与其构建试图包揽一切的单体式智能体,不如构建能把一件事做好的、小而专注的智能体。智能体只是一个更大、基本上是确定性的系统中的一个构建模块。

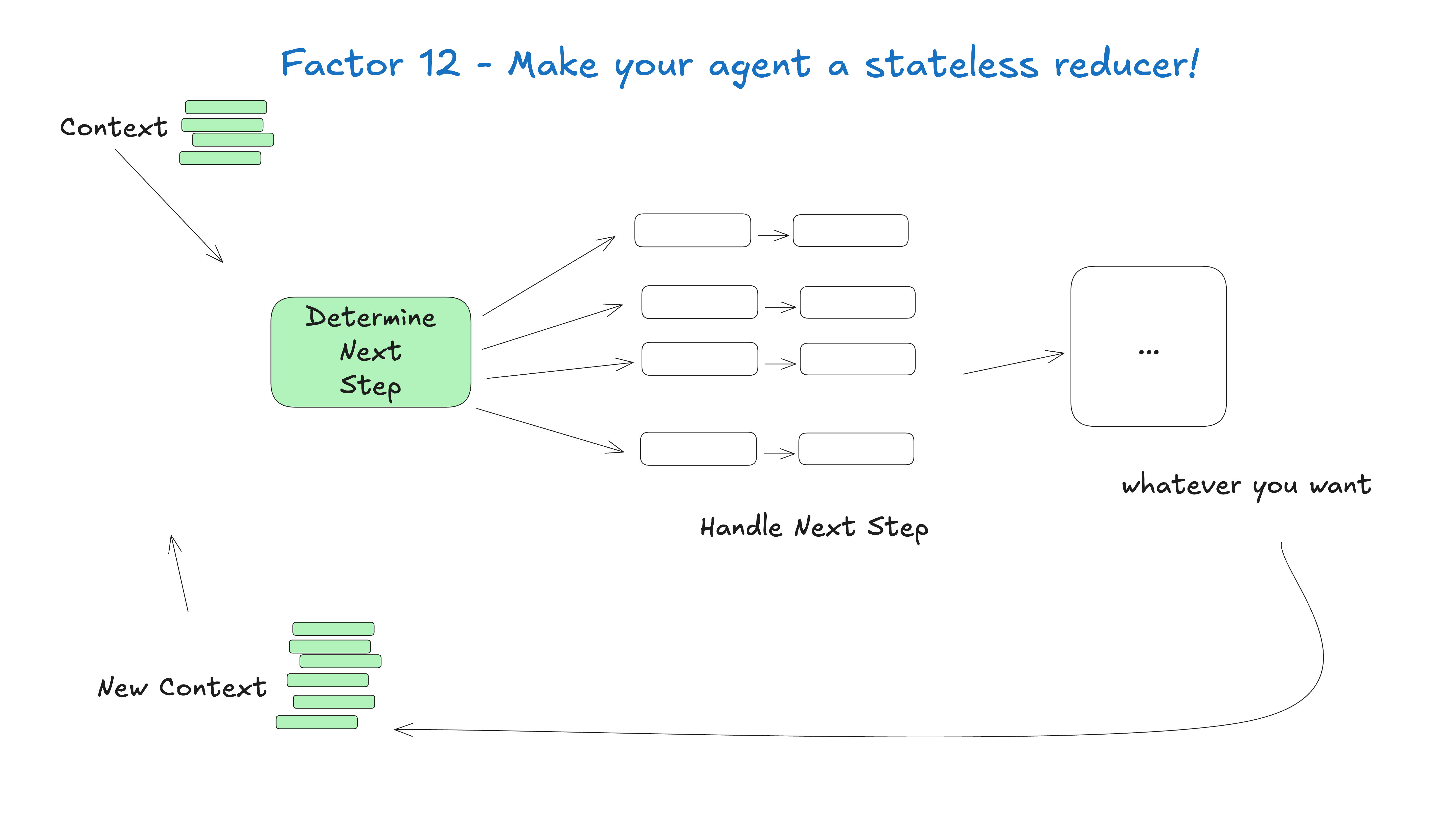
这里的关键洞见在于大语言模型的局限性:任务越庞大、越复杂,需要的步骤就越多,这意味着更长的上下文窗口。随着上下文的增长,大语言模型更有可能迷失或失去焦点。通过让智能体专注于特定领域,最多执行 3-10 个,或许 20 个步骤,我们能保持上下文窗口的可控性,并维持大语言模型的高性能。
随着上下文的增长,大语言模型更有可能迷失或失去焦点
小而专注的智能体的优势:
- 可控的上下文:更小的上下文窗口意味着更好的大语言模型性能
- 明确的职责:每个智能体都有明确定义的范围和目的
- 更高的可靠性:在复杂工作流中迷失的可能性更小
- 更易于测试:测试和验证特定功能更简单
- 改进的调试:出现问题时更容易识别和修复
如果大语言模型变得更智能会怎样?
如果大语言模型变得足够智能,能够处理 100 步以上的工作流,我们还需要这样做吗?
长话短说:是的。随着智能体和大语言模型的进步,它们 或许 会自然地扩展,以处理更长的上下文窗口。这意味着要处理一个更大的 DAG 中更多的部分。这种小而专注的方法确保你今天就能获得结果,同时也为你准备好,在 大语言模型 上下文窗口变得更可靠时,可以逐步扩展智能体的范围。 (如果你以前重构过大型确定性代码库,你现在可能正在点头) 。

这里的关键在于,要有意识地控制智能体的规模/范围,并仅以能够保持质量的方式进行扩展。正如 构建 NotebookLM 的团队所说:
我觉得,在构建 AI 的过程中,那些最神奇的时刻,总是在我非常、非常、非常接近模型能力边缘的时候出现的
无论那个边界在哪里,如果你能找到它并持续不断地正确把握,你就能构建出神奇的体验。这里可以建立许多护城河,但像往常一样,这需要一定的工程严谨性。
未经允许不得转载:AI生产力工具 » 《12-Factor Agents》10. 小而专注的智能体