

Beim Aufbau von Retrieval Augmented Generation (RAG)-Systemen stoßen Entwickler häufig auf die folgenden verwirrenden Szenarien:
- Tabellenköpfe für seitenübergreifende Tabellen werden auf der vorherigen Seite belassen, was dazu führt, dass die Daten nicht miteinander in Beziehung stehen.
- Das Modell gibt auch bei unscharfen Scans zuverlässig vollständige Fehler an.
- Das Summensymbol "Σ" in einer mathematischen Formel wurde fälschlicherweise als der Buchstabe "E" erkannt.
- Wasserzeichen oder Fußnoten in Dokumenten werden so extrahiert, als ob es sich um Textinhalte handelte, was die Genauigkeit der Informationen beeinträchtigt.
Wenn das System nicht die richtige Antwort gibt, kann es zu früh sein, das Problem direkt auf das Large Language Model (LLM) zu schieben. In den meisten Fällen liegt die Wurzel des Problems im Versagen des ersten Schritts des Dokumentenparsings.
Stellen Sie sich ein Anwendungsszenario aus dem pharmazeutischen Bereich vor. Ein PDF-Dokument, das unerwünschte Arzneimittelwirkungen dokumentiert, ist in der Regel in einem zweispaltigen Layout mit fließenden Textfeldern zwischen den Seiten angelegt. Wenn es mit einem Open-Source-Tool geparst wird, das eine Textextraktionsgenauigkeit von bis zu 99% angibt, können die folgenden fragmentierten Ergebnisse erhalten werden:
第一页末尾:...注意事项(不完整)
第二页开头:特殊人群用药...(无上下文)
在 RAG Bei der Indizierung werden diese beiden semantisch nicht zusammenhängenden Textsegmente in verschiedene Abschnitte zerlegt. Wenn ein Benutzer die Frage "Kontraindikationen für die Verwendung von Medikament X bei Patienten mit Leberinsuffizienz" stellt, kann das System nur den Absatz abrufen, der das Schlüsselwort "Kontraindikationen" enthält. Da jedoch die kontextbezogene Schlüsselüberschrift "OCK für besondere Bevölkerungsgruppen" in dem Absatz fehlt, kann das Modell keine vollständige und genaue Antwort geben.
Dies ist ein guter Hinweis darauf, dass die Qualität des Parsens von Dokumenten direkt die Qualität der RAG Die Obergrenze der Systemleistung.
Warum ist das Parsen von Dokumenten so kompliziert?
Das Parsen von Dokumenten ist kein einzelnes algorithmisches Werkzeug, sondern ein komplexes Paket von Lösungen. Die Komplexität ergibt sich aus einer Kombination von Herausforderungen in den folgenden verschiedenen Dimensionen:
- DateiformatPDF, Word, Excel, PPT, Markdown und andere Formate werden auf unterschiedliche Weise behandelt.
- BusinessEinzigartige Layoutstile für verschiedene Dokumente wie akademische Arbeiten, Geschäftsberichte und Jahresabschlüsse.
- Sprachtyp (in einer Klassifikation)Die Erkennung verschiedener Sprachen ist auf den entsprechenden Korpus für das Modelltraining angewiesen.
- DokumentationselementGenaue Reduktion von Elementen wie Absätzen, Überschriften, Tabellen, Formeln, Ecken usw. ist ein wichtiger Bestandteil der Hilfe bei der
LLMDer Schlüssel zum Verständnis der hierarchischen Struktur eines Aufsatzes. - SeitenlayoutLayout: Layouts wie einspaltig, zweispaltig und gemischt mehrspaltig haben einen direkten Einfluss auf die korrekte Wiederherstellung der Lesereihenfolge.
- Inhalt des Bildes: Text
OCRHandschrifterkennung und die Optimierung der Bildauflösung sind in Szenarien mit gemischtem Text besonders problematisch. - TabellenstrukturDie komplexe Struktur von verschmolzenen Zellen, Querseiten, Verschachtelungen usw. in Tabellen führt dazu, dass sie anders analysiert werden als Text und Bilder.
- zusätzliche FähigkeitIntelligentes Chunking ist zwar kein natürlicher Bestandteil des Parsens, aber qualitativ hochwertiges Chunking, insbesondere bei sehr großen Tabellen, kann die Ergebnisse von Q&A deutlich verbessern.
Kein einziges Tool kann in allen oben genannten Dimensionen brillieren. Daher führt die unüberlegte Wahl eines Open-Source-Tools oft dazu, dass man das eine oder andere aus den Augen verliert und es schwierig wird, die Anforderungen einer hochwertigen Anwendung zu erfüllen.
Wie kann man Werkzeuge zur Analyse von Dokumenten wissenschaftlich bewerten?
