



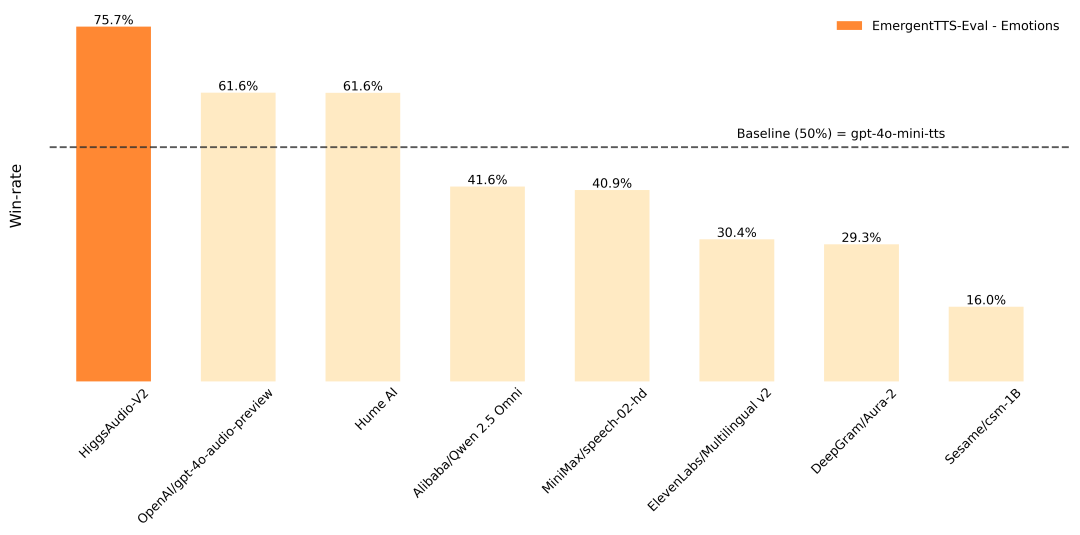
Higgs Audio ist ein von Boson AI entwickeltes Open-Source-Text-to-Speech (TTS)-Projekt, das sich auf die Erzeugung qualitativ hochwertiger, emotionsgeladener Sprache und Dialoge mit mehreren Zeichen konzentriert. Das Projekt basiert auf mehr als 10 Millionen Stunden Audiodatentraining und unterstützt das Klonen von Null-Sample-Sprache, die Erzeugung natürlicher Dialoge und die mehrsprachige Sprachausgabe.Higgs Audio v2 verwendet eine innovative Dual-FFN-Architektur und einen Unified Audio Phrase Splitter, um sowohl Text- als auch Audioinformationen effizient zu verarbeiten und realistische Spracheffekte zu erzeugen. Es schneidet im EmergentTTS-Eval Benchmark mit einer Gewinnrate für emotionale Ausdrücke von 75,7% gut ab, deutlich besser als andere Modelle. Das Projekt stellt detaillierten Code und Installationsanleitungen für Entwickler, Forscher und Kreative zur Verfügung und findet breite Anwendung bei der Erstellung von Audioinhalten, virtuellen Assistenten und im Bildungswesen.
Funktionsliste
- Generieren Sie qualitativ hochwertige Sprache: Wandeln Sie Text in natürliche, gefühlsbetonte Sprache um, die ein breites Spektrum an Intonation und emotionalem Ausdruck unterstützt.
- Multi-Role Dialogue Generation: Unterstützt Multi-Role Speech Generation und simuliert Pausen, Unterbrechungen und Überschneidungen in natürlichen Dialogen.
- Null-Sample-Stimmenklonen: Erzeugen Sie die Stimme der Zielperson schnell und ohne zusätzliches Training aus Referenzaufnahmen.
- Mehrsprachige Unterstützung: unterstützt die Spracherzeugung in Englisch, Chinesisch, Deutsch, Koreanisch und anderen Sprachen.
- Kombination von Musik und Sprache: kann gleichzeitig Hintergrundmusik und Sprache erzeugen, geeignet für Audio-Storytelling oder immersive Erfahrungen.
- Effiziente Inferenz: unterstützt die Ausführung auf Edge-Geräten wie dem Jetson Orin Nano mit geringem Ressourcenverbrauch.
- Offener Quellcode: Bereitstellung einer vollständigen Codebasis und API, Unterstützung der Entwickler bei der Anpassung der Entwicklung.
