, solution, etc., theTABLE This approach is preferable. If the search scenario is strictly limited to "question-answer" pairs, and you want to utilize product, region, etc. information for precise filtering, then a better architecture would be to use the QA The method slices the Q&A content and also stores information such as products, regions, etc. in the metadata (Metadata) of the block.
However, in RAGFlow In the tests, it was found that the system design only supports metadata at the Document level, but not at the more granular Chunk level. It also seems to lack direct parameters for metadata-based filtering in its retrieval API. This is a significant limitation when building complex RAG systems, and one of the reasons that drove the team to consider developing their own knowledge base dock.
Other special slicing methods
RAGFlow A number of scenario-specific slicing methods are also provided:
- One: Does not do any slicing and treats the entire document as a single block.
- Resume:: Structured parsing of resumes to extract key information.
- Paper: Extract abstracts, authors, chapters, etc. for the paper format.
- Presentation: For PPT or PDF converted from PPT, convert each page into a separate block containing page screenshots and extracted text content.
PRESENTATION The test results of the method are as follows:
Beyond Slicing: Deep Considerations for RAG Engineering
(go ahead and do it) without hesitating RAGFlow Rich slicing tools are provided, but a production-grade RAG system is much more than that. The choice of an in-house knowledge base solution is usually based on deeper engineering needs:
- Customized Slicing Logic: Business scenarios often require highly customized slicing rules, e.g., for code repositories, data dictionaries, or format-specific internal knowledge, which is difficult to cover with on-premises approaches.
- Fine-grained metadata management:: As mentioned earlier, attaching rich metadata (e.g., version, source, responsible person, business tag) to each knowledge block and supporting efficient filtering is central to enabling accurate retrieval, focusing scope, and improving efficiency.
- Version control and lifecycle management of knowledge bases: Knowledge bases in production environments need to have well-established workflows. When knowledge is added or updated, it must be tested and validated to ensure that it does not affect the stability and accuracy of the online service before it is finally released safely.
- Knowledge refinement and enhancement: The RAG system also needs to process the original knowledge, e.g., generating summaries, constructing knowledge graph relationships, adding synonym extensions, etc., and record the association of this derived knowledge with the original knowledge for effective tracking and synchronization in case of source changes.
Together, these complex engineering challenges form the path from a basic RAG prototype to a reliable and maintainable enterprise-class knowledge service.

































