

科技行业最荒诞的剧本正在上演。一家靠阻挡自动化机器人起家、市值百亿的安全巨头,亲手打造了当今世界上最简单、甚至可能是最强大的自动化爬虫工具。
2026年3月,Cloudflare 正式上线了 Browser Rendering 的全新 Beta 功能:/crawl API。
没有复杂的框架配置,不用去处理令人头疼的验证码,也不用在服务器上苦苦维持那些动辄内存泄漏的 Puppeteer 或 Playwright 无头浏览器集群。你只需要发送一个 HTTP POST 请求,附带一个起始 URL,剩下的整站页面发现、JavaScript 渲染、分页抓取,全部由这家公司的全球边缘网络代劳。最后,它会老老实实地把干净的 HTML、Markdown 或结构化 JSON 吐给你。

讽刺的是,无数开发者过去几年一直在花钱买 Cloudflare 的服务来防御爬虫。现在,同一批人正在看文档,学习如何用 Cloudflare 的 API 去爬别人的网站。
被掩盖的野心:9 个端点构成的渲染帝国
当所有人的目光都盯在 /crawl 带来的震撼时,很多人忽略了它背后的基础设施。/crawl 并不是一个孤立的黑客玩具,它是 Cloudflare Browser Rendering 整个 REST API 矩阵的最后拼图。
仔细看目前的完整端点列表,你会发现他们其实已经把浏览器能做的事情彻底拆解了:
| 端点 | 功能描述 |
|---|---|
/content |
获取经过完整渲染的单页 HTML |
/screenshot |
网页视觉截图 |
/pdf |
页面转存 PDF |
/markdown |
专为 AI 准备的 Markdown 提取 |
/snapshot |
包含内容与视觉的混合快照 |
/scrape |
基于 DOM 节点的结构化抓取 |
/json |
结合 Workers AI 直接输出提取后的结构化数据 |
/links |
拓扑爬取必备的整页链接提取 |
/crawl |
自动化整站爬取(全新加入) |
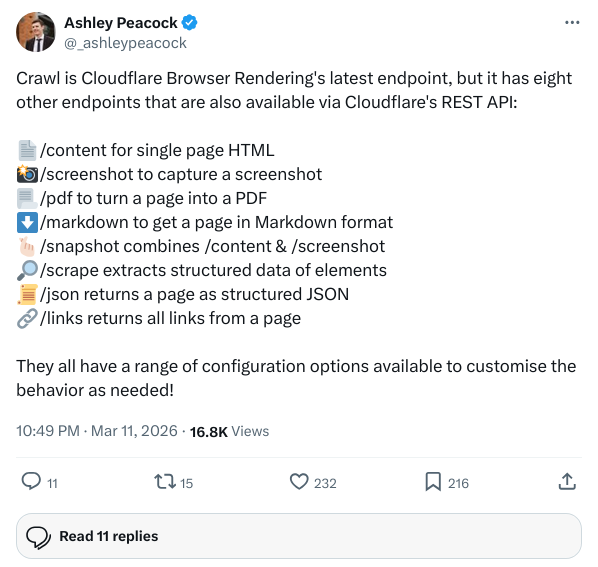
过去,你要么使用老旧的 Scrapy 去硬啃静态页面,要么搭一套沉重的 Node.js 服务去跑真实浏览器。现在 Cloudflare 将这个过程变成了两个极简步骤:
- 发起任务:提交起始 URL 给
/crawl,立刻拿到一个异步执行的 Job ID。 - 轮询获取:拿着 Job ID 查进度。任务最长能在他们的数据中心跑 7 天,结果保留 14 天。
系统内建的参数赋予了极高的控制力。你可以通过 limit 设定最高 10万页 的抓取上限,用 depth 限制链接深度,或者利用 includePatterns 等通配符只抓取特定路径下的内容。更致命的是 render 参数。如果你只需要抓取纯静态的文档站,把 render 设为 false,它就会跳过浏览器渲染直接高速并发抓取;如果是单页应用(SPA),开启 render 即可执行完 JavaScript 再提取内容。
