

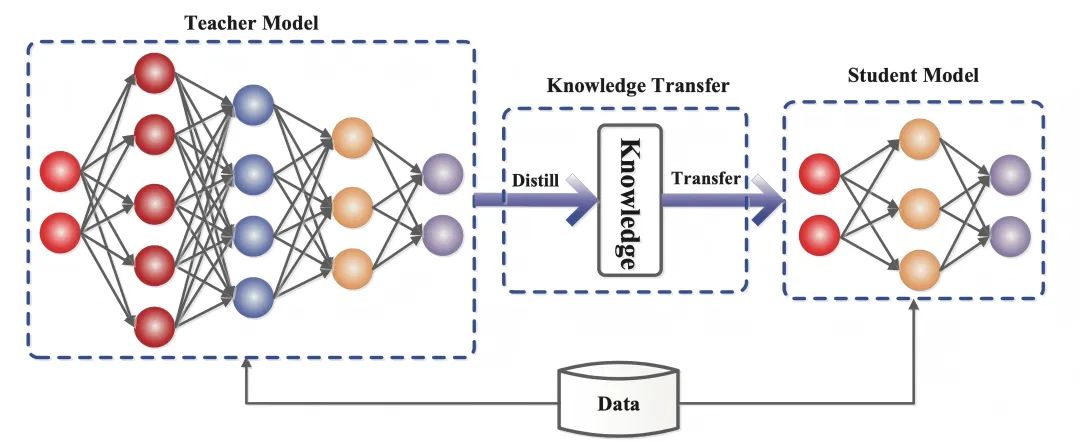
Wissensdestillation ist eine Technik des maschinellen Lernens, die darauf abzielt, den Lernprozess von einem großen, vorab trainierten Modell (d. h. einem "Lehrermodell") auf ein kleineres "Schülermodell" zu übertragen. Distillationstechniken können uns dabei helfen, leichtere generative Modelle zu entwickeln, die in Bereichen wie intelligenter Dialog und Inhaltserstellung eingesetzt werden können.
nächstgelegene (der Standorte) Distillation Dieses Wort wird sehr häufig verwendet.
Das DeepSeek-Team, das vor zwei Tagen für großes Aufsehen sorgte, veröffentlichte die DeepSeek-R1dessen umfangreiches Modell mit 670B Parametern durch Verstärkungslernen und Destillationstechniken erfolgreich auf ein leichtgewichtiges Modell mit 7B Parametern umgestellt wurde.
Das destillierte Modell übertrifft traditionelle Modelle derselben Größe und kommt sogar an das beste kleine Modell von OpenAI, OpenAI-o1-mini, heran.
Auf dem Gebiet der künstlichen Intelligenz werden große Sprachmodelle (z.B. GPT-4, DeepSeek-R1 ) hat hervorragende Argumentations- und Generierungsfähigkeiten bei Hunderten von Milliarden von Parametern gezeigt. Allerdings schränken der enorme Rechenaufwand und die hohen Bereitstellungskosten seine Anwendung in Szenarien wie mobilen Geräten und Edge Computing stark ein.
Wie lässt sich die Modellgröße ohne Leistungseinbußen komprimieren?Wissensdestillation(Knowledge Distillation) ist eine Schlüsseltechnik zur Lösung dieses Problems.
1. was ist Wissensdestillation
Die Wissensdestillation ist eine Technik des maschinellen Lernens, die darauf abzielt, das Lernen von einem großen, vorab trainierten Modell (d. h. einem "Lehrermodell") auf ein kleineres "Schülermodell" zu übertragen.
Beim Deep Learning wird sie als eine Form der Modellkomprimierung und des Wissenstransfers verwendet, insbesondere bei großen tiefen neuronalen Netzen.
Die Essenz der Wissensdestillation istMigration von Wissendie die Ausgabeverteilung des Lehrermodells nachahmt, so dass das Schülermodell dessen Verallgemeinerungsfähigkeit und Argumentationslogik erbt.
- Lehrermodell(Teacher Model): in der Regel ein komplexes Modell mit einer großen Anzahl von Parametern und ausreichendem Training (z. B. DeepSeek-R1), dessen Ausgabe nicht nur die Vorhersageergebnisse, sondern auch implizit die Ähnlichkeitsinformationen zwischen Kategorien enthält.
- Studentische Modelle(Schülermodell: Ein kleines, kompaktes Modell mit weniger Parametern, das einen Kompetenztransfer ermöglicht, indem es den Soft Targets des Lehrermodells entspricht.