Hilfe verwenden
Einbauverfahren
Higgs Audio ist ein Open-Source-Projekt, das auf GitHub gehostet wird. Der Installationsprozess ist einfach, erfordert aber eine gewisse Unterstützung der Entwicklungsumgebung. Im Folgenden finden Sie die detaillierten Installationsschritte, die für verschiedene Umgebungen gelten:
1. das Klonen der Codebasis
Klonen Sie zunächst lokal das GitHub-Repository von Higgs Audio:
git clone https://github.com/boson-ai/higgs-audio.git
cd higgs-audio
2. die Konfigurationsumgebung
Higgs Audio bietet mehrere Möglichkeiten, die Umgebung zu konfigurieren, darunter virtuelle Umgebungen, Conda und uv. Python 3.10 und höher wird empfohlen. Hier sind die Schritte zur Konfiguration einer virtuellen Umgebung:
python3 -m venv higgs_audio_env
source higgs_audio_env/bin/activate
pip install -r requirements.txt
pip install -e .
Wenn Sie Conda verwenden:
conda create -n higgs_audio_env python=3.10
conda activate higgs_audio_env
pip install -r requirements.txt
pip install -e .
Für Szenarien mit hohem Durchsatz wird empfohlen, die vLLM Motor. Referenz examples/vllm führen Sie den folgenden Befehl aus, um den API-Server zu starten:
python -m vllm.entrypoints.openai.api_server --model bosonai/higgs-audio-v2-generation-3B-base --tensor-parallel-size 4 --gpu-memory-utilization 0.9
Hardware-VoraussetzungFür eine optimale Leistung wird ein Grafikprozessor mit mindestens 24 GB Videospeicher (wie der NVIDIA RTX 4090) empfohlen. Edge-Geräte wie der Jetson Orin Nano können auch kleinere Modelle ausführen.
3. die Überprüfung der Installation
Führen Sie nach Abschluss der Installation den folgenden Python-Code aus, um zu überprüfen, ob die Umgebung korrekt konfiguriert ist:
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine
engine = HiggsAudioServeEngine(
"bosonai/higgs-audio-v2-generation-3B-base",
"bosonai/higgs-audio-v2-tokenizer",
device="cuda"
)
output = engine.generate(content="Hello, welcome to Higgs Audio!", voice_profile="neutral")
Wenn eine Audiodatei ausgegeben wird, war die Installation erfolgreich.
Funktion Betriebsablauf
Zu den wichtigsten Funktionen von Higgs Audio gehören Text-to-Speech, die Erstellung von Dialogen mit mehreren Zeichen und das Klonen von Stimmen. Nachfolgend finden Sie die Schritte, um dies zu tun:
1. text-to-speech
Higgs Audio unterstützt die Umwandlung von Text in natürliche Sprache, und der emotionale Ausdruck kann durch die voice_profile Steuerung der Parameter. Zum Beispiel, um eine Stimme mit einem "dringenden" Ton zu erzeugen:
curl http://localhost:8000/v1/audio/generation -H "Content-Type: application/json" -d '{"text": "Security alert: Unauthorized access detected", "voice_profile": "urgent"}'
Benutzer können verschiedene Emotionsbezeichnungen angeben (z. B. happy、sad、neutral), passt das Modell den Ton und das Tempo automatisch an die Semantik des Textes an.
2. die Erstellung von Dialogen mit mehreren Akteuren
Higgs Audio ist gut darin, Dialoge mit mehreren Charakteren zu erzeugen, die natürliche Interaktionen in realen Szenarien simulieren. Der Benutzer muss einen Text eingeben, der z. B. Zeichen-Tags enthält:
dialogue = """
SPEAKER_0: Hey, have you tried Higgs Audio yet?
SPEAKER_1: Yeah, it’s amazing! The voices sound so real!
"""
output = engine.generate(content=dialogue, multi_speaker=True)
Das Modell generiert verschiedene Stimmen auf der Grundlage von Charakter-Tags und fügt automatisch Pausen und Veränderungen im Tonfall hinzu, was es für den Einsatz in Hörbüchern oder Spieldialogen geeignet macht.
3. das Klonen von Null-Sample-Sprache
Der Benutzer kann ein Referenzstück zur Verfügung stellen und das Modell klont dessen Sprachmerkmale. Beispiel:
output = engine.generate(
content="This is a test sentence.",
reference_audio="path/to/reference.wav",
voice_profile="cloned"
)
Der Referenzton sollte eine klare Einzelstimme mit einer empfohlenen Länge von 5-10 Sekunden sein. Die geklonte Stimme kann für die personalisierte Audioerstellung verwendet werden.
