



RAGLight ist eine leichtgewichtige, modulare Python-Bibliothek, die Retrieval Augmented Generation (RAG) ermöglicht. Mit Unterstützung für mehrere Sprachmodelle, eingebettete Modelle und Vektorspeicher ist RAGLight ideal für Entwickler, um schnell kontextbewusste KI-Anwendungen zu erstellen. RAGLight wurde mit Blick auf Einfachheit und Flexibilität entwickelt und kann problemlos Daten aus lokalen Ordnern oder GitHub-Repositories integrieren, um präzise Antworten zu generieren. Ollama oder LMStudio, unterstützt lokalisierte Einsätze und eignet sich für datenschutz- und kostensensible Projekte.
Funktionsliste
- Mehrere Datenquellen werden unterstützt: Wissensdatenbanken können aus lokalen Ordnern (z.B. PDF, Textdateien) oder GitHub-Repositories importiert werden.
- Modularisierung RAG Pipeline: Kombiniert Dokumentenrecherche und Spracherzeugung mit Unterstützung für Standard RAG, Agentic RAG und RAT (Retrieval Augmented Thinking) Modi.
- Flexible Modellintegration: Unterstützt Ollama- und LMStudio-Modelle für große Sprachen wie
llama3。 - Effiziente Vektorspeicherung: Generieren Sie Dokumentvektoren mit Chroma- oder HuggingFace-Einbettungsmodellen, um schnelle Ähnlichkeitssuchen zu unterstützen.
- Benutzerdefinierte Konfiguration: Ermöglicht dem Benutzer, das Einbettungsmodell, die Vektorspeicherpfade und die Abrufparameter anzupassen (z. B.
k(Wert). - Automatisieren Sie die Dokumentenverarbeitung: Extrahieren und indexieren Sie automatisch den Inhalt von Dokumenten aus bestimmten Quellen und vereinfachen Sie so den Aufbau von Wissensdatenbanken.
Hilfe verwenden
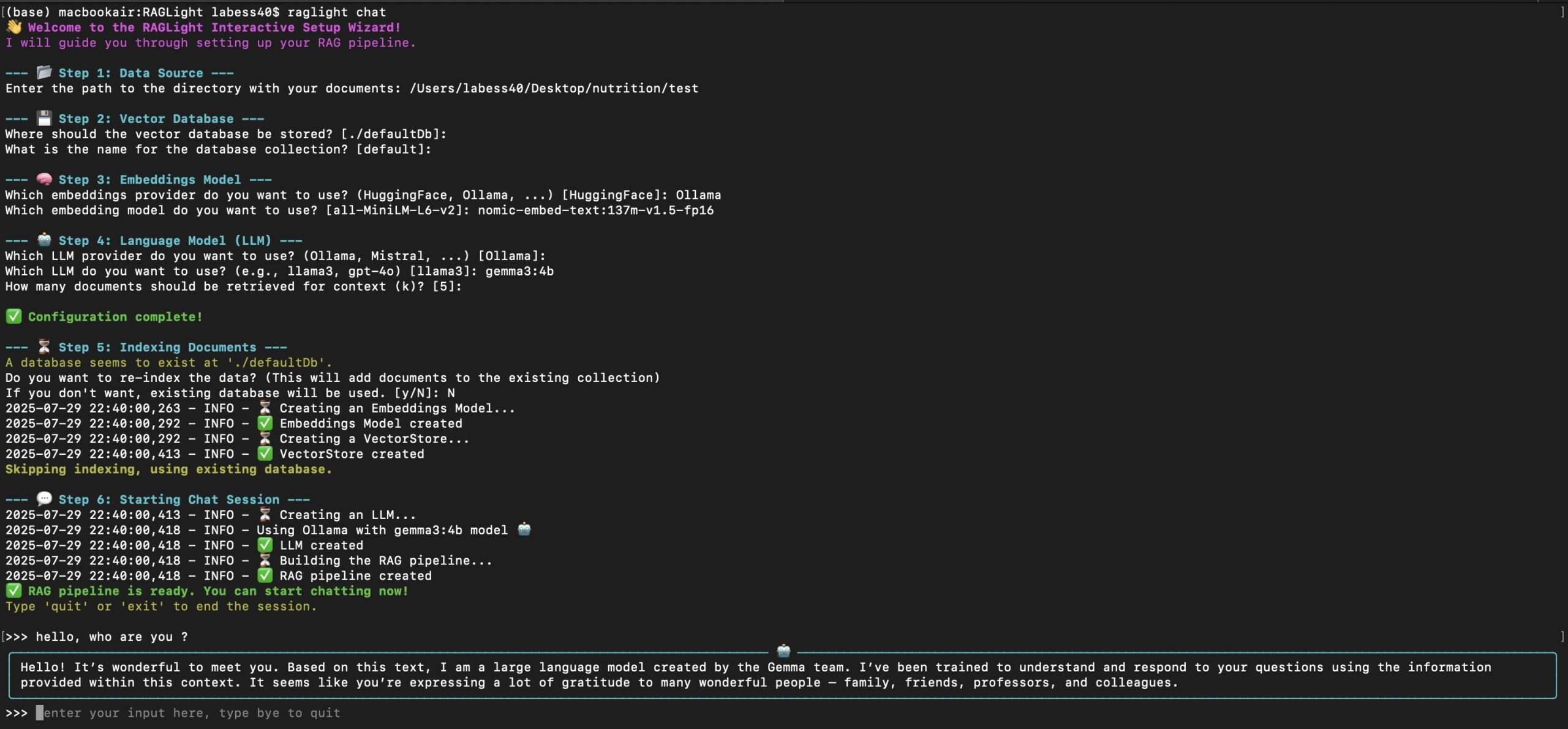
Einbauverfahren
Die Installation und Nutzung von RAGLight setzt eine Python-Umgebung und ein laufendes Ollama oder LMStudio voraus, die im Folgenden detailliert beschrieben werden:
- Installation von Python und Abhängigkeiten
Stellen Sie sicher, dass Python 3.8 oder höher auf Ihrem System installiert ist. Verwenden Sie den folgenden Befehl, um RAGLight zu installieren:pip install raglightWenn Sie eingebettete HuggingFace-Modelle verwenden, müssen Sie zusätzliche Abhängigkeiten installieren:
pip install sentence-transformers - Installieren und Ausführen von Ollama oder LMStudio
- Laden Sie Ollama (https://ollama.ai) oder LMStudio herunter und installieren Sie es.