零门槛的降维打击
这种基础设施级别的降维打击,立刻对现有的商业生态产生了引力。
RAG(检索增强生成)应用的开发者是第一波受益者。大模型需要干净的文本,HTML 标签对它们来说是噪音。以往开发者要写各种正则提取器和清洗脚本,现在一个请求就能直接拿回 Markdown。AI 数据工程师、独立开发者甚至小型创业团队,再也不需要雇佣专门的人去维护爬虫管道。
但对那些专门做爬虫 SaaS 的公司而言,这无异于釜底抽薪。以这两年风头正劲的 Firecrawl 为例,其核心商业模式就是把爬虫封装成好用的 API。现在我们把它和 Cloudflare 放上牌桌:
| 维度 | Cloudflare /crawl | Firecrawl |
|---|---|---|
| 底层定位 | 基础设施级原语 API | 专注垂直场景的 SaaS |
| 计费模式 | 按浏览器运算时长计费 | 按抓取页面数量计费 |
| 节点网络 | 庞大的全球边缘节点池 | 相对受限的服务器出口 |
| 易用性 | 需绑定 Cloudflare 账号与 Workers | 注册即用的傻瓜式服务 |
| 结构化提取 | 原生集成 Workers AI /json 端点 |
内置的大模型提取,开箱体验更好 |
Firecrawl 在产品包装和对无技术背景用户的友好度上依然领先。但 Cloudflare 拥有不可逾越的护城河:计算成本和节点规模。
Beta 测试期间,只要你不开启 JavaScript 渲染(render: false),这个接口完全免费。即使开启渲染,免费版每天也有 10 分钟 的浏览器运行时长;付费版(每月仅需 5 美元起步)则提供每月 10 小时 的额度,超出部分每小时只收 0.09 美元。按时长计费彻底颠覆了按请求计费的传统逻辑,对于重度抓取需求来说,成本几乎可以忽略不计。
既当盾牌,又造长矛
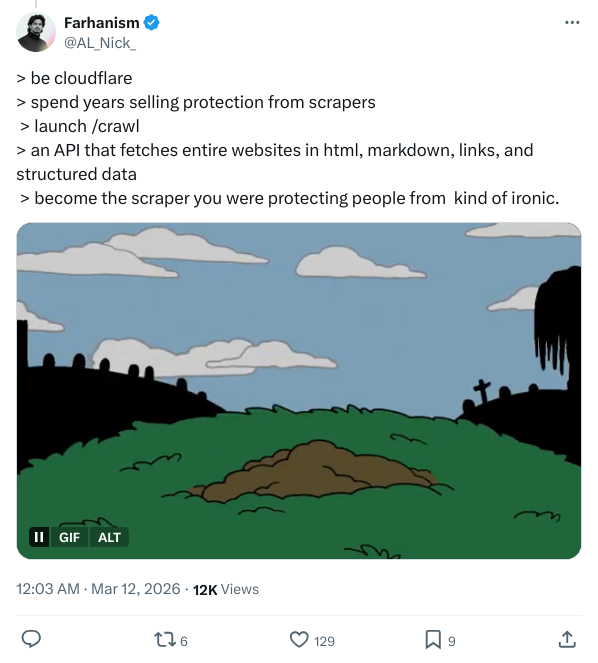
回到最初的讽刺。社交网络上的狂欢并非没有理由。X 用户 @AL_Nick_ 的一条推文精准击中了这家公司的行事逻辑:
be cloudflare
spend years selling protection from scrapers
launch /crawl
become the scraper you were protecting people from
配图是蝙蝠侠里的那句经典台词:“要么作为英雄体面退场,要么苟活到看着自己变成反派。”
面对全网的调侃,Cloudflare 官方在评论区给出了一个非常讨巧的辩护:他们认为如今互联网上充斥着暴力爬虫,根源在于“做一个礼貌爬虫的开发成本太高了”。所以他们提供一个默认遵守 robots.txt、控制并发频率不压垮目标服务器、且使用规范 User-Agent 的官方 API。
这套说辞逻辑自洽,但掩盖不了其商业上的精明。现实问题摆在桌面:那些付费购买了 Cloudflare 高级 WAF 的企业,他们的防线能挡住 Cloudflare 自己发出的 /crawl 请求吗?