4. mehrsprachige Unterstützung
Higgs Audio unterstützt mehrsprachige Spracherzeugung. Die Benutzer müssen nur den Sprachinhalt im Text angeben, und das Modell passt sich automatisch an. Zum Beispiel:
output = engine.generate(content="你好,欢迎体验Higgs Audio!", voice_profile="neutral")
Derzeit werden Englisch, Chinesisch, Deutsch und Koreanisch unterstützt, aber es kann Einschränkungen bei der Handhabung chinesischer Zahlen und Symbole geben, die weiter optimiert werden müssen.
5. die Integration von Musik und Sprache
Higgs Audio generiert Sprache mit Hintergrundmusik für immersive Erlebnisse. Die Benutzer müssen dem Text Musik-Tags hinzufügen:
content = "[music_start] The stars shimmered above. [music_end] This is a magical night."
output = engine.generate(content=content, background_music=True)
Das Modell erzeugt Hintergrundmusik auf der Grundlage von Tags und mischt sie mit Sprache.
Vorsichtsmaßnahmen für die Verwendung
- Hardware-OptimierungGPU: Die Ausführung auf der GPU kann die Geschwindigkeit der Schlussfolgerungen erheblich verbessern. Edge-Geräte müssen kleinere Modelle verwenden, um den Ressourcenverbrauch zu reduzieren.
- EingabeformatTexteingabe: Die Texteingabe muss klar sein und darf keine komplexen Symbole oder Formatierungsfehler enthalten, um eine effektive Erstellung zu gewährleisten.
- Referenz AudioKlonen von Stimmen erfordert eine hohe Qualität des Referenztons, um Störungen durch Hintergrundgeräusche zu vermeiden.
- MehrsprachigkeitChinesische Ziffern und Prozentzeichen können zu einer schlechten Generierung führen, und es wird empfohlen, komplexe Symbole zu vermeiden.
Anwendungsszenario
- Produktion von Hörbüchern
Higgs Audio verwandelt Buchtexte in emotionsgeladene Hörbücher mit Unterstützung für Dialoge mit mehreren Charakteren und Soundtracks, die sich für Verlage oder einzelne Autoren eignen, die hochwertige Hörbücher produzieren. - Erstellung von Bildungsinhalten
Lehrer können Higgs Audio verwenden, um mehrsprachige Audioaufnahmen historischer Persönlichkeiten zu erstellen und so die Interaktivität des Unterrichts zu verbessern. - Spieleentwicklung
Entwickler können die Multi-Charakter-Dialogfunktion nutzen, um dynamische Charakterstimmen für Spiele zu erzeugen, die natürliche Unterbrechungen und emotionale Ausdrücke unterstützen, um das Spielerlebnis zu verbessern. - Entwicklung von virtuellen Assistenten
Unternehmen können auf der Grundlage von Higgs Audio virtuelle Assistenten mit personalisierter Stimme für den Kundendienst oder intelligente Geräte entwickeln. - Synchronisation (Filmemachen)
Das Klonen von Stimmen und die Mehrsprachenunterstützung von Higgs Audio sind ideal für die Erstellung von Voiceovers für Film- und Fernsehproduktionen, die sich schnell an verschiedene Charaktere und Sprachen anpassen lassen.
QA
- Welche Sprachen werden von Higgs Audio unterstützt?
Derzeit werden Englisch, Chinesisch, Deutsch, Koreanisch und andere Sprachen unterstützt, wobei geplant ist, die Unterstützung für weitere Sprachen in Zukunft zu erweitern. - Wie kann die Stabilität des Klonens von Stimmen optimiert werden?
Stellen Sie klare, 5-10 Sekunden lange Referenztöne von einer Person zur Verfügung und vermeiden Sie die direkte Verwendung von generierten Tönen als Referenz, um die emotionale Kontrolle zu behalten. - Benötigt es einen Grafikprozessor?
GPUs steigern die Leistung, aber kleinere Modelle können auf Edge-Geräten wie dem Jetson Orin Nano für leichte Anwendungen eingesetzt werden. - Was sind die Grenzen der chinesischen Spracherzeugung?
Chinesische Ziffern und Symbole können zu einer schlechten Generierung führen. Es wird empfohlen, den Eingabetext zu vereinfachen, was in zukünftigen Versionen optimiert werden wird. - Wie gehen Sie mit der Unterscheidung der Stimmen in Dialogen mit mehreren Charakteren um?
Durch Hinzufügen von Zeichen-Tags (z.B. SPEAKER_0) zum Text erzeugt das Modell automatisch unterschiedliche Sprache und simuliert den natürlichen Rhythmus des Dialogs.




























