

Große Sprachmodelle (Large Language Models, LLMs) entwickeln sich rasch weiter, und ihre Schlussfolgerungsfähigkeit ist zu einem Schlüsselindikator für ihr Intelligenzniveau geworden. Insbesondere Modelle mit langen Schlussfolgerungsfähigkeiten, wie das von OpenAI o1、DeepSeek-R1、QwQ-32B 和 Kimi K1.5 Diese haben viel Aufmerksamkeit auf sich gezogen, weil sie in der Lage sind, komplexe Probleme zu lösen, indem sie tiefe menschliche Denkprozesse simulieren. Diese Fähigkeit beruht häufig auf einer Technik, die als "Inferenzzeit-Skalierung" bezeichnet wird und es dem Modell ermöglicht, bei der Generierung von Antworten mehr Zeit für die Erkundung und Korrektur zu verwenden.
Bei näherer Betrachtung zeigt sich jedoch, dass diese Modelle oft in zwei Extreme fallen, wenn es um die Argumentation geht:Underthinking 和 Zu viel nachgedacht。
nicht genug Stoff zum Nachdenken Dies bezieht sich auf das häufige Wechseln von Ideen in der Argumentation des Modells, was es schwierig macht, sich auf eine vielversprechende Richtung zu konzentrieren, um tiefer zu graben. Die Modellausgabe kann mit Wörtern wie "alternativ", "aber warte", "lass mich noch einmal überlegen" usw. gefüllt sein, die wie in der Abbildung unten dargestellt, zu falschen endgültigen Antworten führen. Dieses Phänomen kann mit der menschlichen Unaufmerksamkeit verglichen werden, die die Gültigkeit der Argumentation beeinträchtigt.

zu viel nachdenken Stattdessen erzeugt das Modell lange und unnötige "Gedankenketten" bei einfachen Problemen. Zum Beispiel für ein einfaches arithmetisches Problem wie "2+3=?" Für ein einfaches arithmetisches Problem wie "2+3=?" können einige Modelle Hunderte oder sogar Tausende von Arbeitsstunden erfordern. token um mehrere Lösungen iterativ zu überprüfen oder zu erforschen, wie unten gezeigt. Während komplexe Denkprozesse bei schwierigen Problemen von Vorteil sind, führt dies bei einfachen Szenarien sicherlich zu einer Verschwendung von Rechenressourcen.

Diese beiden Fragen zusammengenommen weisen auf eine zentrale Herausforderung hin: Wie kann die Effizienz des Denkens des Modells verbessert und gleichzeitig die Qualität der Antworten beibehalten werden? Ein ideales Modell sollte in der Lage sein, innerhalb kürzester Zeit die richtige Antwort zu finden und zu geben.
Um diese Herausforderung zu bewältigen.EvalScope Das Projekt führt ein EvalThink Komponente, mit dem Ziel, ein standardisiertes Instrument zur Bewertung der Denkleistung eines Modells bereitzustellen. In diesem Papier werden wir die MATH-500 Die Analyse des Datensatzes umfasst zum Beispiel DeepSeek-R1-Distill-Qwen-7B Die Leistung einer Reihe von Argumentationsmodellen, einschließlich solcher, die sich auf sechs Dimensionen konzentrieren: Modellieren von Schlussfolgerungen token Nummer, erstes Mal richtig token Anzahl, verbleibende Reflexionen token Zahlen,token Effizienz, Anzahl der Teil-Denkketten und Genauigkeit.
Bewertungsmethodik und -prozess
Der Bewertungsprozess besteht aus zwei Hauptphasen: der Bewertung des Modelldenkens und der Bewertung der Effizienz des Modelldenkens.
Bewertung der Modellüberlegungen
Das Ziel dieser Phase ist es, das Modell in MATH-500 Rohe Schlussfolgerungsergebnisse und Basisgenauigkeit für den Datensatz.MATH-500 Der Datensatz enthält 500 Mathematikaufgaben mit unterschiedlichem Schwierigkeitsgrad (von Stufe 1 bis Stufe 5).
