



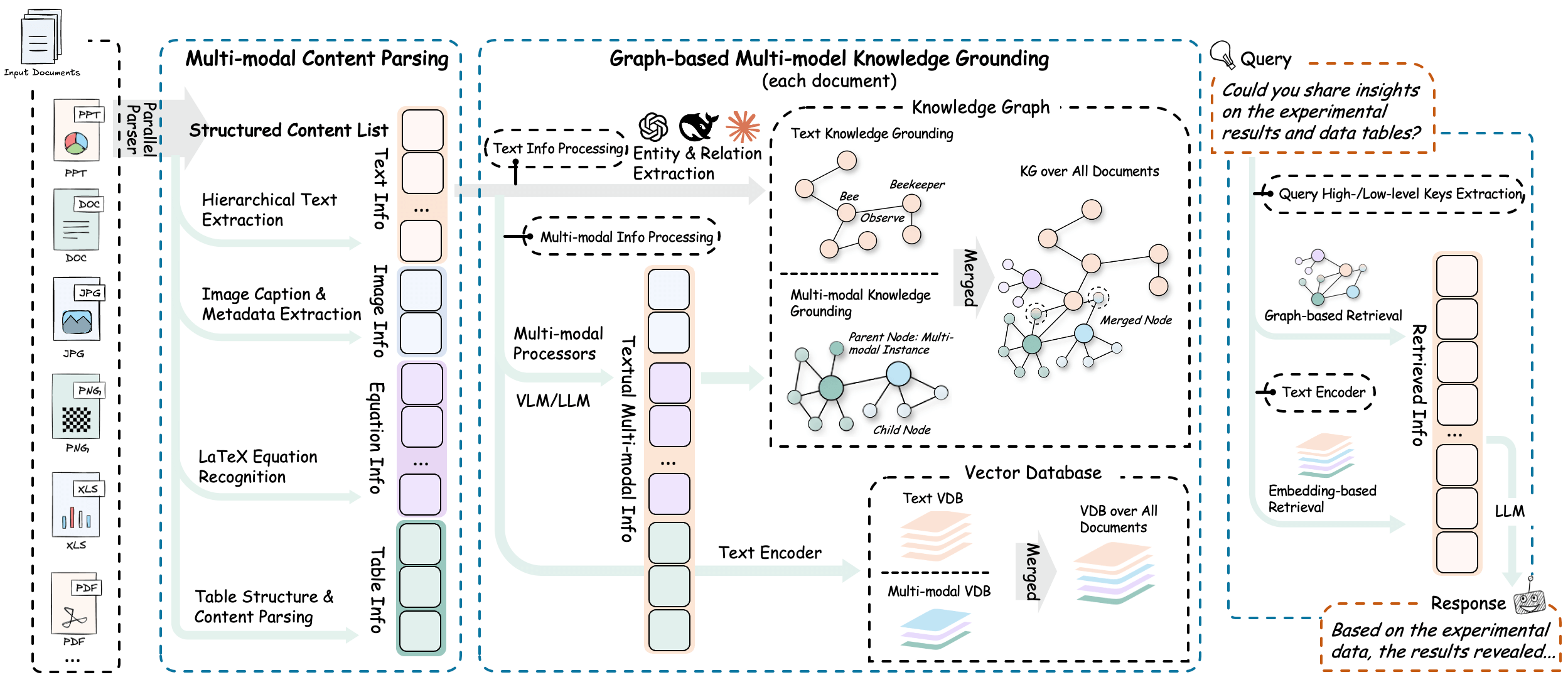
RAG-Anythingは、次のようなプログラムである。 LightRAG 完全に統合されたマルチモーダル文書処理を内蔵 RAG システム従来の質疑応答システム(RAG)のほとんどは、プレーンテキストコンテンツしか扱うことができませんが、PDF、Word文書、プレゼンテーションなど、私たちが日常的に接する文書には、テキスト、画像、表、数式など、複数の種類のコンテンツが含まれていることがよくあります。テキストだけが抽出されると、多くの重要な情報が失われてしまいます。テキストだけが抽出されると、多くの重要な情報が失われてしまいます。RAG-Anythingは、テキスト、画像、表、数式など、複数の要素を含むこれらの複雑な文書を完全に解析することで、この問題を解決し、正確に認識・理解することができます。ドキュメントに含まれるすべての要素を分解・分析し、知識グラフを構築することで、質問をすると、システムがテキストを理解するだけでなく、画像の内容を読み取り、表のデータを分析する。こうすることで、文書内のすべての情報に基づいて、より包括的で正確な回答をすることができる。このシステムは、学術論文、技術マニュアル、財務報告書など、多様な情報を含む文書を扱うのに特に適している。
機能一覧
- 統合処理プロセスドキュメントのアップロードから解析、最終的なインテリジェントな質問と回答まで、すべてのプロセスが完全自動化されています。
- 複数のファイル形式をサポートPDF、Word、PPT、Excel、画像、その他多くの一般的なフォーマットをアップロードすることができます。
- 専用コンテンツアナライザーこのシステムには、画像、表、数式など、さまざまなコンテンツを認識・理解するためのツールが組み込まれています。
- マルチモーダル知識グラフの構築ドキュメントから重要な情報を自動的に抽出し、テキスト、画像、表、その他のコンテンツ間のリンクを確立して知識ネットワークを形成します。
- 柔軟な処理モードユーザーは、システムに文書全体を自動的に解析させるか、すでに整理した内容に直接アクセスさせるかを選択できる。
- ハイブリッド・インテリジェント・サーチ答えを探しているとき、システムはキーワードマッチングと文脈理解の両方を組み合わせて、より正確に情報を探し出します。
- ビジュアル言語モデルユーザが絵を含む質問をすると、システムは自動的にビジュアルモデルを呼び出して、絵の内容を分析し、図形を組み合わせた回答を実現します。
ヘルプの使用
RAG-Anythingは、テキスト、画像、表などを含む文書を解析し、質問することによってこれらの文書と対話することを可能にする強力なツールです。以下は、インストールと使用方法の詳細です。
I. インストール
RAG-Anythingをインストールするには2つの方法があるが、1つ目の方法が簡単なのでお勧めである。
方法1:PyPIから直接インストールする(推奨)
これが最も手っ取り早いインストール方法です。ターミナルかコマンドラインツールを開き、以下のコマンドを入力する:
# 基础安装
pip install raganything
この基本コマンドはコア機能のみをインストールします。現代の文書は様々なフォーマットで提供されており、より多くの種類のファイルを扱うためには、必要に応じて追加機能パックをインストールすることができます。
- サポートされているすべてのファイルタイプを処理したい場合(推奨):
pip install 'raganything[all]' - 画像フォーマット(BMP、TIFF、GIFなど)のみを扱う必要がある場合:
pip install 'raganything[image]' - プレーンテキストファイル(TXT、MDなど)のみを扱う必要がある場合:
