



ShareGPT-4o-ImageはFreedomIntelligenceチームによってGitHubでオープンソース化された大規模なマルチモーダル画像生成データセットで、GPT-4oの画像生成機能に基づいて構築された91Kの高品質サンプルを含んでいます。このデータセットは、45Kのテキストから画像へのサンプルと、46Kのテキスト+画像から画像へのサンプルに分かれており、オープンソースのマルチモーダルモデルとGPT-4oの画像生成機能の整合を助けるように設計されています。このプロジェクトは、オープンソースのデータとモデルを通じてマルチモーダルAIコミュニティを発展させ、研究開発のための高品質なリソースを提供することを目的としています。
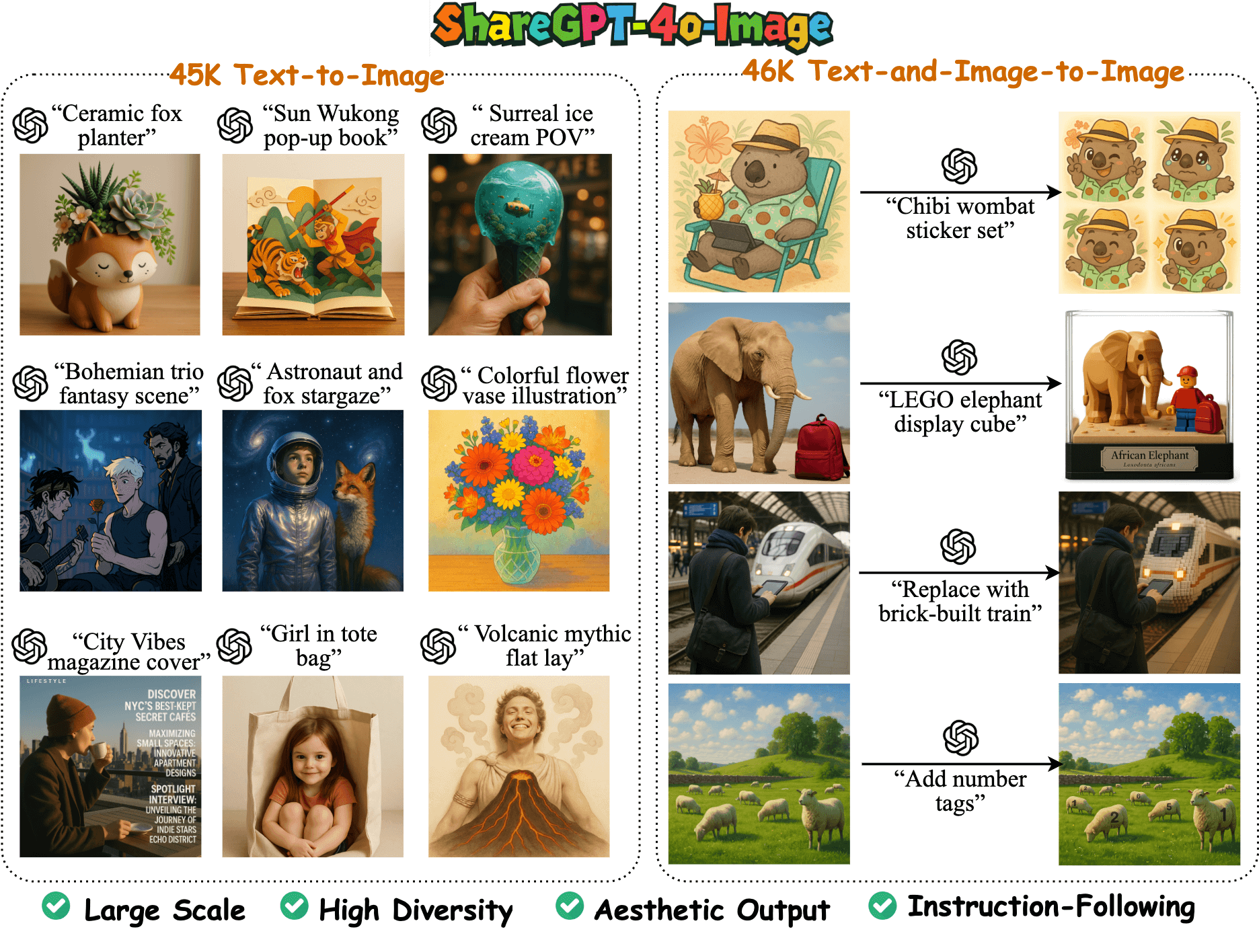
機能一覧
- 4万5,000のテキストから画像、4万6,000のテキストと画像から画像のサンプルを含む、9万1,000の高品質画像生成サンプルを提供。
- オープンソースのマルチモーダルモデルのトレーニングと最適化をサポートし、画像の生成と編集を強化します。
- テキストから画像への生成とテキスト+画像から画像への編集をサポートするJanus-4oモデルを含む。
- データセットのサイズは約20.7MBで、92,256行のデータが含まれている。
- 詳細なドキュメントとコード例が提供され、開発者がデータセットとモデルを素早く使いこなせるようにサポートする。
- オープンソースのコードとモデルはGitHubとHugging Faceにホストされており、コミュニティへの貢献や拡張が容易になっている。
ヘルプの使用
データセットの取得とインストール
ShareGPT-4o-Imageデータセットは、Hugging FaceまたはGitHubで自由に入手できる。以下に正確な手順を示します:
- データセットへのアクセス:
- ハグする顔のページhttps://huggingface.co/datasets/FreedomIntelligence/ShareGPT-4o-Image。
- またはGitHubリポジトリhttps://github.com/FreedomIntelligence/ShareGPT-4o-Image。
- データセットはParquet形式で保存され、92,256行のデータを含む約20.7MBのサイズである。
- データセットをダウンロード:
- ハギング・フェイスのページで「ダウンロード」ボタンをクリックし、パルケファイルを直接ダウンロードしてください。
- または、Gitコマンドを使ってGitHubリポジトリをクローンする:
git clone https://github.com/FreedomIntelligence/ShareGPT-4o-Image.git - ダウンロードしたら、(必要であれば)ファイルを解凍し、ParquetファイルがPython環境で読めることを確認する。
- 環境準備:
- Python 3.7以降をインストールする。
- 必要な依存ライブラリをインストールする。
pandas和datasetsパーケットファイルをロードして処理する:pip install pandas datasets - Janus-4oモデルをご使用の場合は、以下のインストールが必要です。
torch和transformers:pip install torch transformers