Vorbereitung der Bewertungsumgebung
Die Auswertung kann durch den Zugriff auf einen OpenAI API-kompatiblen Reasoning Service erfolgen.EvalScope Das Framework unterstützt auch die Verwendung von transformers Die Bibliothek wird vor Ort überprüft. Für diejenigen, die mit langen Gedankenketten umgehen müssen (möglicherweise mehr als 10.000 token) des Inferenzmodells unter Verwendung von vLLM 或 ollama Effiziente Inferenzsysteme wie diese setzen Modelle ein, die den Bewertungsprozess erheblich beschleunigen können.
以 DeepSeek-R1-Distill-Qwen-7B Verwenden Sie zum Beispiel die vLLM Der Beispielbefehl für die Bereitstellung des Dienstes lautet wie folgt:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --trust_remote_code --port 8801
Überprüfung der Argumentation von Führungskräften
passieren (eine Rechnung oder Inspektion etc.) EvalScope 的 TaskConfig Konfigurieren Sie die Modell-API-Adresse, den Namen, den Datensatz, die Stapelgröße und die Generierungsparameter und führen Sie dann die Bewertungsaufgabe aus. Im Folgenden finden Sie ein Beispiel für Python-Code:
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需与部署时一致)
eval_type='service', # 评测类型:服务
datasets=['math_500'], # 数据集
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数,包含难度级别
eval_batch_size=32, # 并发请求数
generation_config={
'max_tokens': 20000, # 最大生成 token 数,设置较大值防截断
'temperature': 0.6, # 采样温度
'top_p': 0.95, # top-p 采样
'n': 1, # 每个请求生成一个回复
},
)
run_task(task_config)
Sobald die Bewertung abgeschlossen ist, wird das Modell in MATH-500 Genauigkeit in jedem Schwierigkeitsgrad (AveragePass@1):
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|-----------------------------|-----------|---------------|----------|-----|--------|---------|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
Modellhaftes Denken - Effizienzbewertung
Nach Erhalt der SchlussfolgerungEvalThink Komponenteneingriffe für tiefer gehende Effizienzanalysen. Zu den wichtigsten Bewertungsmetriken gehören:
- modellhafte Argumentation
token(Begründungsmünzen)Denkketten bei der Modellgenerierung von Antworten (wie im Modell O1/R1)</think>(was vor der Flagge steht), die in dertokenGesamtbetrag. - gleich beim ersten Mal richtig
tokenAnzahl (erste richtige Token)Vom Beginn der Modellausgabe bis zum ersten Auftreten einer identifizierbaren richtigen AntwortstelletokenMenge. - Verbleibende Überlegungen
tokenAnzahl (Reflexionsmarken):: Von der ersten richtigen Antwortposition bis zum Ende der GedankenkettetokenMenge. Dies spiegelt zum Teil die Kosten für die weitere Validierung oder Erkundung wider, nachdem das Modell eine Antwort gefunden hat. - Zifferngedanke:: Durch die Zählung bestimmter Signifikanten (z.B.
alternatively,but wait,let me reconsider), um abzuschätzen, wie oft das Modell die Ideen wechselt. tokenToken-Effizienz:: Messung des effektiven DenkenstokenIndikator für den Prozentsatz, berechnet als korrekte erste ZeittokenZahlen und allgemeines logisches DenkentokenDer Mittelwert des Verhältnisses der Anzahl der (es wurden nur Proben mit richtigen Antworten gezählt):
Token Efficiency = 1⁄N ∑ First Correct Tokensi⁄Reasoning Tokensi
wobei N die Anzahl der richtig beantworteten Fragen ist. Je höher der Wert, desto "effizienter" ist das Denken des Modells.
Zum Zwecke der Bestimmung des "Erstanwendungsrechts token Zahl", ein Bewertungsrahmen, der sich auf die ProcessBench Die Idee ist, ein separates Richtermodell zu verwenden, zum Beispiel Qwen2.5-72B-Instructum die Inferenzschritte zu untersuchen und die Stelle zu finden, an der die richtige Antwort am frühesten auftritt. Die Implementierung beinhaltet die Zerlegung der Modellausgabe in Schritte (Strategie optional: durch spezifisches Trennzeichen) separatorSchlüsselwörter der Presse keywordsoder mit Hilfe des LLM umgeschrieben und geschnitten werden llm), und lassen Sie dann das Schiedsrichter-Modell jeden einzelnen bewerten.
