即使在 AI 领域之外,许多基础设施系统也试图将“执行状态”与“业务状态”分开。对于 AI 应用,这可能涉及复杂的抽象来跟踪当前步骤、下一步、等待状态、重试次数等信息。这种分离会带来复杂性,虽然可能物有所值,但对你的用例来说可能有些小题大做了。
与往常一样,你需要自己决定什么才适合你的应用程序。但不要认为你必须将它们分开管理。
更清晰地说:
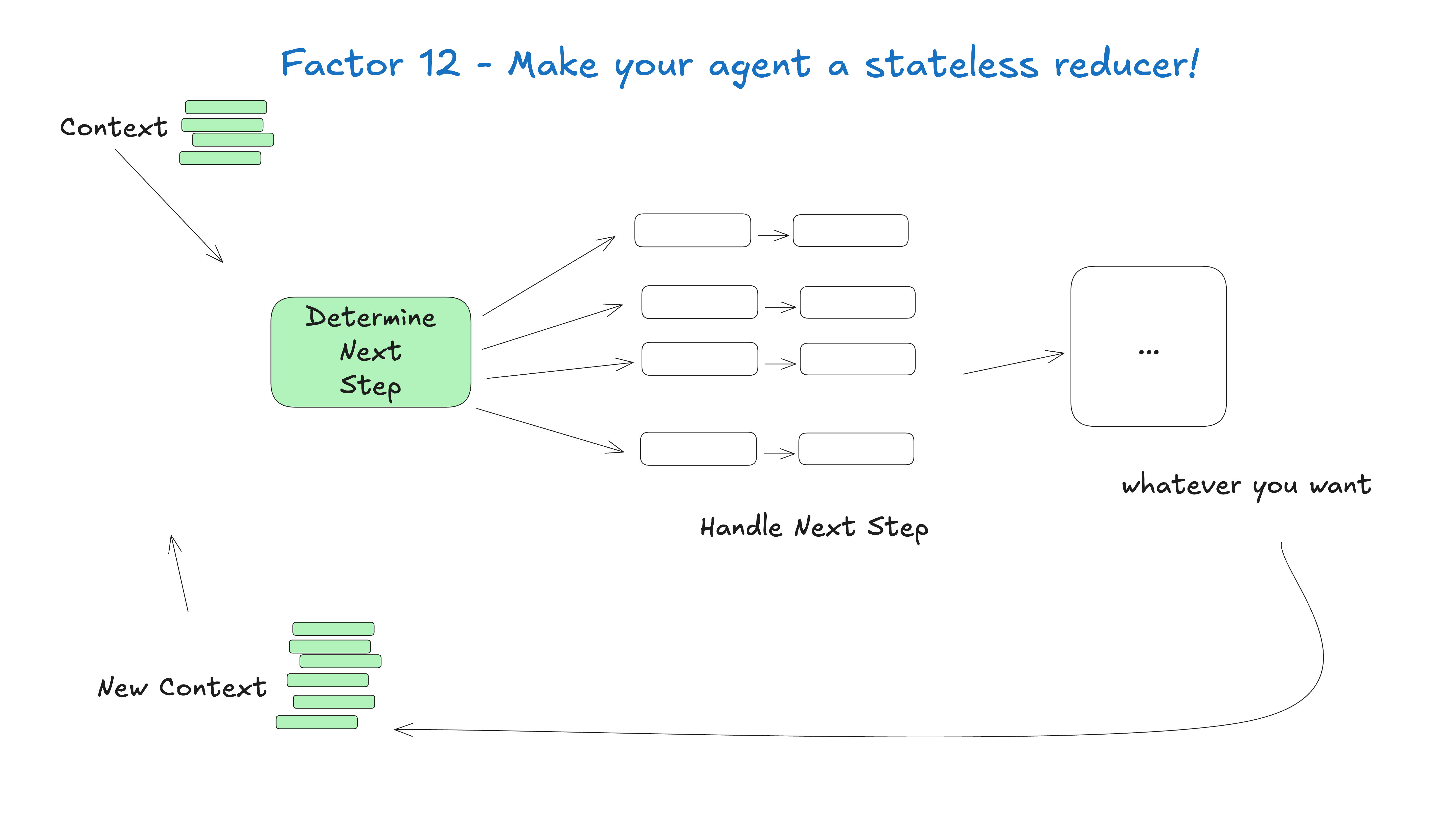
- 执行状态:当前步骤、下一步、等待状态、重试次数等。
- 业务状态:到目前为止在智能体工作流中发生的事情 (例如 OpenAI 消息列表、工具调用及结果列表等) 。
如果可能,请简化——尽可能地统一这两者。
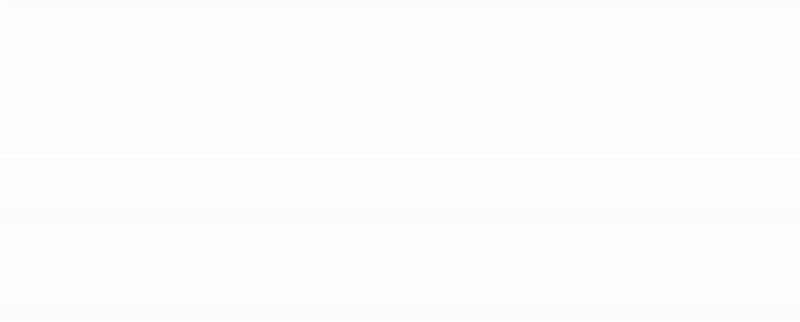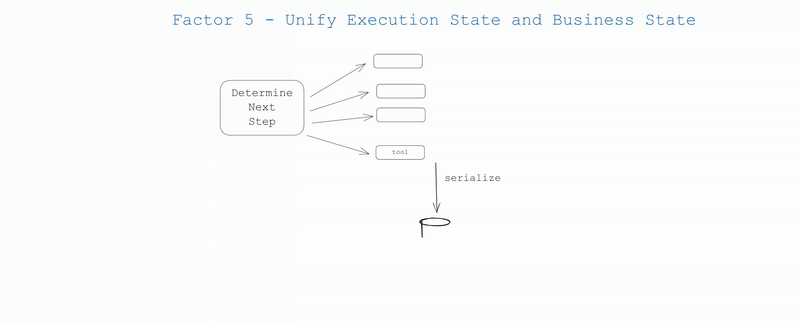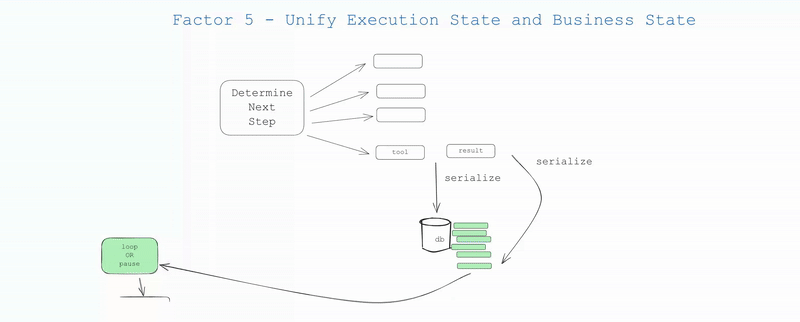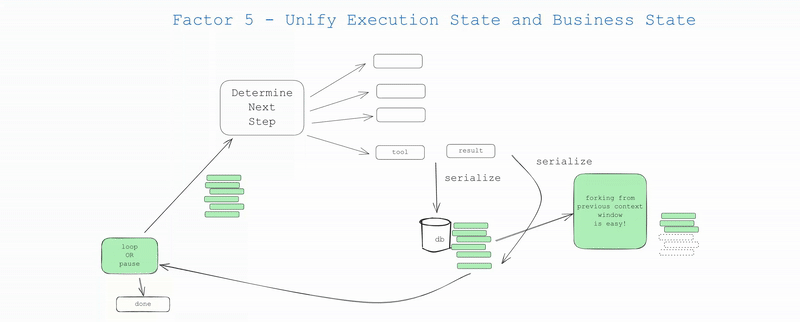
实际上,你可以设计你的应用程序,使其能够从上下文窗口中推断出所有的执行状态。在许多情况下,执行状态 (当前步骤、等待状态等) 只是关于目前为止已发生事件的元数据。
你可能有些东西无法放入上下文窗口,比如会话 ID、密码上下文等,但你的目标应该是尽量减少这些东西。通过采纳 第 3 要素,你可以控制实际输入到大语言模型的内容。
这种方法有几个好处:
- 简洁性:所有状态的唯一真实来源
- 序列化:线程可以轻松地进行序列化/反序列化
- 调试:整个历史记录一目了然
- 灵活性:只需添加新的事件类型即可轻松添加新状态
- 恢复:只需加载线程即可从任何点恢复
- 分叉:可以通过将线程的某个子集复制到新的上下文/状态 ID 中,在任意点对线程进行分叉
- 人机交互界面与可观测性:可以轻松地将线程转换为人类可读的 Markdown 或丰富的 Web 应用用户界面
未经允许不得转载:AI生产力工具 » 《12-Factor Agents》5. 统一执行状态与业务状态