中文社区的一位开发者 @chuhaiqu 说得一针见血:“以前:收钱帮你挡爬虫。现在:收钱帮你爬别人。”
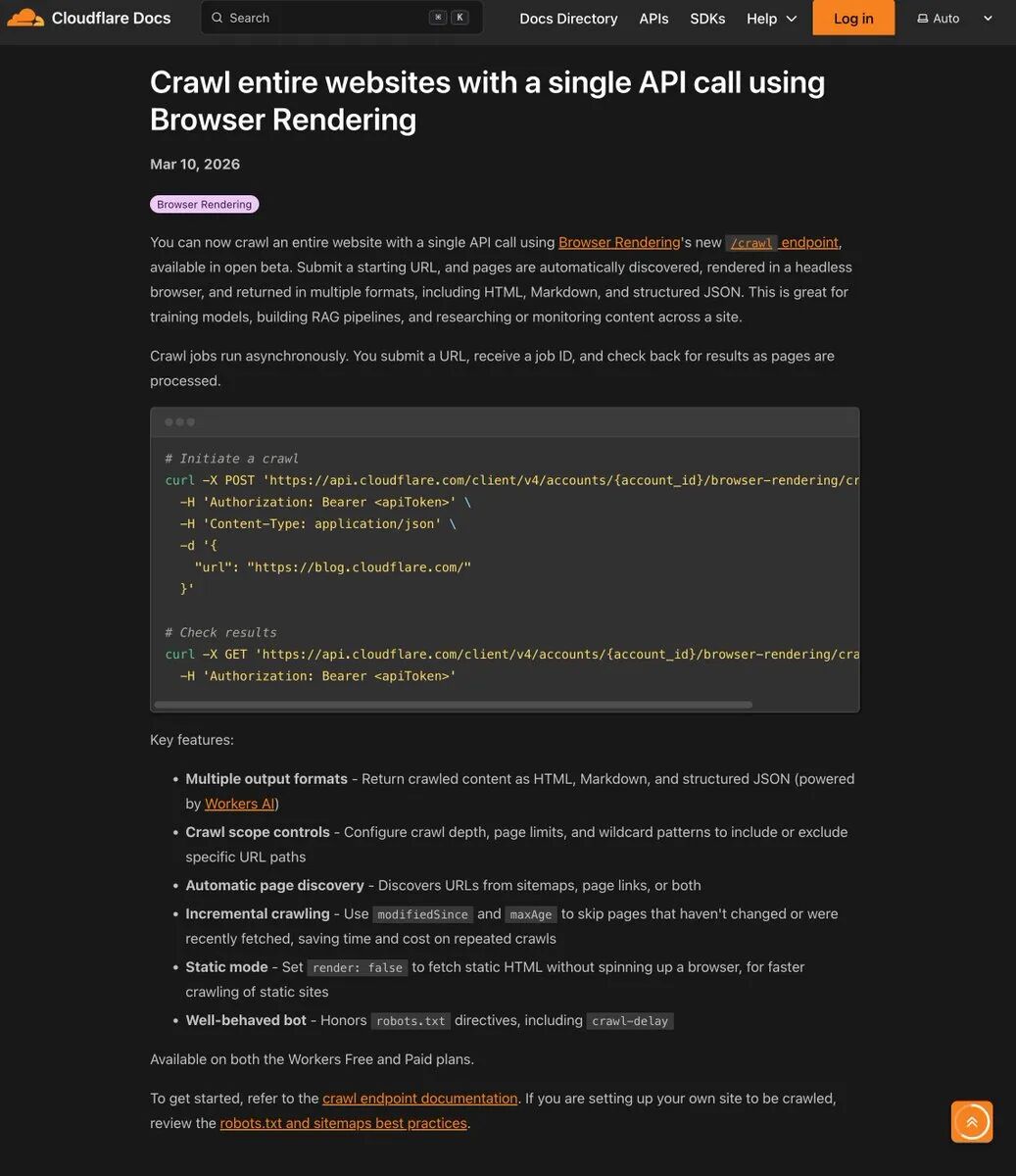
这其实是平台型企业的终极特权。通过将爬虫能力商品化,Cloudflare 进一步加深了开发者对其 Workers 计算生态的依赖。他们并不在乎你是去爬别人,还是防别人爬你。只要数据在流转,流量在经过他们的边缘节点,计费表就在走字。
实操:五分钟部署你的数据泵
抛开商业伦理,站在开发者的角度,这个工具确实太好用了。你需要准备的仅仅是一个开通了 Workers 服务的 Cloudflare 账号,以及一个具备 Browser Rendering 权限的 API Token。
一段不到 30 行的代码,就能拉起一个整站级的数据爬取任务:
async function crawlSite(url, apiToken, accountId) {
// 1. 发起 POST 请求,创建爬取任务
const startRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl`,
{
method: 'POST',
headers: {
'Authorization': `Bearer ${apiToken}`,
'Content-Type': 'application/json'
},
// 请求输出 Markdown,对于静态内容关闭渲染以加速
body: JSON.stringify({ url, formats:['markdown'], render: false })
}
);
const { result: jobId } = await startRes.json();
// 2. 轮询 GET 请求,等待庞大的任务集群完成作业
while (true) {
const checkRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}?limit=1`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
const data = await checkRes.json();
if (data.result.status !== 'running') break;
// 礼貌的等待时间
await new Promise(r => setTimeout(r, 3000));
}
// 3. 任务结束,提取洗净后的数据
const finalRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
return (await finalRes.json()).result.records;
}
他们甚至顺水推舟地发布了配套的 MCP Server,这意味着你可以在 Cursor 或者 Claude 这样的 AI IDE 里面直接通过自然语言调用这套系统。你需要什么数据,AI 就会自动去调用这套极简 API 抓回来。
旧的壁垒正在崩塌,数据获取的边际成本正在无限趋近于零。这对于互联网上开放内容的防御者来说,绝对是个坏消息。





