Beispielcode für die Durchführung einer think efficiency Bewertung:
from evalscope.third_party.thinkbench import run_task
# 配置裁判模型服务
judge_config = dict(
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1', # 假设裁判模型也部署在此服务
model_name='Qwen2.5-72B-Instruct',
)
# 配置待评估模型的信息
model_config = dict(
report_path='./outputs/2025xxxx', # 上一步推理结果路径
model_name='DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Tokenizer 路径,用于计算 token
dataset_name='math_500', # 数据集名称
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 数据集子集
split_strategies='separator', # 推理步骤分割策略
judge_config=judge_config
)
max_tokens = 20000 # 过滤 token 过长的输出
count = 200 # 每个子集抽样数量,加速评测
# 运行思考效率评估
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
In den Bewertungsergebnissen werden die sechs Dimensionen des Modells für jede Schwierigkeitsstufe detailliert aufgeführt.
Analyse und Diskussion der Ergebnisse
Das Forschungsteam verwendete EvalThink 对 DeepSeek-R1-Distill-Qwen-7B und verschiedene andere Modelle (QwQ-32B、QwQ-32B-Preview、DeepSeek-R1、DeepSeek-R1-Distill-Qwen-32B) bewertet und ein nicht-inferentielles mathematisches Spezialmodell hinzugefügt Qwen2.5-Math-7B-Instruct Zum Vergleich.
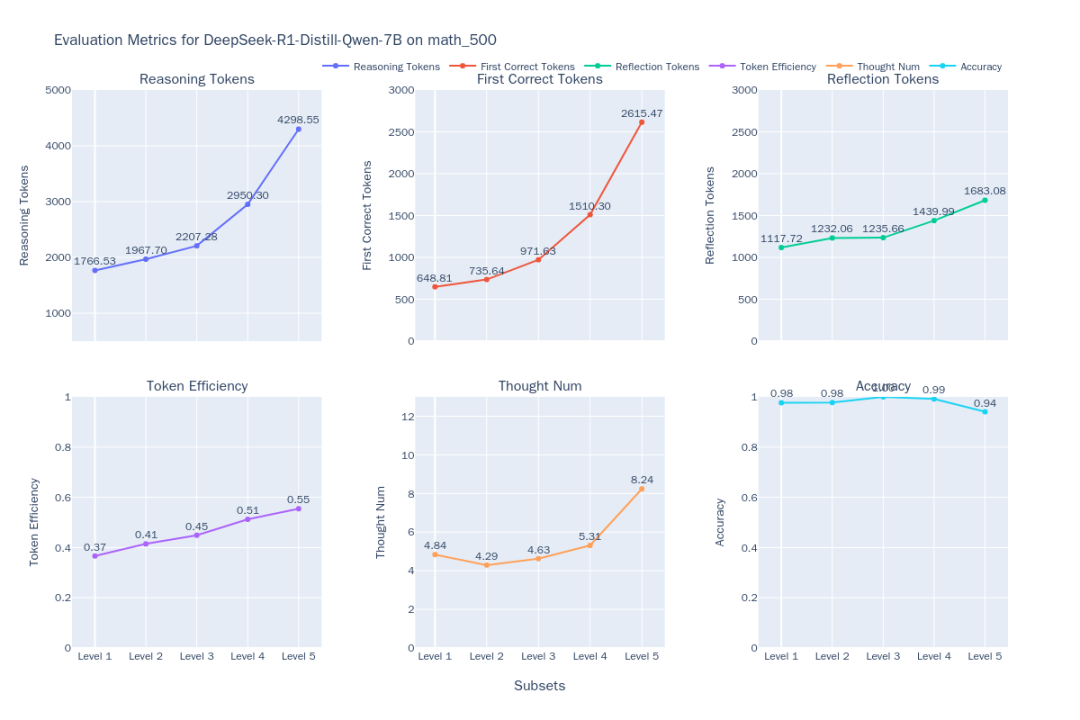
Abbildung 1: DeepSeek-R1-Distill-Qwen-7B-Indikator für die Denkeffizienz
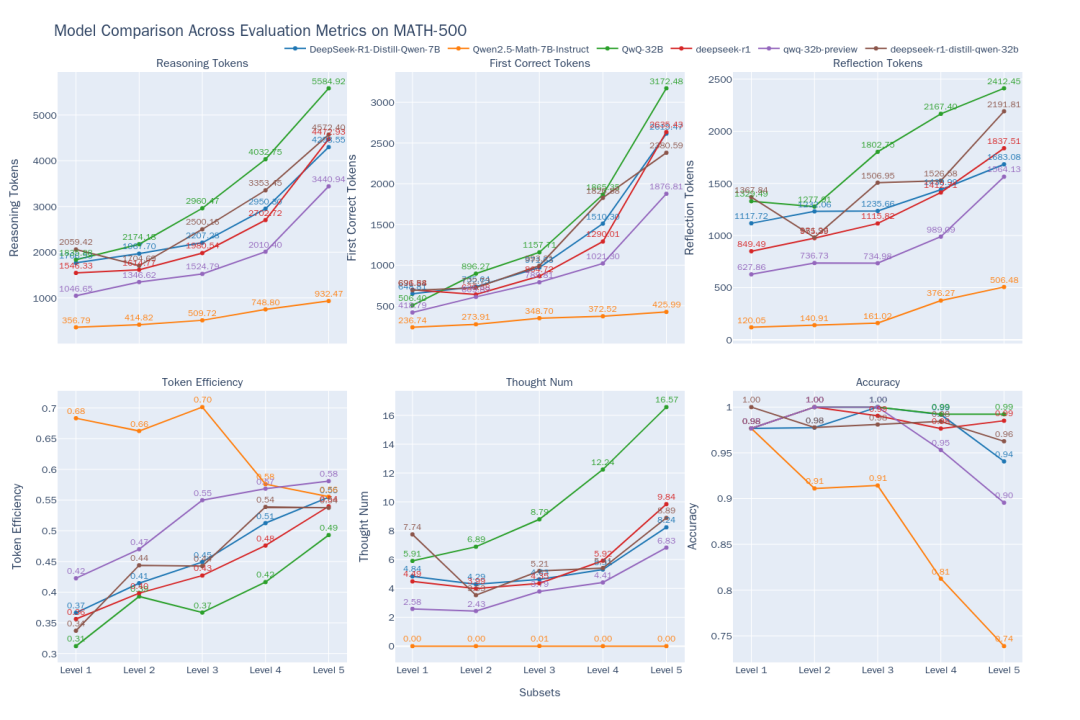
Abbildung 2: Vergleich der Denkeffizienz der 6 Modelle auf verschiedenen Schwierigkeitsstufen von MATH-500
Aus den Vergleichsergebnissen (Abbildung 2) lassen sich folgende Trends ablesen:
- Korrelation zwischen Schwierigkeit und LeistungMit zunehmendem Schwierigkeitsgrad der Aufgabe (Stufe 1 bis Stufe 5) nimmt die Genauigkeit der meisten Modelle ab. Allerdings.