pip install 'raganything[text]'
方法2:ソースコードからインストールする
そのコードを研究したり、二次的な開発をしたいのであれば、この方法がいいだろう。
- まず、GitHubからあなたのコンピューターにコードをクローンする:
git clone https://github.com/HKUDS/RAG-Anything.git - プロジェクト・カタログにアクセスする:
cd RAG-Anything - その後、pip経由でインストールする:
pip install -e . - すべてのファイル形式をサポートする必要がある場合は、このコマンドを使用する:
pip install -e '.[all]'
II.環境構成
1.LibreOfficeをインストールする
RAG-Anythingは、フリーのオフィスソフトウェアであるLibreOfficeの助けを借りて、Office文書(.docx、.pptx、.xlsxなど)を扱うことができます。まず、お使いのオペレーティングシステムにインストールしてください。
- Windowsに移動する。 LibreOffice公式サイトダウンロードしてインストールする。
- macOSHomebrewを使ってインストールするのは簡単です。
brew install --cask libreoffice。 - Ubuntu/Debian:: コマンドの使用
sudo apt-get install libreoffice。
2.APIキーの設定
RAG-Anythingは、コンテンツを理解し回答を生成する際に、OpenAIのGPTファミリーのような大規模言語モデル(LLM)を呼び出す必要があります。APIキーが必要です。
プロジェクトフォルダー内に .env ファイルを開き、以下をコピーして自分のキー情報に置き換える。
OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxx"
# 如果你使用代理或者第三方服务,还需要配置这个地址
OPENAI_BASE_URL="https://api.your-proxy.com/v1"
III.使用方法
以下では、RAG-Anythingを使用して文書を処理し、質問する方法の完全な例を説明します。
1.準備作業
まず、RAG-Anythingがインストールされ、APIキーが設定されていることを確認してください。次に、作業したいドキュメントを用意します。 report.pdf 文書の
2.コードを書く
Pythonファイルを作成する。 main.pyそして、そこに以下のコードをコピーしてください。このコードは、ドキュメントの設定と処理から質問までの完全なプロセスを示しています。
import asyncio
from raganything import RAGAnything, RAGAnythingConfig
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
# 异步函数是现代Python中处理高并发任务的方式
async def main():
# 1. 设置你的API密钥和代理地址
api_key = "your-api-key" # 替换成你的 OpenAI API Key
base_url = "your-base-url" # 如果有代理,替换成你的代理地址
# 2. 配置 RAG-Anything 的工作方式
config = RAGAnythingConfig(
working_dir="./rag_storage", # 指定一个文件夹,用来存放处理后的数据
parser="mineru", # 使用mineru解析器
parse_method="auto", # 自动判断解析方式