Da es kein perfektes Allzweckwerkzeug gibt, stellt sich die Frage, wie man die optimale Wahl für ein bestimmtes Szenario ermittelt. Ein Forschungsergebnis des Shanghai Artificial Intelligence Laboratory bietet hierfür eine Referenz. Die Forschungsarbeit, die auf der wichtigsten Konferenz für Computer Vision vorgestellt wurde CVPR 2024 Forschung erhalten hat, eine spezielle Bewertung der PDF Benchmarking der Fähigkeiten zum Parsen von Dokumenten -OmniDocBench。
OmniDocBench Von 200.000 PDF Die visuellen Merkmale werden aus den Dokumenten extrahiert, und 6000 Seiten mit signifikanten Unterschieden werden durch eine Clusteranalyse herausgefiltert, und 981 davon werden schließlich feinkörnig annotiert. Die Annotationsdimensionen sind sehr umfangreich und umfassen Layout Bounding Boxes, Layout-Attribute, Lesereihenfolge und hierarchische Beziehungen usw. Besonders freundlich ist es, die Relevanz seitenübergreifender Inhalte zu annotieren.
In Bezug auf die Bewertungsindikatoren.OmniDocBench Für verschiedene Dimensionen wie Text, Tabellen, Formeln und Lesereihenfolge werden Normalised Edit Distance (NED), Tree Edit Distance Based Similarity (TEDS) und BLEU und viele andere Algorithmen, um sicherzustellen, dass die Bewertung umfassend und fair ist.
Wer sind die Führer in jeder Dimension?
OmniDocBench Der Bewertungsbericht zeigt einen interessanten Trend auf.

(Quelle: https://arxiv.org/abs/2402.07626)
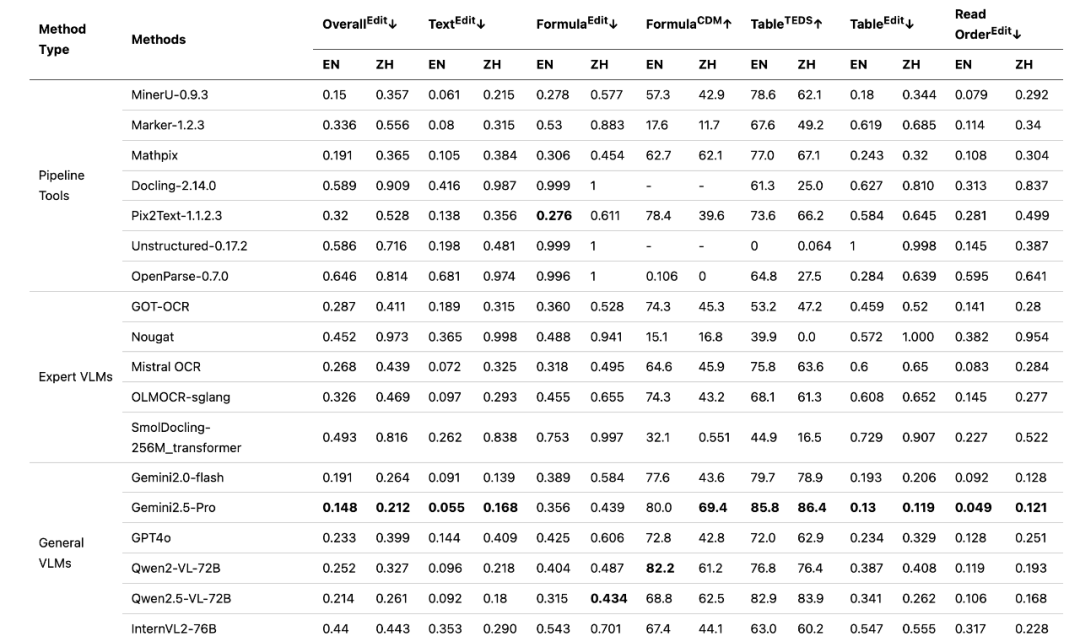
(Quelle: https://github.com/opendatalab/OmniDocBench/blob/main/README_zh-CN.md)
In den frühen Thesengraphen des Projekts konkurrierten verschiedene Arten von traditionellen Dokumenten-Parsing-Werkzeugen auf verschiedenen Dimensionen miteinander. Als jedoch generische visuelle Makromodelle (z.B. Gemini 1.5 Pro) in die Überprüfung einbezogen wurde, konnte es aufgrund seiner starken Gesamtfähigkeiten bei allen Indikatoren einen Spitzenplatz erreichen.
Dieser Vorteil ergibt sich aus Gemini Native multimodale Makromodelle wie diese sind in der Lage, Bild- und Textinformationen durchgängig zu verarbeiten, um das Gesamtlayout und die Semantik eines Dokuments besser zu verstehen. Diese leistungsstarke Fähigkeit ist jedoch mit einem hohen Preis verbunden.
