这一点内容不多,但值得一提。智能体 (agent) 的好处之一是“自我修复”——对于简短的任务,大语言模型 (LLM) 可能会调用一个失败的工具。优秀的大语言模型有很大机率能够读取错误信息或堆栈跟踪 (stack trace) ,并找出在后续工具调用中需要更改的地方。
大多数框架都实现了这一点,但你也可以只实现这一点,而无需实现其他 11 个要素。下面是一个示例:
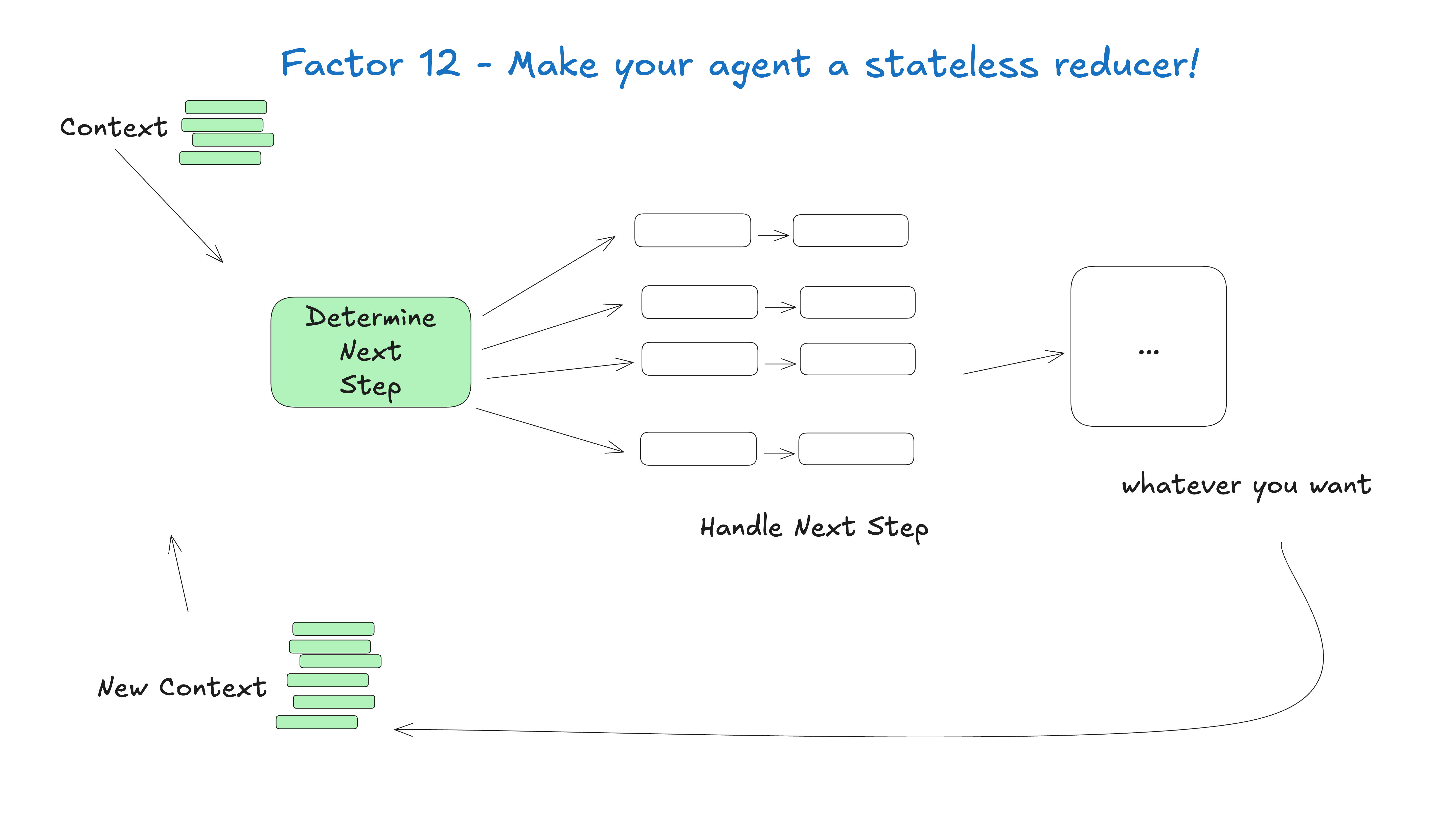
thread = {"events": [initial_message]}
while True:
next_step = await determine_next_step(thread_to_prompt(thread))
thread["events"].append({
"type": next_step.intent,
"data": next_step,
})
try:
result = await handle_next_step(thread, next_step) # 我们的 switch 语句
except Exception as e:
# 如果我们得到一个错误,我们可以将它添加到上下文窗口中再试一次
thread["events"].append({
"type": 'error',
"data": format_error(e),
})
# 在这里循环,或者做任何其他事情来尝试恢复
你可能想为特定的工具调用实现一个错误计数器 (errorCounter) ,将单个工具的尝试次数限制在 3 次左右,或者采用任何其他符合你用例的逻辑。
consecutive_errors = 0
while True:
# ... 现有代码 ...
try:
result = await handle_next_step(thread, next_step)
thread["events"].append({
"type": next_step.intent + '_result',
data: result,
})
# 成功!重置错误计数器
consecutive_errors = 0
except Exception as e:
consecutive_errors += 1
if consecutive_errors < 3:
# 进行循环并重试
thread["events"].append({
"type": 'error',
"data": format_error(e),
})
else:
# 中断循环,重置部分上下文窗口,上报给人类,或做任何你想做的事
break
}
}
当达到某个连续错误阈值时,可能是一个很好的时机来 上报给人类 ,无论是通过模型决策,还是通过确定性地接管控制流。

优点:
- 自我修复:大语言模型可以读取错误信息,并找出在后续工具调用中需要更改的地方
- 持久性:即使某个工具调用失败,智能体也可以继续运行
我相信你会发现,如果过度使用此方法,你的智能体可能会失控,并可能一遍又一遍地重复同样的错误。
这时候,要素 8 – 掌控你的控制流 和 要素 3 – 掌控你的上下文构建 就派上用场了——你不需要只是将原始错误信息放回去,你可以完全重构它的表示方式,从上下文窗口中移除先前的事件,或者采取任何你认为有效的确定性方法来让智能体回到正轨。
但防止错误失控的首要方法是采纳 要素 10 – 小型、专注的智能体 。
未经允许不得转载:AI生产力工具 » 《12-Factor Agents》9. 将错误信息压缩到上下文窗口中