enable_image_processing=True, # 启用图片处理
enable_table_processing=True, # 启用表格处理
)
# 3. 定义与大语言模型交互的函数
# 文本模型,用于生成回答
def llm_model_func(prompt, **kwargs):
return openai_complete_if_cache(
"gpt-4o-mini",
prompt,
api_key=api_key,
base_url=base_url,
**kwargs,
)
# 视觉模型,用于理解图片内容
def vision_model_func(prompt, image_data=None, **kwargs):
return openai_complete_if_cache(
"gpt-4o",
"",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}]}],
api_key=api_key,
base_url=base_url,
**kwargs,
)
# 嵌入模型,用于将文本转换成向量,方便计算机理解和检索
embedding_func = EmbeddingFunc(
embedding_dim=3072,
func=lambda texts: openai_embed(
texts, model="text-embedding-3-large", api_key=api_key, base_url=base_url
),
)
# 4. 初始化 RAG-Anything 系统
rag = RAGAnything(
config=config,
llm_model_func=llm_model_func,
vision_model_func=vision_model_func,
embedding_func=embedding_func,
)
# 5. 处理你的文档
# 将 "path/to/your/document.pdf" 替换成你自己的文件路径
await rag.process_document_complete(
file_path="path/to/your/document.pdf",
output_dir="./output"
)
# 6. 开始提问
print("文档处理完成,现在可以开始提问了。")
# 示例问题:一个纯文本问题
text_result = await rag.aquery(
"请总结一下这份文档的核心观点,并分析图表传达了哪些主要信息?",
mode="hybrid" # hybrid模式会结合多种方式检索,结果更准
)
print("问题的回答:", text_result)
if __name__ == "__main__":
asyncio.run(main())
3.コードを実行する
のコードを変更する。 your-api-key、your-base-url 和 path/to/your/document.pdf あなたの実際の情報に置き換えてください。そしてこのファイルをターミナルで実行する:
python main.py
プログラムはまず必要なモデルをダウンロードし、次に指定された文書の解析を開始します。この処理は、文書のサイズや複雑さにもよりますが、数分かかる場合があります。処理が完了すると、質問に対する答えが印刷されます。
この例はRAG-Anythingのコアな使い方を示しています。また、ドキュメントのフォルダ全体のバッチ処理や、解析されたコンテンツを直接渡したり、特定の画像やテーブルについて質問したりするような、より高度な機能もサポートしていますので、これらの高度な使い方を調べるには公式ドキュメントをご覧ください。
アプリケーションシナリオ
- 学術研究