- データセットのロード:
- Pythonの
datasetsライブラリーはデータセットをロードする:from datasets import load_dataset dataset = load_dataset("FreedomIntelligence/ShareGPT-4o-Image") print(dataset) - このデータセットには、テキストの手がかりと生成された画像の対応関係が含まれており、モデルのトレーニングや分析に直接使用することができる。
- Pythonの
ヤヌス-4oモデルの使用
Janus-4oは、ShareGPT-4o-Imageデータセットをベースに微調整されたマルチモーダルモデルであり、テキストから画像への生成と画像編集をサポートする。具体的な手順は以下の通りである:
- 積載モデル:
- ハギング・フェイスからJanus-4-o-7Bモデルをダウンロードする:
from transformers import AutoModelForCausalLM, VLChatProcessor model_path = "FreedomIntelligence/Janus-4o-7B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained( model_path, trust_remote_code=True, torch_dtype=torch.bfloat16 ).cuda().eval() - お使いのデバイスがGPUをサポートし、CUDAがインストールされていることを確認してください。そうでない場合はCPUを使用してください(パフォーマンスが低下します)。[](https://huggingface.co/FreedomIntelligence/Janus-4o-7B)
- ハギング・フェイスからJanus-4-o-7Bモデルをダウンロードする:
- テキストから画像への変換:
- 付属の
text_to_image_generate関数は画像を生成する:def text_to_image_generate(input_prompt, output_path, vl_chat_processor, vl_gpt, temperature=1.0, parallel_size=2, cfg_weight=5): torch.cuda.empty_cache() conversation = [{"role": "<|User|>", "content": input_prompt}, {"role": "<|Assistant|>", "content": ""}] sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts( conversations=conversation, sft_format=vl_chat_processor.sft_format, system_prompt="" ) prompt = sft_format + vl_chat_processor.image_start_tag # 后续生成步骤参考 GitHub 文档 - 砂浜にヤシの木が生え、遠くにヨットが見える夕暮れのビーチの写真」などのサンプルプロンプトを入力します。
- 生成された画像は、指定した
output_path。
- 付属の