Im Gegensatz zum traditionellen Deep Learning, bei dem das Ziel darin besteht, ein künstliches neuronales Netz so zu trainieren, dass es Vorhersagen trifft, die den Musterausgaben im Trainingsdatensatz näher kommen, muss das Schülermodell bei der Wissensdestillation nicht nur die richtige Antwort finden (ein schwieriges Ziel), sondern auch die "Logik des Denkens" des Lehrermodells erlernen. -d.h. die Ausgabe desWahrscheinlichkeitsverteilung(weiche Ziele).
In der Bildklassifizierungsaufgabe beispielsweise gibt das Lehrermodell nicht nur an, dass "dieses Bild eine Katze ist" (90%), sondern auch Möglichkeiten wie "es sieht aus wie ein Fuchs" (5%), "andere Tiere " (5%) und andere Möglichkeiten.
Diese Wahrscheinlichkeitswerte sind wie die "leichten Punkte", die der Lehrer bei der Benotung der Prüfungsarbeiten markiert. Durch die Erfassung der Zusammenhänge (z. B. Katzen und Füchse haben ähnliche spitze Ohren und ähnliche Haarmerkmale) wird das Schülermodell schließlich lernen, flexibler in seiner Unterscheidungsfähigkeit zu sein, anstatt mechanisch Standardantworten auswendig zu lernen.
2. die Kenntnis der Funktionsweise der Destillation
In der 2015 veröffentlichten Arbeit Distilling the Knowledge in a Neural Network, in der vorgeschlagen wird, das Training in zwei Phasen mit unterschiedlichen Zwecken aufzuteilen, ziehen die Autoren eine Analogie: Während die Larvenform vieler Insekten auf die Gewinnung von Energie und Nährstoffen aus der Umwelt optimiert ist, ist die erwachsene Form völlig anders, nämlich auf Fortbewegung und Fortpflanzung optimiert, während das traditionelle Deep Learning dieselben Modelle in der Trainings- und Einsatzphase verwendet, obwohl sie unterschiedliche Anforderungen haben.
Auch das Verständnis von "Wissen" in den Papieren ist unterschiedlich:
Vor der Veröffentlichung des Papiers bestand die Tendenz, das Wissen im Trainingsmodell mit den erlernten Parameterwerten gleichzusetzen, was es schwierig machte, zu erkennen, wie dasselbe Wissen durch eine Änderung der Form des Modells beibehalten werden könnte.
Eine abstraktere Sichtweise von Wissen ist, dass es eine erlernteAbbildung vom Eingangsvektor auf den Ausgangsvektor。
Techniken zur Wissensdestillation reproduzieren nicht nur die Ergebnisse der Lehrermodelle, sondern ahmen auch deren "Denkprozesse" nach. Im Zeitalter der LLMs ermöglicht die Wissensdestillation die Übertragung abstrakter Qualitäten wie Stil, Argumentationsfähigkeit und Übereinstimmung mit menschlichen Präferenzen und Werten.
Die Durchführung der Wissensdestillation kann in drei Kernschritte unterteilt werden:
2.1 Weiche Zielgenerierung: "Fuzzifierung" der Antworten
Das Lehrermodell wird weitergegebenHochtemperatur-SoftmaxDie Technologie verwandelt "schwarz-weiße" Antworten in "unscharfe Hinweise", die detaillierte Informationen enthalten.
Je höher die Temperatur (Temperature) ist (z. B. T=20), desto glatter ist die Wahrscheinlichkeitsverteilung der Modellausgabe.
Zum Beispiel das Original-Urteil "Cat (90%), Fox (5%)"
Kann zu "Katze (60%), Fuchs (20%), Sonstige (20%)" werden.
Diese Anpassung zwingt die Schülermodelle dazu, sich auf Korrelationen zwischen Kategorien zu konzentrieren (z. B. haben Katzen und Füchse ähnlich geformte Ohren), anstatt sich mechanisch Bezeichnungen einzuprägen.
2.2 Zielfunktionsentwurf: Ausgleich zwischen weichen und harten Zielen
Die Lernziele des Studentenmodells sind zweifach:
- Die Logik des Denkens des Lehrers nachahmen(weiches Ziel): Lernen von Beziehungen zwischen den Klassen durch Abgleich der Hochtemperatur-Wahrscheinlichkeitsverteilungen der Lehrer.
- Merken Sie sich die richtige Antwort.(Hartes Ziel): Sicherstellen, dass die Grundgenauigkeit nicht abnimmt.
Die Verlustfunktion des Schülermodells ist eine gewichtete Kombination aus weichen und harten Zielen, und die Gewichte beider müssen dynamisch angepasst werden.
