



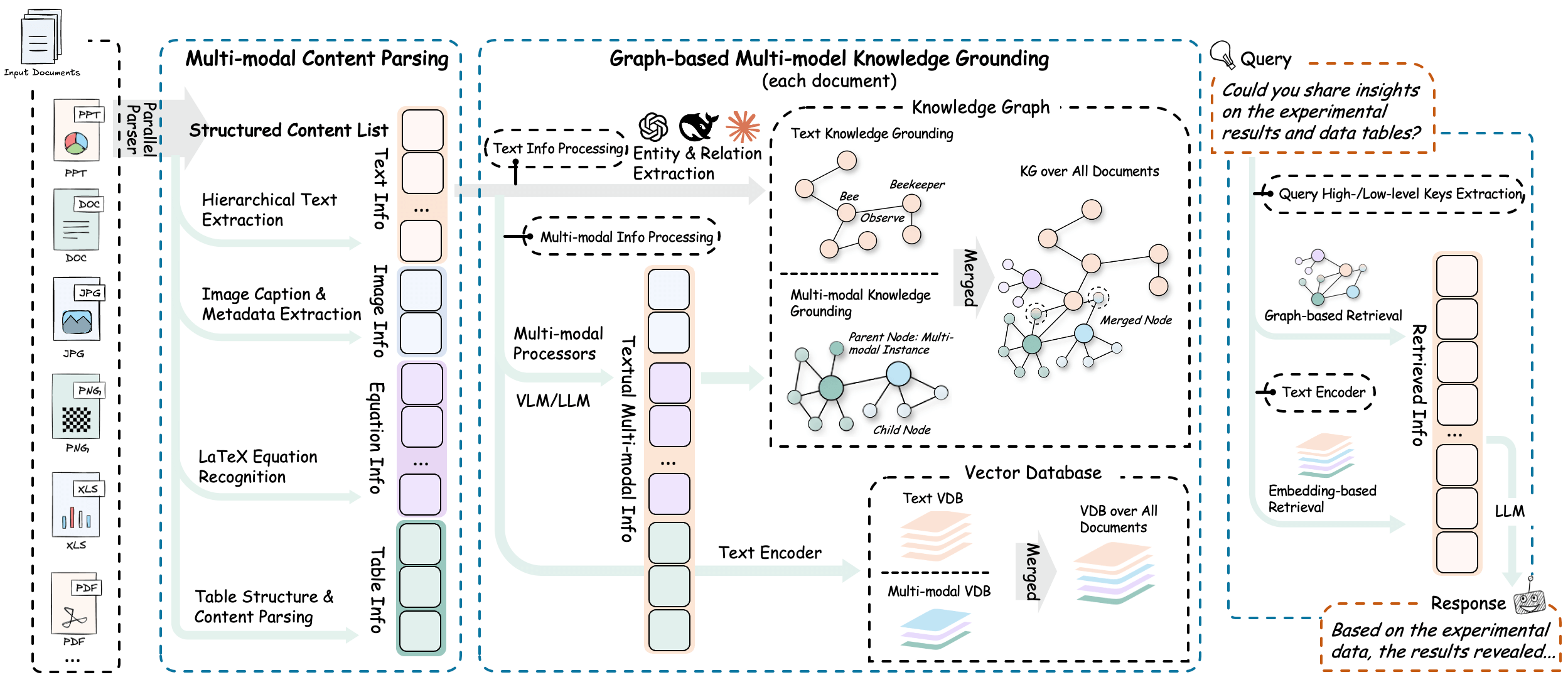
RAG-Anything is a program based on LightRAG Fully integrated multimodal document processing built in RAG System. Most of the traditional question and answer systems (RAG) can only deal with plain text content, but the documents we come into contact with on a daily basis, such as PDFs, Word documents or presentations, often contain multiple types of content, such as text, images, tables, formulas, etc. If only text is extracted, a lot of key information is lost. If only text is extracted, a lot of key information will be lost.RAG-Anything solves this problem by completely parsing these complex documents that contain multiple contents, whether they are text, images, tables or mathematical formulas, and accurately recognizes and understands them. It disassembles and analyzes all the elements in the document, and then builds a knowledge graph so that when you ask a question, the system not only understands the text, but also reads the content of the images and analyzes the data in the table. In this way, it can give a more comprehensive and accurate answer based on all the information in the document. This system is particularly suitable for dealing with documents with diverse information such as academic papers, technical manuals, and financial reports.
Function List
- Integrated treatment process: The entire process is complete and automated, from document uploading, parsing, to the final intelligent question and answer.