RAG-Anythingはこれらの論文を完全に解析することができ、研究者が重要な情報を素早く探し出したり、実験結果の図を理解したり、異なる論文のデータを比較したりするのに役立ち、文献レビューやデータ整理の効率を大幅に向上させます。 - 企業知識管理
企業は通常、大量の技術マニュアル、財務報告書、市場分析、プレゼンテーションなどを社内に保有している。これらのドキュメントは形式が異なり、内容もまちまちです。RAG-Anythingは統一された企業ナレッジベースを構築し、従業員が自然言語で直接質問することができます。例えば、「昨年の第3四半期の売上データのグラフを確認してください」、「XX製品の技術的なアーキテクチャ図を見せてください」など。システムは、異なる文書から関連情報を正確に検索し、提示することができます。 - 金融および法律専門職
財務アナリストや弁護士は、データ表、条項、図表で埋め尽くされた長い報告書や契約文書を読む必要があるが、RAG-Anythingを使えば、主要データを素早く抽出し、契約書の特定の条項を特定し、財務諸表の表を分析して、より正確な意思決定を行うことができる。 - 教育と学習
学生や教師はRAG-Anythingを使って教科書、コースウェア、学習教材を扱うことができます。学生はコースウェアのPDFをアップロードし、その中の図や概念について質問することができます。教師はまた、Q&A教材を素早く作成したり、さまざまなソースから教材を照合したりするために使用することもできます。
QA
- RAG-Anythingは他の通常のRAGツールとどう違うのですか?
最大の違いは、RAG-Anythingがマルチモーダルなコンテンツを扱えることである。通常のRAGツールは、文書中のプレーンテキストのみを抽出し理解することができ、画像、表、数式などの非テキスト情報は無視される。一方、RAG-Anythingは、そのようなコンテンツを認識するために特別に設計されており、絵を読んだり、表データを解析したりすることができるため、文書全体をより包括的に理解することができ、より正確で完全な回答を提供することができる。 - なぜOffice文書(Word、PPT)を扱うときにLibreOfficeをインストールする必要があるのですか?
RAG-Anything自体は、Officeドキュメントの複雑なフォーマットを直接解析するのではなく、強力なオープンソースオフィスソフトウェアであるLibreOfficeを利用します。LibreOfficeを使用して、.docx、.pptxなどのファイルを、コンテンツの抽出と分析の前に、より標準的で作業しやすい中間フォーマットに変換します。つまり、LibreOfficeはこれらのファイルを処理するためのフロントエンドの依存関係なのです。 - このツールは無料ですか?使うのにお金はかかりますか?
RAG-Anythingプロジェクト自体はオープンソースでフリーであり、そのコードを自由にダウンロードして利用することができる。しかし、OpenAIのGPT-4oのような大規模言語モデル(LLM)や埋め込みモデル(EMM)のAPIを呼び出す必要があります。 これらのAPIサービスは通常、使用ごとに課金されます。つまり、あなたのコストは主にこれらのサードパーティAPIを呼び出すためのコストから発生します。 - 文書に手書きの数式や不明瞭なグラフがある場合、それを処理できますか?
処理結果は内容の明瞭さによって異なる。印刷された数式や明瞭な図表の場合は、高い認識精度が得られます。しかし、図が非常に不鮮明であったり、数式が走り書きの手書きであったりすると、システムのOCR(光学式文字認識)モジュールが正確に認識することが難しくなり、最終的な理解度やQ&Aの結果に影響を与える可能性があります。