QwQ-32B和DeepSeek-R1sich bei schwierigen Problemen auszeichnen.QwQ-32Bhöchste Genauigkeit auf Stufe 5. Gleichzeitig ist die Leistung aller ModelletokenDie Zahlen werden mit steigendem Schwierigkeitsgrad immer länger, was der Erwartung des "logischen Denkens beim Expandieren" entspricht - das Modell muss mehr "denken", um das Rätsel zu lösen. - O1/R1 Klasse Reasoning Model Eigenschaften:
- Effizienzgewinne:: Interessant ist, dass für
DeepSeek-R1和QwQ-32BBei dieser Art von Inferenzmodell wird die Ausgabe zwar länger, aber dietokenEffizienz (effektiv)tokenProzent) steigt ebenfalls mit der Schwierigkeit (DeepSeek-R1Von 36% bis 54%.QwQ-32B(von 31% auf 49%). Dies deutet darauf hin, dass ihr zusätzliches Denken bei schwierigen Problemen "kosteneffizienter" ist, während bei einfachen Problemen ein gewisses Maß an "Überdenken", z. B. unnötige Iterationen, vorkommen kann.QwQ-32B的tokenDer Verbrauch ist insgesamt hoch, was einer der Gründe dafür sein könnte, dass er auf Stufe 5 eine hohe Trefferquote beibehalten kann, aber auch auf eine Tendenz zum Überdenken hinweist. - Pfade des Denkens:
DeepSeekDie Anzahl der Sub-Denkketten für die Serienmodelle ist auf den Stufen 1-4 relativ stabil, steigt aber auf der schwierigsten Stufe 5 dramatisch an, was darauf hindeutet, dass Stufe 5 eine erhebliche Herausforderung für diese Modelle darstellt und mehrere Versuche erfordert. Im Gegensatz dazu.QwQ-32BDas Serienmodell weist ein gleichmäßigeres Wachstum der Anzahl der Gedankenketten auf, was unterschiedliche Bewältigungsstrategien widerspiegelt.