- Support for multiple file formats: Users can upload PDF, Word, PPT, Excel, images and many other common formats for processing.
- Specialized content analyzer: The system has built-in tools dedicated to recognizing and understanding different content such as images, tables, mathematical formulas, and more.
- Building a multimodal knowledge graph: It automatically extracts key information from documents and establishes links between text, images, tables and other content to form a knowledge network.
- Flexible processing models: Users can either choose to let the system parse the entire document automatically, or give the system direct access to what they have already organized.
- Hybrid Intelligent Search: When looking for answers, the system combines both keyword matching and contextual understanding to locate information more precisely.
- Visual Language Model Enhanced Query: When a user asks a question that involves a picture, the system will automatically invoke a visual model to analyze the picture content and realize a combined graphic answer.
Using Help
RAG-Anything is a powerful tool that parses documents containing text, images, tables, and much more, and allows you to interact with these documents by asking questions. Below is a detailed installation and usage procedure.
I. Installation
There are two ways to install RAG-Anything, and the first one is recommended because it is simpler.
Way 1: Install directly from PyPI (recommended)
This is the quickest way to install. Open your terminal or command line tool and enter the following command:
# 基础安装
pip install raganything
This base command only installs the core functionality. Modern documents come in a variety of formats, and in order for it to handle more types of files, you can install additional feature packs as needed.
- If you want it to handle all supported file types (recommended):
pip install 'raganything[all]' - If you only need to work with image formats (e.g. BMP, TIFF, GIF, etc.):
pip install 'raganything[image]' - If you only need to work with plain text files (e.g. TXT, MD):
pip install 'raganything[text]'
Way 2: Install from source code
If you want to study its code or do secondary development, this is the way to go.
- First, clone the code from GitHub to your computer:
git clone https://github.com/HKUDS/RAG-Anything.git - Go to the project catalog:
cd RAG-Anything - Then install it via pip:
pip install -e . - Again, use this command if you need to support all file formats:
pip install -e '.[all]'
II. Environmental configuration
1. Install LibreOffice
RAG-Anything works with Office documents (e.g. .docx, .pptx, .xlsx) with the help of LibreOffice, a free office program. You must first install it on your operating system.
- Windows: Go to LibreOffice official websiteDownload and install.
- macOS: It's easy to install using Homebrew, the command is
brew install --cask libreoffice。 - Ubuntu/Debian:: Use of commands
sudo apt-get install libreoffice。
2. Configure the API key
RAG-Anything needs to call a large language model (LLM), such as OpenAI's GPT family of models, when understanding content and generating answers. You need an API key.
In your project folder, create a file named .env file, then copy the following in and replace it with your own key information.
OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxx"
# 如果你使用代理或者第三方服务,还需要配置这个地址
OPENAI_BASE_URL="https://api.your-proxy.com/v1"
III. Methods of use
Below we walk through a complete example of how to process a document and ask questions using RAG-Anything.
1. Preparatory work
First, make sure you have installed RAG-Anything and configured the API key. Then, prepare a document that you want to work with, such as a file named report.pdf of the document.
2. Writing code
Create a Python file, for example main.py, and then copy the following code into it. This code demonstrates the complete process from configuring and processing documents to asking questions.
