

When building Retrieval Augmented Generation (RAG) systems, developers often encounter the following confusing scenarios:
- Table headers for cross-page tables are left on the previous page, causing data to become unrelated.
- The model confidently gives complete errors in the face of blurry scans.
- The summation symbol "Σ" in a mathematical formula was incorrectly recognized as the letter "E".
- Watermarks or footnotes in documents are extracted as if they were body content, interfering with the accuracy of the information.
When the system fails to give the right answer, it may be too early to blame the problem directly on the Large Language Model (LLM). In most cases, the root of the problem lies in the failure of the initial step of document parsing.
Imagine an application scenario in the pharmaceutical domain. A PDF document documenting adverse drug reactions is typically laid out in a two-column layout with floating text boxes between pages. If parsed using an open source tool that claims a text extraction accuracy of up to 99%, the following fragmented results may be obtained:
第一页末尾:...注意事项(不完整)
第二页开头:特殊人群用药...(无上下文)
在 RAG When the system indexes, the two text segments, which are not semantically related, are cut into different chunks. When a user queries "Contraindications to the use of drug X in patients with hepatic insufficiency", the system may retrieve only the paragraph containing the keyword "contraindications". However, since the key contextual heading "OCK for special populations" is missing from the paragraph, the model cannot provide a complete and accurate answer.
This is a good indication that the quality of document parsing directly determines the quality of the RAG The upper limit of system performance.
Why is document parsing so complicated?
Document parsing is not a single algorithmic tool, but a complex set of solutions. Its complexity stems from a combination of challenges in the following multiple dimensions:
- file format: PDF, Word, Excel, PPT, Markdown and other formats are handled in different ways.
- Business: Unique layout styles for different documents such as academic papers, business reports, and financial statements.
- language type (in a classification): The recognition of different languages needs to rely on the corresponding corpus for model training.
- documentation element: Accurate reduction of elements such as paragraphs, headings, tables, formulas, corners, etc., is an important element that helps to
LLMThe key to understanding the hierarchical structure of an essay. - page layout: Layouts such as single-column, two-column, and mixed multi-column have a direct impact on the correct restoration of the reading order.
- Image content: Text
OCR, handwriting recognition, image resolution optimization, etc., especially in the scene of mixed text and graphics. - table structure: The complex structure of merged cells, page spanning, nesting, etc. in tables makes parsing them different from both text and images.
- additional capability: While intelligent chunking is not the job of parsing, high-quality chunking, especially for very large tables, can significantly improve Q&A results.
No single tool can excel in all of the above dimensions. Therefore, choosing an open source tool without thinking about it often leads to losing sight of one or the other and making it difficult to meet the needs of a high-quality application.
How to scientifically evaluate document parsing tools?
Since there is no perfect universal tool, how to evaluate the optimal choice in a specific scenario? A research result from the Shanghai Artificial Intelligence Laboratory provides a reference for this. The research, which has been recognized by the top computer vision conference CVPR 2024 Received research, launched a study specifically designed to evaluate the PDF Benchmarking of document parsing capabilities -OmniDocBench。
OmniDocBench From 200,000 PDF The visual features are extracted from the documents, and 6000 pages with significant differentiation are filtered out through cluster analysis, and 981 of them are finally fine-tuned for annotation. The annotation dimensions are very rich, covering layout bounding boxes, layout attributes, reading order and hierarchical relationships, etc. It is especially friendly to annotate the relevance of cross-page content.
In terms of assessment indicators.OmniDocBench For different dimensions such as text, tables, formulas and reading order, Normalized Edit Distance (NED), Tree Edit Distance Based Similarity (TEDS) and BLEU and many other algorithms to ensure that the assessment is comprehensive and fair.
Who are the leaders under each dimension?
OmniDocBench The evaluation report reveals an interesting trend.

(Source: https://arxiv.org/abs/2402.07626)
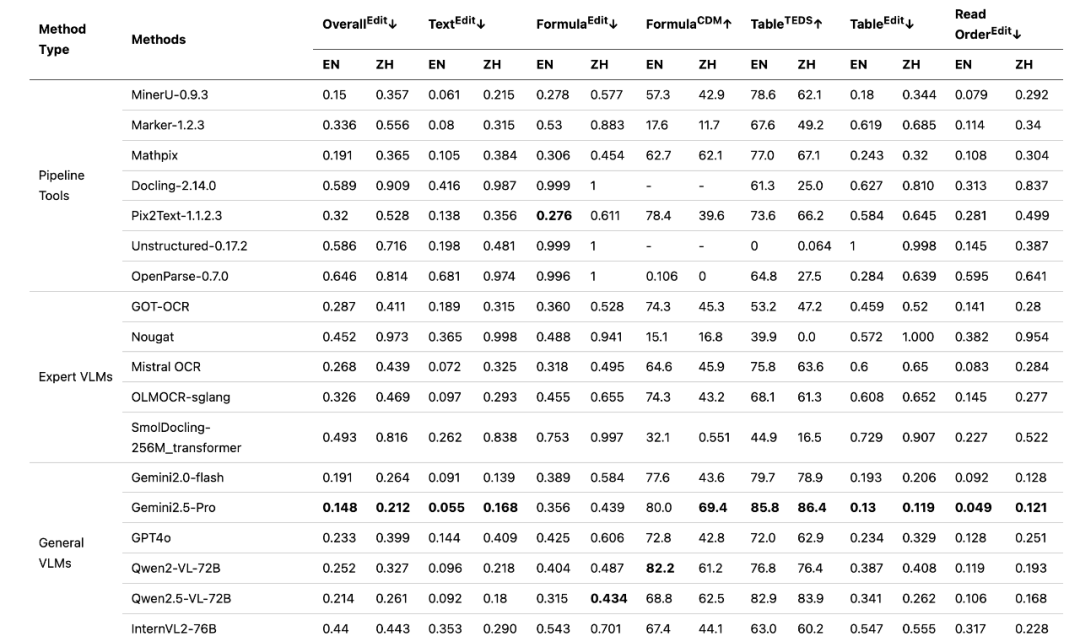
(Source: https://github.com/opendatalab/OmniDocBench/blob/main/README_zh-CN.md)
In the early thesis graphs of the project, various types of traditional document parsing tools competed with each other on different dimensions. However, when generalized visual macromodels (e.g. Gemini 1.5 Pro) was included in the review, its strong overall capabilities enabled it to achieve a leading position in every metric.