- Ziehen von Modellen in Ollama, zum Beispiel:
ollama pull llama3 - Stellen Sie sicher, dass das Modell in Ollama oder LMStudio geladen ist und läuft.
- Konfiguration der Umgebung
Erstellen Sie einen Projektordner, um die Daten der Wissensdatenbank vorzubereiten (z. B. einen PDF-Ordner oder die URL des GitHub-Repository). Stellen Sie sicher, dass Sie eine gute Internetverbindung haben, um auf GitHub oder HuggingFace zuzugreifen.
Erstellen einer einfachen RAG-Pipeline mit RAGLight
RAGLight bietet eine saubere API zum Aufbau von RAG-Pipelines. Im Folgenden finden Sie ein einfaches Beispiel für den Aufbau einer Wissensbasis und die Generierung von Antworten aus lokalen Ordnern und GitHub-Repositories:
from raglight.rag.simple_rag_api import RAGPipeline
from raglight.models.data_source_model import FolderSource, GitHubSource
from raglight.config.settings import Settings
Settings.setup_logging()
# 定义知识库来源
knowledge_base = [
FolderSource(path="/path/to/your/folder/knowledge_base"),
GitHubSource(url="https://github.com/Bessouat40/RAGLight")
]
# 初始化 RAG 管道
pipeline = RAGPipeline(
knowledge_base=knowledge_base,
model_name="llama3",
provider=Settings.OLLAMA,
k=5
)
# 构建管道(处理文档并创建向量存储)
pipeline.build()
# 生成回答
response = pipeline.generate("如何使用 RAGLight 创建一个简单的 RAG 管道?")
print(response)
Featured Function Bedienung
- Unterstützt mehrere Datenquellen
Mit RAGLight können Benutzer Daten aus lokalen Ordnern oder GitHub-Repositories importieren.- Lokaler Ordner: PDF- oder Textdateien in einem bestimmten Ordner ablegen, z. B.
/path/to/knowledge_base。 - GitHub-Repositories: Geben Sie die Repository-URL an (z. B.
https://github.com/Bessouat40/RAGLight), extrahiert RAGLight automatisch Dokumente aus dem Repository.
Beispielkonfiguration:
knowledge_base = [ FolderSource(path="/data/knowledge_base"), GitHubSource(url="https://github.com/Bessouat40/RAGLight") ] - Lokaler Ordner: PDF- oder Textdateien in einem bestimmten Ordner ablegen, z. B.
- Standard RAG-Rohre
Die Standard-RAG-Pipeline kombiniert Dokumentensuche und -generierung. Nachdem ein Benutzer eine Anfrage eingegeben hat, konvertiert RAGLight die Anfrage in einen Vektor, findet relevante Dokumentfragmente durch eine Ähnlichkeitssuche und gibt diese Fragmente als Kontext in den LLM ein, um eine Antwort zu generieren.
Betriebsverfahren:- Initialisierung
RAGPipelineund spezifizieren die Wissensbasis, Modelle undkWert (Anzahl der abgerufenen Dokumente). - Aufforderungen
pipeline.build()Verarbeitet Dokumente und erzeugt Vektorspeicher. - ausnutzen
pipeline.generate("查询")Antworten erhalten.
- Initialisierung
- Agentische RAG- und RAT-Modi
- Agentic RAG: durch
AgenticRAGPipelineImplementierung, wobei intelligente Körperfunktionen zur Unterstützung von mehrstufigen Schlussfolgerungen und dynamischer Anpassung von Abrufstrategien hinzugefügt werden.