import asyncio
from raganything import RAGAnything, RAGAnythingConfig
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
# 异步函数是现代Python中处理高并发任务的方式
async def main():
# 1. 设置你的API密钥和代理地址
api_key = "your-api-key" # 替换成你的 OpenAI API Key
base_url = "your-base-url" # 如果有代理,替换成你的代理地址
# 2. 配置 RAG-Anything 的工作方式
config = RAGAnythingConfig(
working_dir="./rag_storage", # 指定一个文件夹,用来存放处理后的数据
parser="mineru", # 使用mineru解析器
parse_method="auto", # 自动判断解析方式
enable_image_processing=True, # 启用图片处理
enable_table_processing=True, # 启用表格处理
)
# 3. 定义与大语言模型交互的函数
# 文本模型,用于生成回答
def llm_model_func(prompt, **kwargs):
return openai_complete_if_cache(
"gpt-4o-mini",
prompt,
api_key=api_key,
base_url=base_url,
**kwargs,
)
# 视觉模型,用于理解图片内容
def vision_model_func(prompt, image_data=None, **kwargs):
return openai_complete_if_cache(
"gpt-4o",
"",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}]}],
api_key=api_key,
base_url=base_url,
**kwargs,
)
# 嵌入模型,用于将文本转换成向量,方便计算机理解和检索
embedding_func = EmbeddingFunc(
embedding_dim=3072,
func=lambda texts: openai_embed(
texts, model="text-embedding-3-large", api_key=api_key, base_url=base_url
),
)
# 4. 初始化 RAG-Anything 系统
rag = RAGAnything(
config=config,
llm_model_func=llm_model_func,
vision_model_func=vision_model_func,
embedding_func=embedding_func,
)
# 5. 处理你的文档
# 将 "path/to/your/document.pdf" 替换成你自己的文件路径
await rag.process_document_complete(
file_path="path/to/your/document.pdf",
output_dir="./output"
)
# 6. 开始提问
print("文档处理完成,现在可以开始提问了。")
# 示例问题:一个纯文本问题
text_result = await rag.aquery(
"请总结一下这份文档的核心观点,并分析图表传达了哪些主要信息?",
mode="hybrid" # hybrid模式会结合多种方式检索,结果更准
)
print("问题的回答:", text_result)
if __name__ == "__main__":
asyncio.run(main())
3. Running the code
Change the code in the your-api-key、your-base-url 和 path/to/your/document.pdf Replace it with your own actual information. Then run this file in the terminal:
python main.py
The program will first download the required models and then start parsing the documents you specify. This process may last a few minutes, depending on the size and complexity of the document. Once the process is complete, it will print out the answers to the questions you have asked.
This example shows the core usage of RAG-Anything. It also supports more advanced features such as batch processing of entire folders of documents, passing in parsed content directly, or asking questions about specific images or tables, so you can check out the official documentation to explore these advanced uses.
application scenario
- academic research
When researchers read a large number of papers, they often need to deal with PDF files containing complex charts, mathematical formulas, and text.RAG-Anything can parse these papers completely, helping researchers to quickly locate key information, understand the charts of experimental results, and compare the data of different papers, which greatly improves the efficiency of literature review and data organization. - Enterprise Knowledge Management
Companies typically have a large number of technical manuals, financial reports, market analyses and presentations in-house. These documents are in different formats and have mixed contents. RAG-Anything creates a unified corporate knowledge base where employees can ask questions directly in natural language, such as "Check the chart of last year's third quarter's sales data" or "Show me the technical architecture diagram of XX product", and the system will find and present the relevant information precisely from different documents. The system can accurately find and present relevant information from different documents. - Financial and legal professions
Financial analysts and lawyers need to read lengthy reports and contract documents filled with tables of data, terms and conditions, and charts, and RAG-Anything helps them to make more accurate decisions by quickly extracting key data, identifying specific clauses in the contract, and analyzing the tables in the financial statements. - Education and learning
Students and teachers can use RAG-Anything to work with textbooks, courseware and learning materials. Students can upload a PDF of their courseware and then ask questions about the diagrams and concepts in it, and the system can provide detailed explanations. Teachers can also use it to quickly create Q&A materials or organize teaching resources from different sources.
QA
- How is RAG-Anything different from other common RAG tools?
The biggest difference is that RAG-Anything can handle multimodal content. Ordinary RAG tools usually can only extract and understand plain text in a document, ignoring non-text information such as pictures, tables, formulas, and so on. RAG-Anything, on the other hand, is specially designed to recognize such content. It can read pictures and parse table data, thus providing a more comprehensive understanding of the entire document, and thus providing more accurate and complete answers. - Why is it necessary to install LibreOffice when working with Office documents (Word, PPT)?
RAG-Anything itself does not directly parse the complex formatting of Office documents, but instead calls on LibreOffice, a powerful open source office software. It uses LibreOffice to convert files such as .docx, .pptx, etc. into an intermediate format that is more standardized and easier to work with before content extraction and analysis. So, LibreOffice is a front-end dependency for processing these files. - Is this tool free? Does it cost anything to use it?
The RAG-Anything project itself is open source and free, and you can freely download and use its code. However, it needs to call APIs for Large Language Model (LLM) and Embedding Model (EMM) during its operation, such as OpenAI's GPT-4o. These API services are usually charged on a per-use basis. So your cost comes mainly from the cost of calling these third-party APIs. - If I have handwritten formulas or unclear charts in my document, can it handle them?
The processing results depend on the clarity of the content. For printed math formulas and clear charts, it has a high recognition accuracy. However, if the charts are very blurry or the formulas are scribbled in handwriting, the OCR (Optical Character Recognition) module of the system may have difficulty in recognizing them accurately, which will affect the final comprehension and question-and-answer results.