- テキスト+画像から画像への編集:
- Janus-4oは入力画像とテキストプロンプトに基づく画像編集をサポートします。例えば、風景画像を入力し、プロンプト「空を星に置き換える」を入力します。
- 手順はtext-to-imageと似ているが、画像へのパスを指定する必要がある。コードはGitHubのリポジトリを参照のこと。
- ドキュメントを見る:
- GitHubリポジトリのREADMEファイルには、詳細なモデルパラメータとセットアップの生成方法が記載されています。
- Hugging Faceのページでは、データセットの構造とサンプルのプレビューも提供しており、データ形式を簡単に理解することができる。
ほら
- データセットとモデルのダウンロードには安定したインターネット環境が必要です。
- GPUを使用したモデル推論の高速化には、少なくとも16GBのグラフィックメモリを推奨。
- モデルの読み込みや生成に問題が発生した場合は、GitHubのIssuesページを参照するか、問題に対するフィードバックを送信してください。
- データセットとモデルはオープンソースであり、コミュニティはデータセットへのコードや改良の貢献を奨励している。
アプリケーションシナリオ
- マルチモーダルモデルの開発
開発者は、ShareGPT-4o-Imageデータセットを使用して、独自のマルチモーダルモデルを訓練または微調整し、アートワークやデザインスケッチの生成などのシナリオで、テキストから画像への生成や画像編集を強化することができます。 - 学術研究
研究者はこのデータセットを使ってGPT-4oの画像生成パターンを分析し、マルチモーダルモデルの意味的整合性と生成品質を探ることができ、人工知能とコンピュータビジョン分野の学術研究に適している。 - クリエイティブなコンテンツ制作
デザイナーやコンテンツ制作者は、Janus-4oモデルを使用して、テキスト記述に基づいて高品質の画像をすばやく生成したり、広告、ゲーム、映画制作などの用途向けに既存の画像をスタイリスティックに編集したりすることができます。 - 教育と指導
教師や生徒は、データセットやモデルを使ってAIの授業を試したり、マルチモーダルモデルがどのように機能するかを学んだり、テキストから画像への生成や画像編集のタスクを練習したりすることができる。
QA
- ShareGPT-4o-Imageデータセットは無料ですか?
そう、このデータセットは完全にオープンソースで、Apache-2.0ライセンスのもと、Hugging FaceとGitHubで自由にダウンロードして使用することができる。 - ヤヌス-4oとGPT-4oの比較は?
Janus-4oは、ShareGPT-4o-Imageデータセットに基づいて微調整されたオープンソースモデルで、テキストから画像への変換や画像編集をサポートしているが、全体的な性能ではGPT-4oにわずかに劣る。 - Janus-4oを実行するには、どのようなハードウェアが必要ですか?
最高のパフォーマンスを得るには、CUDA対応GPU(少なくとも16GBのRAM)を推奨する。 - プロジェクトに貢献するには?
GitHub リポジトリの貢献ガイドラインに記載されているように、コードの貢献、モデルの最適化、データセットの補足のために Pull Requests を提出することができます。































