



Mira is a library of intelligent body AIs specialized for automated company research. All a user needs to do is provide a company's website URL, and Mira launches a system of multiple specialized AI intelligences working in tandem. These intelligences are responsible for discovering and crawling company website pages, analyzing LinkedIn public profiles, and integrating Google search results, respectively. They automatically extract key facts, check external sources, and ultimately generate a structured company profile. Each fact is accompanied by a clear source and confidence score to ensure transparency and reliability of the information.At the core of Mira is a framework-agnostic library that can be easily integrated into existing applications, data pipelines or custom workflows as an npm package. For ease of understanding and use, the project also provides a Next.js front-end application as a sample operator interface.
Function List
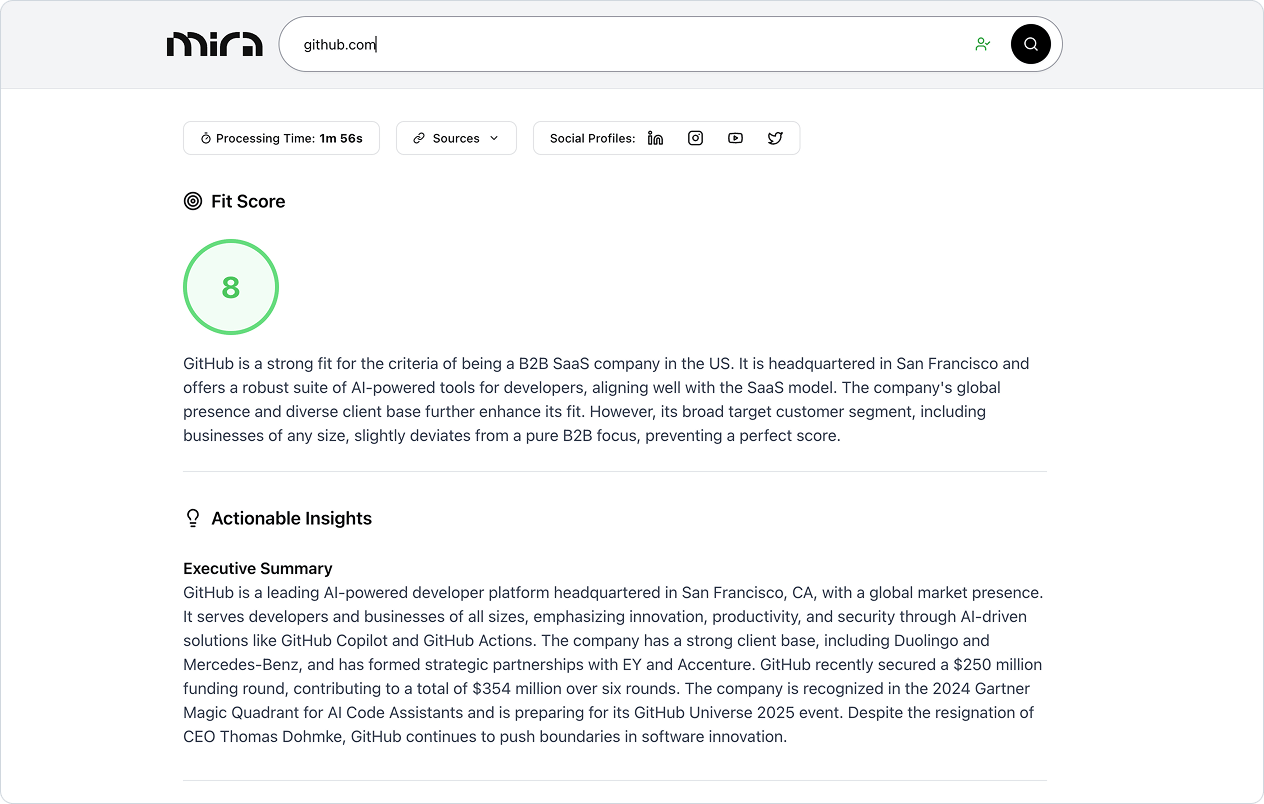
- multi-intelligent body architecture (MIBA): The system contains multiple specialized intelligences that handle company information discovery, intranet page crawling, Collage data collection, Google searches, and comprehensive analysis, finally merging the results into a unified company portrait.
- Flexible and customizable: Users can easily modify the behavior of the intelligences, the data points to be captured, and the Prompts to adapt them to specific workflows or research needs.
- Real-time progress events: During the execution of a research task, the system emits structured events that allow the user to track and display task progress in real time.
- Confidence scores and source attribution: Each piece of information extracted contains a confidence score and is clearly labeled with its source, ensuring the transparency of the findings.
- Company Standard Match: Support for evaluating target companies based on user-defined criteria, with match scores and detailed rationale for analysis.
- Built-in data collection service: Integrated services to handle web crawling, Google searches, data collection from Collage, and even automate cookie consent banners.
- Built-in business process harmonization: The system is able to automatically coordinate the tasks of individual intelligences, merge results and manage all data sources in a unified way.
- Composable core libraries: The core libraries are framework-agnostic and can be distributed as npm packages for easy use in any Node.js or TypeScript project.
- Sample front-end interface: The project provides a sample website based on Next.js that shows how to call the core library and provides a simple interface for running studies and viewing results.
Using Help
At its core, Mira is a powerful library, but the project also provides a complete front-end application that you can easily run and test in your local environment. You can use Mira in two ways.