Beispiel:from raglight.rag.simple_agentic_rag_api import AgenticRAGPipeline from raglight.config.agentic_rag_config import SimpleAgenticRAGConfig config = SimpleAgenticRAGConfig(k=5, max_steps=4) pipeline = AgenticRAGPipeline(knowledge_base=knowledge_base, config=config) pipeline.build() response = pipeline.generate("如何优化 RAGLight 的检索效率?") print(response) - RAT (Retrieval Augmented Thinking): durch
RATPipelineRealisierung, zusätzliche Reflexionsschritte (reflectionParameter), um die Logik und Genauigkeit der Antworten zu verbessern.
Beispiel:from raglight.rat.simple_rat_api import RATPipeline pipeline = RATPipeline( knowledge_base=knowledge_base, model_name="llama3", reasoning_model_name="deepseek-r1:1.5b", reflection=2, provider=Settings.OLLAMA ) pipeline.build() response = pipeline.generate("如何简化 RAGLight 的配置?") print(response)
- Agentic RAG: durch
- Benutzerdefinierte Vektorspeicherung
RAGLight verwendet Chroma als Standard-Vektorspeicher und unterstützt HuggingFace-Einbettungsmodelle (z.B.all-MiniLM-L6-v2). Benutzerdefinierbare Speicherpfade und Sammlungsnamen:from raglight.config.vector_store_config import VectorStoreConfig vector_store_config = VectorStoreConfig( embedding_model="all-MiniLM-L6-v2", provider=Settings.HUGGINGFACE, database=Settings.CHROMA, persist_directory="./defaultDb", collection_name="my_collection" )
Vorsichtsmaßnahmen bei der Handhabung
- Stellen Sie sicher, dass das Ollama- oder LMStudio-Laufzeitmodell geladen ist, andernfalls wird ein Fehler gemeldet.
- Der lokale Ordnerpfad sollte gültige Dokumente enthalten (z. B. PDF, TXT) und das GitHub-Repository sollte öffentlich zugänglich sein.
- anpassen
kWert, um die Anzahl der abgerufenen Dokumente zu steuern.k=5In der Regel ist es eine Entscheidung, die ein Gleichgewicht zwischen Effizienz und Genauigkeit herstellt. - Wenn Sie das eingebettete HuggingFace-Modell verwenden, stellen Sie sicher, dass die HuggingFace-API über das Netzwerk zugänglich ist.
Anwendungsszenario
- akademische Forschung
Forscher können PDF-Dokumente in einen lokalen Ordner importieren und RAGLight verwenden, um die Literatur schnell zu durchsuchen und Zusammenfassungen zu erstellen oder Fragen zu beantworten. Geben Sie zum Beispiel "recent advances in a field" ein, um kontextbezogene Antworten auf relevante Artikel zu erhalten. - Wissensdatenbank für Unternehmen
Unternehmen können interne Dokumente (z.B. technische Handbücher, FAQs) in RAGLight importieren, um intelligente Q&A-Systeme aufzubauen. Nachdem die Mitarbeiter Fragen eingegeben haben, ruft das System genaue Antworten aus den Dokumenten ab und generiert sie. - Entwickler-Tools
Entwickler können die Codedokumentation von GitHub-Repositories als Wissensdatenbank verwenden, um schnell die API-Verwendung oder Codeschnipsel nachzuschlagen. Geben Sie zum Beispiel ein, wie eine Funktion aufgerufen wird, um die Dokumentation zu erhalten. - Pädagogische Hilfsmittel
Lehrende oder Lernende können Lehrbücher oder Kursnotizen in RAGLight importieren, um gezielte Antworten oder Zusammenfassungen des Gelernten zu erstellen. Geben Sie zum Beispiel "Erklären Sie ein Konzept" ein, um auf relevante Inhalte aus dem Lehrbuch zuzugreifen.
QA
- Welche Sprachmodelle werden von RAGLight unterstützt?
RAGLight unterstützt die von Ollama und LMStudio bereitgestellten Modelle, wie z.B.llama3、deepseek-r1:1.5busw. Der Benutzer muss das Modell in Ollama oder LMStudio vorladen. - Wie kann ich eine benutzerdefinierte Datenquelle hinzufügen?
ausnutzenFolderSourceGeben Sie den Pfad zu einem lokalen Ordner an, oderGitHubSourceGeben Sie eine öffentliche GitHub-Repository-URL an. Stellen Sie sicher, dass der Pfad gültig ist und das Dateiformat unterstützt wird (z. B. PDF, TXT). - Wie lässt sich die Suchgenauigkeit optimieren?
ErhöhungkWerte, um mehr Dokumente abzurufen, oder verwenden Sie den RAT-Modus, um die Reflexion zu aktivieren. Wählen Sie ein hochwertiges Einbettungsmodell (z. B.all-MiniLM-L6-v2) verbessert ebenfalls die Genauigkeit. - Unterstützt es die Cloud-Bereitstellung?
RAGLight ist in erster Linie für den lokalen Einsatz konzipiert und muss mit Ollama oder LMStudio ausgeführt werden. Es unterstützt nicht direkt die Cloud, kann aber über Containerisierung (z. B. Docker) bereitgestellt werden.
























