



RAGLightは、RAG(Retrieval Augmented Generation)を実現するために設計された、軽量でモジュール化されたPythonライブラリです。複数の言語モデル、組み込みモデル、ベクターストアをサポートするRAGLightは、開発者がコンテキストを考慮したAIアプリケーションを迅速に構築するのに適しています。シンプルさと柔軟性を念頭に設計されたRAGLightは、ローカルフォルダやGitHubリポジトリからのデータを簡単に統合し、正確な回答を生成することができます。 Ollama または LMStudio は、ローカライズされたデプロイメントをサポートし、プライバシーやコストに敏感なプロジェクトに適している。
機能一覧
- 複数のデータソースをサポート:ナレッジベースは、ローカルフォルダ(PDFやテキストファイルなど)やGitHubリポジトリからインポートできます。
- モジュラリゼーション RAG パイプライン:文書検索と言語生成を組み合わせ、標準的なRAG、Agentic RAG、RAT(Retrieval Augmented Thinking)モードをサポート。
- 柔軟なモデル統合:以下のような大規模言語用のOllamaおよびLMStudioモデルをサポートしています。
llama3。 - 効率的なベクトルストレージ:ChromaまたはHuggingFace埋め込みモデルを使用して文書ベクトルを生成し、高速な類似検索をサポートします。
- カスタムコンフィギュレーション:エンベッディングモデル、ベクター保存パス、検索パラメーター(例
k(価値)である。 - 文書処理の自動化:指定したソースから文書コンテンツを自動的に抽出し、インデックスを付けることで、ナレッジベースの構築を簡素化します。
ヘルプの使用
設置プロセス
RAGLightのインストールと使用には、Python環境とOllamaまたはLMStudioが動作している必要があります:
- Pythonと依存関係のインストール
Python 3.8以降がインストールされていることを確認してください。以下のコマンドでRAGLightをインストールしてください:pip install raglightHuggingFace組み込みモデルを使用する場合、追加の依存関係をインストールする必要があります:
pip install sentence-transformers - Ollama または LMStudio のインストールと実行
- Ollama (https://ollama.ai) または LMStudio をダウンロードしてインストールする。