1. Run the full application with front-end interface locally
This approach is best suited for developers who want to get a quick taste of Mira's features.
Environmental requirements:
- Node.js (version 18 or higher)
npm(usually installed with Node.js)- OpenAI API Key
- ScrapingBee API Key
Installation steps:
- Clone Code Repository
First, use thegitClone the project's code to your local computer:git clone https://github.com/dimimikadze/mira.git - Go to the project directory and install the dependencies
Go to the folder you just cloned and use thenpmInstall all dependent packages required by the project.cd mira npm install - Configuring Environment Variables
Sensitive information such as API keys need to be configured via environment variables. You need to create a.env.localfile. This file is located in thepackages/mira-frontend/Catalog.
You can quickly create and edit it by executing the following command in the project root directory:# 注意:请在项目根目录(mira/)下执行此命令 touch packages/mira-frontend/.env.localThen, open this file with a code editor and fill in your API key in the following format:
OPENAI_API_KEY=sk-xxxx SCRAPING_BEE_API_KEY=xxxxplease include
sk-xxxx和xxxxReplace the key with your own. - Running front-end applications
After completing the above steps, run the following command to start the development server:npm run dev:mira-frontendUpon successful startup, the terminal will display a local URL (usually the
http://localhost:3000). Open this URL in your browser and you'll be able to see the Mira interface and get started.
2. Use it as an NPM package in your project.
If you want to integrate Mira's automated research features into your own applications, you can use it directly as an npm package.
mounting:
In your Node.js or TypeScript project, install it with the following commandmira-aiCore library: "`bash
npm install mira-ai
**使用方法**:
安装后,你可以在你的代码中导入`researchCompany`函数来调用Mira的核心功能。下面是一个基本的使用示例:
```javascript
import { researchCompany } from "mira-ai";
async function runResearch() {
// 配置API密钥
const config = {
apiKeys: {
openaiApiKey: process.env.OPENAI_API_KEY,
scrapingBeeApiKey: process.env.SCRAPING_BEE_API_KEY,
},
};
// 定义研究参数和回调函数
const options = {
// 你可以提供一个自定义的公司标准,让AI进行评估
companyCriteria: "B2B SaaS领域的公司,且员工人数超过50人",
// onProgress是一个回调函数,用于接收实时进度更新
onProgress: (event) => {
console.log("实时进度事件:", event);
},
};
try {
// 调用函数,传入公司网址、配置和选项
const result = await researchCompany("https://www.example.com", config, options);
// 打印最终的研究结果
console.log(result);
} catch (error) {
console.error("研究过程中发生错误:", error);
}
}
// 确保在运行前已设置好环境变量 OPENAI_API_KEY 和 SCRAPING_BEE_API_KEY
runResearch();
In this example, theresearchCompanyThe function takes three arguments: the company URL, a configuration object containing the API key, and an optional parameter object. This is accomplished through theonProgresscallbacks, you can build a real-time user interface to show research progress.
application scenario
- Sales Team
Sales teams can utilize Mira to automate the lead generation process. They can define ideal customer profiles as screening criteria and batch research a large number of companies to build a highly accurate list of target customers. Detailed company information in the research report, such as technology stack, recent news, or funding, can help salespeople conduct highly personalized outreach campaigns that can significantly increase conversion rates. - investor
Investors, especially VCs, need to screen a large number of startups on a daily basis, and Mira can help them quickly assess the fundamentals of a range of companies. Investors can set their own investment criteria (e.g., industry, company size, founder's background, etc.) and let Mira do the initial screening and research on the list of target companies, so that they can focus on the most promising investment opportunities. - Recruitment Commissioner
Recruiters can use Mira to build a list of target companies to find candidates more accurately. By setting specific filters, such as "companies that use Rust as their primary development language," recruiters can identify companies that meet the requirements and tailor their recruiting strategy to the company's details to more effectively attract the right talent. - Market researcher
Market researchers need to conduct side-by-side comparative analyses of multiple companies within a specific industry, and Mira ensures that all company profiles generated follow a uniform format and data structure, dramatically improving data consistency and comparability. Researchers can process multiple companies within an industry at once and then review and analyze the results in one unified view, saving a great deal of time in manually collecting and organizing data.
QA
- What is Mira? How is it different from a regular chatbot?
Mira is an AI library of intelligent bodies used to automate company research. It's not a chatbot that passively answers questions, but a system of multiple AI intelligences that actively collaborate. You give it a company URL and it will actively go to multiple channels such as the company's official website, Collabo and Google search to collect and organize information and ultimately generate a structured company report. - What API keys are required to use Mira?
Mira requires two API keys for external services for proper operation: aOPENAI_API_KEYthat is used to drive the reasoning and coordination capabilities of the AI intelligences; the other is theSCRAPING_BEE_API_KEY, which is used to perform web crawls and Google searches to avoid being blocked by the site. - Can I customize what information Mira collects?
Yes. Mira is designed to be flexible, allowing users to easily customize the intelligences, the data points to be collected, and the prompts (Prompts) for analyzing the questions. You can tailor its workflow and output to your specific research needs. - Can Mira be integrated into my existing Customer Relationship Management (CRM) system?
Yes. At its core, Mira is a standalone library that can be easily integrated into any external system, including CRMs, data analytics platforms, or internal workflows via API calls. This way, you can automatically import Mira-generated research reports into your CRM, adding rich contextual information to sales leads.