- Effizienzgewinne:: Interessant ist, dass für
- Grenzen von nicht-inferentiellen Modellen:: Mathematische Fachmodelle
Qwen2.5-Math-7B-InstructDie Genauigkeit sinkt dramatisch, wenn es um schwierige Probleme geht, und der OutputtokenDie Zahl ist viel geringer als bei den logischen Modellen (etwa ein Drittel). Dies deutet darauf hin, dass solche Modelle zwar bei gewöhnlichen Problemen schneller und weniger ressourcenintensiv sein können, dass sie aber aufgrund des Fehlens tieferer Denkprozesse bei komplexen logischen Aufgaben eine erhebliche Leistungsgrenze haben.
Methodische Überlegungen und Grenzen
in Anwendung EvalThink Bei der Durchführung einer Bewertung sind mehrere Punkte zu beachten:
- Definition von Indikatoren:
- in diesem Papier vorgeschlagen
tokenEffizienzindikatoren, die sich auf die Konzepte des "Überdenkens" und "Unterdenkens" in der Literatur stützen, konzentrieren sich in erster Linie auftokenDie Quantität, ein vereinfachtes Maß für den Denkprozess, kann die Qualität des Denkens nicht in allen Einzelheiten erfassen. - Die Berechnung der Anzahl der Sub-Denkketten beruht auf vordefinierten Schlüsselwörtern, und die Liste der Schlüsselwörter muss möglicherweise für verschiedene Modelle angepasst werden, um deren Denkmuster genau wiederzugeben.
- in diesem Papier vorgeschlagen
- Umfang der Anwendung:
- Die aktuellen Metriken wurden hauptsächlich anhand von Datensätzen zum mathematischen Denken validiert, und ihre Wirksamkeit in anderen Szenarien, wie z. B. offenes Quiz und Ideenfindung, muss noch getestet werden.
- Verpflegung
DeepSeek-R1-Distill-Qwen-7Bbasiert auf einem mathematischen Modell der Destillation desMATH-500Es kann ein natürlicher Leistungsvorteil für den Datensatz bestehen. Die Bewertungsergebnisse müssen im Zusammenhang mit dem Modell interpretiert werden.
- Abhängigkeit vom Adjudikationsmodell:
tokenDie Berechnung der Effizienz stützt sich auf das Richtermodell (Judge Model, JM), um die Korrektheit der Argumentationsschritte genau zu beurteilen. UnterProcessBench4Wie in der Studie festgestellt wird, ist dies eine schwierige Aufgabe für bestehende Modelle und erfordert in der Regel sehr leistungsfähige Modelle, um dieser Aufgabe gerecht zu werden.- Fehleinschätzungen im Schiedsrichtermodell können direkte Auswirkungen haben auf
tokenGenauigkeit der Effizienzindikatoren, daher ist die Wahl des richtigen Schiedsrichtermodells entscheidend.
Kurz und bündig.EvalThink Es wird eine Reihe von Rahmen und Metriken zur quantitativen Bewertung der Effizienz des LLM-Denkens bereitgestellt, die aufzeigen, wie gut verschiedene Modelle in Bezug auf die Genauigkeit abschneiden,token Abwägung zwischen Verbrauch und Tiefe des Denkens. Diese Erkenntnisse sind nützlich für die Modellschulung (z. B. GRPO und SFT) ist es aufschlussreich, Modelle der nächsten Generation zu entwickeln, die effizienter sind und die Tiefe des Denkens adaptiv an die Schwierigkeit des Problems anpassen können.





