- 例えば、オッラマのモデルを引っ張ってくる:
ollama pull llama3 - モデルがOllamaまたはLMStudioにロードされ、実行されていることを確認してください。
- 設定環境
ナレッジベースのデータを準備するためのプロジェクトフォルダを作成します(PDFフォルダやGitHubリポジトリのURLなど)。GitHubまたはHuggingFaceにアクセスするために、インターネット接続が良好であることを確認してください。
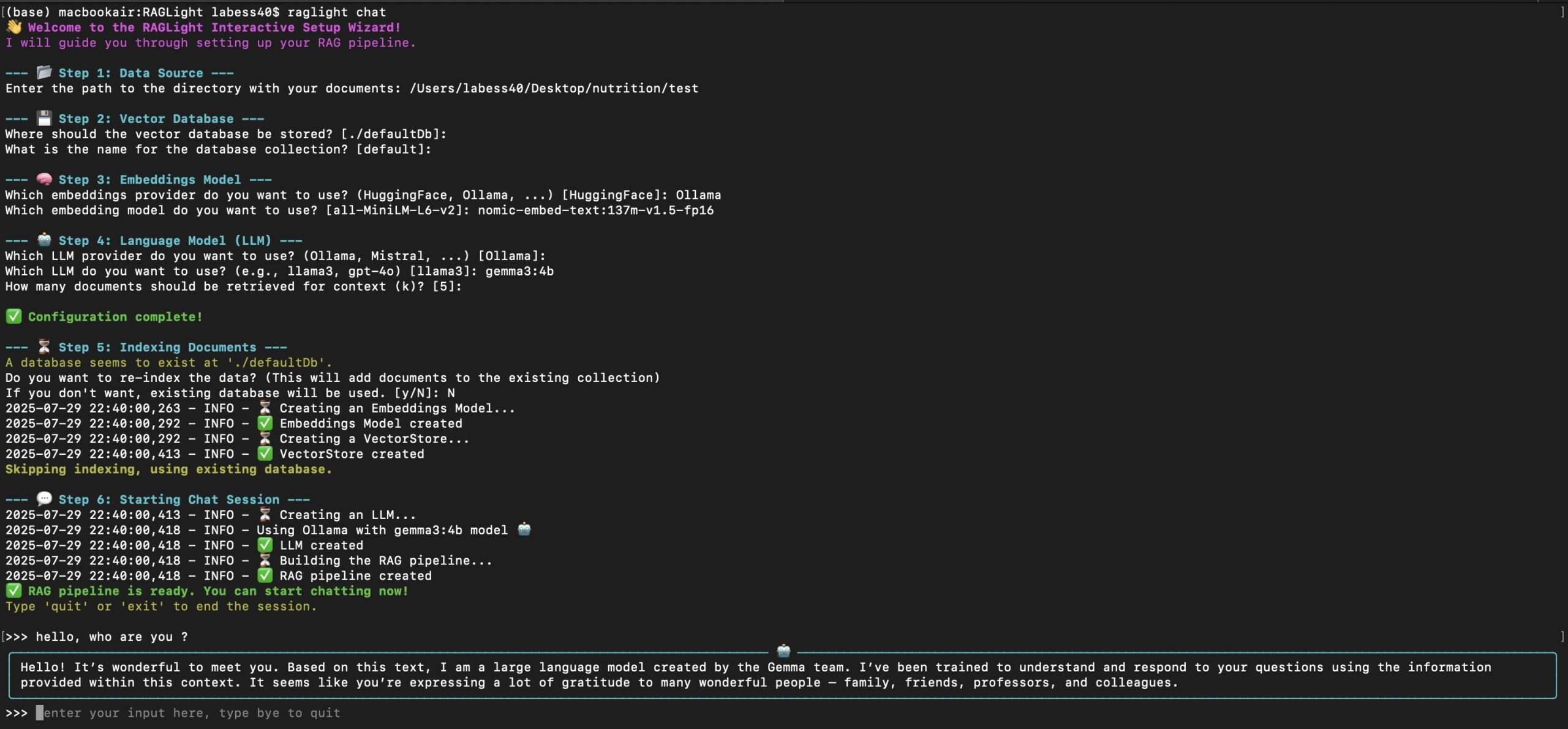
RAGLightでシンプルなRAGパイプラインを作成する
RAGLightは、RAGパイプラインを構築するためのクリーンなAPIを提供します。以下は、ナレッジベースを構築し、ローカルフォルダとGitHubリポジトリから回答を生成する基本的な例です:
from raglight.rag.simple_rag_api import RAGPipeline
from raglight.models.data_source_model import FolderSource, GitHubSource
from raglight.config.settings import Settings
Settings.setup_logging()
# 定义知识库来源
knowledge_base = [
FolderSource(path="/path/to/your/folder/knowledge_base"),
GitHubSource(url="https://github.com/Bessouat40/RAGLight")
]
# 初始化 RAG 管道
pipeline = RAGPipeline(
knowledge_base=knowledge_base,
model_name="llama3",
provider=Settings.OLLAMA,
k=5
)
# 构建管道(处理文档并创建向量存储)
pipeline.build()
# 生成回答
response = pipeline.generate("如何使用 RAGLight 创建一个简单的 RAG 管道?")
print(response)
注目の機能操作
- 複数のデータソースをサポート
RAGLightでは、ローカルフォルダやGitHubリポジトリからデータをインポートすることができます。- ローカルフォルダ:PDFまたはテキストファイルを、指定したフォルダに配置します。
/path/to/knowledge_base。 - GitHubリポジトリ: リポジトリのURL (例.