Wenn zum Beispiel die Gewichtung von 70% für weiche Ziele und 30% für harte Ziele festgelegt wird, ist es so, als würden die Schüler 70% Zeit damit verbringen, die Lösungen des Lehrers zu studieren, und 30% Zeit damit, Standardantworten zu konsolidieren, um letztendlich ein Gleichgewicht zwischen Flexibilität und Genauigkeit zu erreichen.
2.3 Dynamische Regulierung der Temperaturparameter, Kontrolle der "Transfergranularität" des Wissens.
Der Parameter Temperatur ist der "Schwierigkeitsregler" der intellektuellen Destillation:
- Hochtemperatur-Modus(z. B. T=20): Die Antworten sind sehr mehrdeutig und eignen sich für die Vermittlung komplexer Zusammenhänge (z. B. die Unterscheidung zwischen verschiedenen Katzenrassen).
- Tieftemperaturbetrieb(z. B. T = 1): Die Antworten liegen nahe an der ursprünglichen Verteilung und sind für einfache Aufgaben (z. B. Zahlenerkennung) geeignet.
- dynamische StrategieUmfassende Wissensaufnahme mit zunächst hohen Temperaturen und späterer Abkühlung, um sich auf die wichtigsten Merkmale zu konzentrieren.
So erfordern beispielsweise Spracherkennungsaufgaben niedrigere Temperaturen, um die Genauigkeit zu erhalten. Dieser Prozess ist vergleichbar mit dem eines Lehrers, der die Tiefe des Unterrichts an das Niveau des Schülers anpasst - von der Heuristik bis hin zur Prüfungsvorbereitung.
3. die Bedeutung der Wissensdestillation
Die leistungsfähigsten Modelle für eine bestimmte Aufgabe sind in der Regel zu groß, zu langsam oder zu teuer für die meisten realen Anwendungsfälle, aber sie haben eine hervorragende Leistung, die sich aus ihrer Größe und ihrer Fähigkeit ergibt, mit großen Mengen von Trainingsdaten vorzutrainieren.
Dagegen sind kleinere Modelle zwar schneller und weniger rechenintensiv, aber weniger genau, weniger raffiniert und weniger kenntnisreich als größere Modelle mit mehr Parametern.
Hier kommt zum Beispiel der Wert der Anwendung der Wissensdestillation ins Spiel:
Das große Modell von DeepSeek-R1 mit 670 B-Parametern migriert seine Fähigkeiten in ein leichtgewichtiges Modell mit 7 B-Parametern durch eine Wissensdestillationstechnik: DeepSeek-R1-7B, das Nicht-Inferenzmodelle wie GPT-4o-0513 in allen Aspekten übertrifft.DeepSeek-R1-14B übertrifft das QwQ-32BPreview in allen Bewertungsmetriken, während das DeepSeek-R1-32B und DeepSeek-R1-70B übertreffen o1-mini in den meisten Benchmarks deutlich.
Diese Ergebnisse zeigen das große Potenzial der Destillation. Die Wissensdestillation hat sich zu einem wichtigen technischen Instrument entwickelt.
Im Bereich der Verarbeitung natürlicher Sprache verwenden viele Forschungsinstitute und Unternehmen Destillationstechniken, um große Sprachmodelle für Aufgaben wie Übersetzung, Dialogsysteme und Textklassifizierung in kleinere Versionen zu komprimieren.
So können beispielsweise große Modelle, wenn sie destilliert sind, auf mobilen Geräten ausgeführt werden, um Übersetzungsdienste in Echtzeit anzubieten, ohne auf leistungsstarke Cloud-Computing-Ressourcen angewiesen zu sein.
Der Wert der Wissensdestillation ist im IoT und beim Edge Computing sogar noch größer. Während große herkömmliche Modelle oft eine leistungsstarke GPU-Cluster-Unterstützung erfordern, werden kleine Modelle so destilliert, dass sie auf Mikroprozessoren oder eingebetteten Geräten mit viel geringerem Stromverbrauch ausgeführt werden können.
Diese Technologie senkt nicht nur die Einführungskosten drastisch, sondern ermöglicht auch eine breitere Anwendung intelligenter Systeme in Bereichen wie dem Gesundheitswesen, dem autonomen Fahren und intelligenten Häusern.
In Zukunft wird das Anwendungspotenzial der Wissensdestillation noch breiter sein. Mit der Entwicklung der generativen KI kann uns die Destillationstechnologie helfen, leichtere generative Modelle für intelligente Dialoge, die Erstellung von Inhalten und andere Bereiche zu entwickeln.






