以 Gemini 1.5 Pro So erkannte es beispielsweise zwar die gekritzelte Handschrift richtig, zeigte aber bei einer komplexen Tabelle mit mehreren zusammengefügten Zellen und Eckbeschriftungen immer noch erhebliche Fehler beim Parsing.
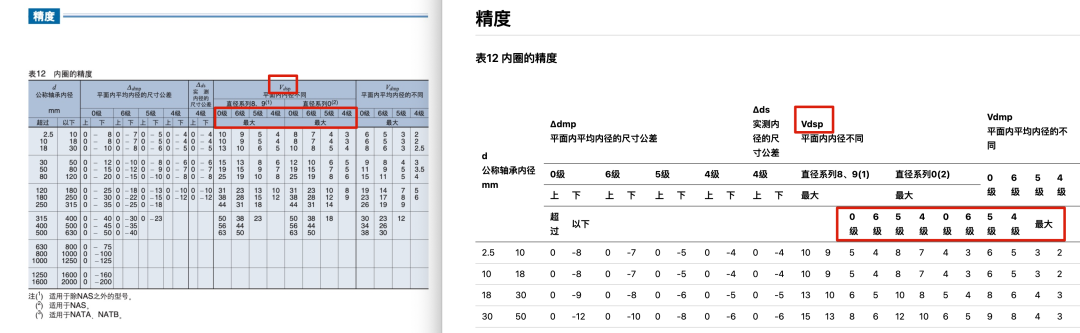
(Verwendung Gemini 1.5 Pro Beispiele für Fehler beim Parsen komplexer Tabellen)
Noch kritischer ist die Frage der Kosten. Einfach diese Seite analysieren PDFDie Kosten betrugen etwa 1,2 RMB. Die Hauptquelle der Kosten ist die Modellausgabe von Token Dies ist ein enormer Mehraufwand für Unternehmen, die Dokumente in großem Umfang verarbeiten müssen.
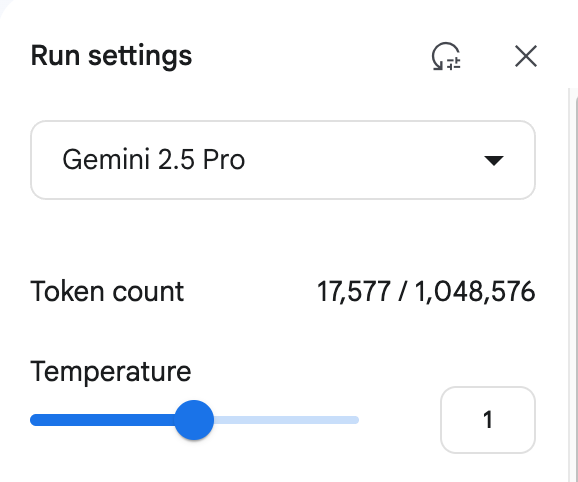
(Verwendung Gemini 1.5 Pro (Beispiel für den Kostenverbrauch beim Parsen von Dokumenten)
Deshalb.Gemini Es gibt kein allgemeingültiges Gegenmittel für alle Szenarien. In der Gemini Darüber hinaus hat die Industrie unstructured.io、Marker 和 PyMuPDF und viele andere hervorragende Open-Source- oder kommerzielle Lösungen, die für bestimmte Aufgaben und zur Kostenkontrolle vorteilhafter sein können. Die richtige Wahl beginnt mit einer klaren Definition des Anwendungsszenarios und der Notwendigkeit, ein Gleichgewicht zwischen Leistung, Kosten und spezifischen Anforderungen zu finden.
Praktische Ratschläge
Beim Aufbau oder der Optimierung von RAG Wenn das System, können Entwickler auf die folgenden Schritte, um das Problem der Dokument-Parsing zu überwinden beziehen:
- Bibliothek für diagnostische DokumentationPrüfen Sie Ihre Dokumente, um die schwierigsten Verträge, Berichte oder Scans zu identifizieren, und machen Sie sich klar, ob die größten Herausforderungen darin in komplexen Tabellen, mathematischen Formeln oder bestimmten Seitenlayouts liegen.
- Gezielte Validierung:: Vergleich
OmniDocBenchoder anderen Prüfberichten, wählen Sie ein oder zwei Tools aus, die sich in bestimmten Dimensionen durch eine gezielte Validierung auszeichnen, um die Lösung zu finden, die Ihren Unternehmensanforderungen am besten entspricht. - Die Grenzen im Auge behaltenDie Technologie zum Parsen von Dokumenten entwickelt sich rasant weiter, bleiben Sie dran!
OmniDocBenchDiese Art von Benchmark-Studien und neue Parsing-Tools können Ihnen helfen, die Systemleistung kontinuierlich zu optimieren.
Verwandte Forschung
OmniDocBenchDiplomarbeit: https://arxiv.org/abs/2402.07626






