https://github.com/Bessouat40/RAGLight)、RAGLightは自動的にリポジトリからドキュメントを抽出する。
設定例:
knowledge_base = [ FolderSource(path="/data/knowledge_base"), GitHubSource(url="https://github.com/Bessouat40/RAGLight") ] - ローカルフォルダ:PDFまたはテキストファイルを、指定したフォルダに配置します。
- 標準RAGパイプ
標準的なRAGパイプラインは、文書の検索と生成を組み合わせている。ユーザがクエリを入力すると、RAGLightはクエリをベクトルに変換し、類似検索によって関連する文書の断片を検索し、これらの断片をLLMにコンテキストとして入力し、答えを生成する。
操作手順:- 初期化
RAGPipelineそして、知識ベース、モデルk値(検索された文書の数)。 - 各論
pipeline.build()ドキュメントを処理し、ベクターストアを生成する。 - 利用する
pipeline.generate("查询")答えを得る。
- 初期化
- エージェントのRAGとRATモード
- Agentic RAGスルー
AgenticRAGPipelineを実装し、インテリジェントなボディ機能を追加して、多段階の推論と検索戦略の動的調整をサポートする。
例from raglight.rag.simple_agentic_rag_api import AgenticRAGPipeline from raglight.config.agentic_rag_config import SimpleAgenticRAGConfig config = SimpleAgenticRAGConfig(k=5, max_steps=4) pipeline = AgenticRAGPipeline(knowledge_base=knowledge_base, config=config) pipeline.build() response = pipeline.generate("如何优化 RAGLight 的检索效率?") print(response) - RAT(検索拡張思考)スルー
RATPipeline実現、追加の反射ステップ(reflectionパラメータ)を使用して、回答の論理性と正確性を向上させる。
例from raglight.rat.simple_rat_api import RATPipeline pipeline = RATPipeline( knowledge_base=knowledge_base, model_name="llama3", reasoning_model_name="deepseek-r1:1.5b", reflection=2, provider=Settings.OLLAMA ) pipeline.build() response = pipeline.generate("如何简化 RAGLight 的配置?") print(response)
- Agentic RAGスルー
- カスタムベクターストレージ
RAGLightはChromaをデフォルトのベクターストアとして使用し、HuggingFaceエンベッディングモデルをサポートしている(例all-MiniLM-L6-v2).ユーザー定義可能なストレージパスとコレクション名:from raglight.config.vector_store_config import VectorStoreConfig vector_store_config = VectorStoreConfig( embedding_model="all-MiniLM-L6-v2", provider=Settings.HUGGINGFACE, database=Settings.CHROMA, persist_directory="./defaultDb", collection_name="my_collection" )
取り扱い上の注意
- Ollama または LMStudio ランタイムモデルがロードされていることを確認してください。
- ローカル・フォルダーのパスには有効なドキュメント(PDFやTXTなど)が含まれている必要があり、GitHubリポジトリは一般にアクセス可能でなければならない。
- アダプト
kの値で、検索される文書の数を制御する。k=5通常、効率と精度のバランスを考えて選択するものだ。 - HuggingFace組み込みモデルを使用している場合、HuggingFace APIがネットワークからアクセス可能であることを確認してください。
アプリケーションシナリオ
- 学術研究
研究者は、論文のPDFをローカルフォルダにインポートし、RAGLightを使って文献を素早く検索し、要約を作成したり、質問に答えたりすることができます。例えば、"recent advances in a field"(ある分野における最近の進歩)と入力すると、関連する論文の文脈に応じた回答が得られます。 - 企業知識ベース
社内文書(技術マニュアルやFAQなど)をRAGLightにインポートすることで、インテリジェントなQ&Aシステムを構築することができます。従業員が質問を入力すると、システムがドキュメントから正確な回答を検索・生成します。 - 開発ツール
開発者は GitHub リポジトリのコード・ドキュメントを知識ベースとして利用し、API の使い方やコード・スニペットを素早く調べることができる。例えば、"how to call a function" と入力するとドキュメントが表示されます。 - 教材
先生や生徒は、教科書やコースのノートをRAGLightにインポートして、的を絞った回答や学習の要約を作成することができます。例えば、「概念を説明する」と入力すると、教科書の関連コンテンツにアクセスできます。
QA
- RAGLightはどのような言語モデルをサポートしていますか?
RAGLightは、OllamaやLMStudioが提供する以下のようなモデルをサポートしています。llama3、deepseek-r1:1.5bなど。ユーザーはOllamaまたはLMStudioでモデルをプリロードする必要があります。 - カスタムデータソースを追加するには?
利用するFolderSourceローカル・フォルダのパスを指定する。GitHubSource公開されているGitHubリポジトリのURLを指定します。パスが有効で、ファイル形式がサポートされていることを確認してください(例:PDF、TXT)。 - 検索精度を最適化するには?
増加kより多くのドキュメントを取得するために値を変更するか、RATモードを使用してリフレクションを有効にします。高品質のエンベッディング・モデルを選択する。all-MiniLM-L6-v2)も精度を向上させる。 - クラウド展開に対応しているか?
RAGLightは主にローカルでのデプロイを想定して設計されており、OllamaまたはLMStudioで実行する必要がある。クラウドには直接対応していませんが、コンテナ化(Dockerなど)によりデプロイすることができます。
