This advantage stems from Gemini Native multimodal macromodels such as these are able to process image and text information end-to-end to better understand the overall layout and semantics of a document. But this powerful capability comes with a high cost.
以 Gemini 1.5 Pro For example, although it accurately recognizes scribbled handwriting, it still shows significant parsing errors when dealing with a complex table containing multiple merged cells and corner labels.
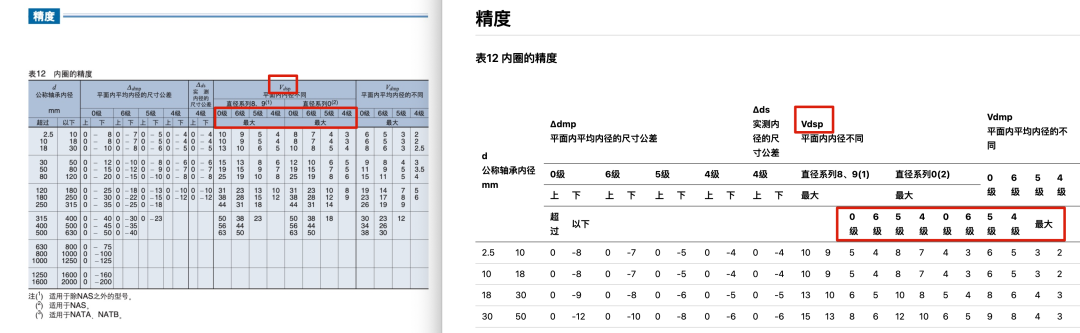
(Use Gemini 1.5 Pro Examples of errors when parsing complex tables)
More critical is the issue of cost. Just parsing this page PDFThe cost was about RMB 1.2 yuan. The main source of the cost is the model output of Token volume, which is a huge overhead for organizations that need to process documents on a large scale.
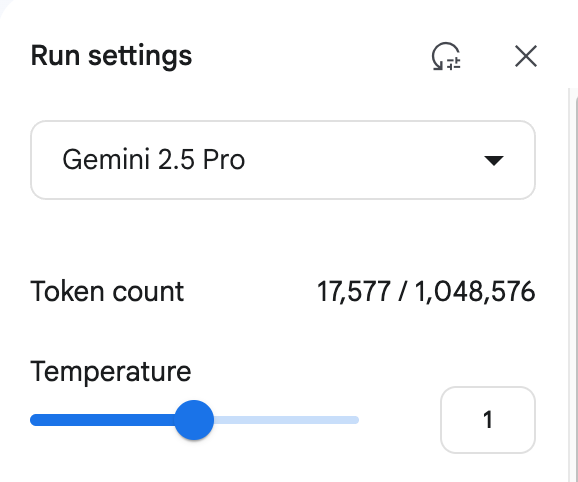
(Use Gemini 1.5 Pro (Example of cost consumption for parsing a document)
Therefore.Gemini Not a one-size-fits-all antidote for all scenarios. In the Gemini Beyond that, the industry has unstructured.io、Marker 和 PyMuPDF and many other excellent open source or commercial solutions that may be more advantageous for specific tasks and cost control. The right choice starts with a clear definition of the application scenario and the need to find a balance between performance, cost and specific needs.
Practical advice
In building or optimizing RAG When the system, developers can refer to the following steps to overcome the problem of document parsing:
- Diagnostic Documentation Library: Review your documents to identify the toughest contracts, reports, or scans, and make clear whether the main challenges in them come from complex tables, mathematical formulas, or special page layouts.
- Targeted validation:: Comparison
OmniDocBenchor other review reports, select one or two tools that excel in specific dimensions for targeted validation to find the solution that best fits your business needs. - Keeping an eye on the frontiers: Document parsing technology is still evolving rapidly, stay tuned!
OmniDocBenchThese kinds of benchmark studies and emerging parsing tools can help you continuously optimize system performance.
Related Research
OmniDocBenchThesis: https://arxiv.org/abs/2402.07626





































