



Miraは、自動企業調査に特化した知的ボディAIのリポジトリである。 ユーザーが行う必要があるのは、企業のウェブサイトのURLを提供することだけで、Miraは複数の専門化されたAIインテリジェンスが連携して動作するシステムを起動する。これらのインテリジェンスはそれぞれ、企業のウェブサイトページの発見とクロール、リンクトインの公開プロフィールの分析、グーグル検索結果の統合を担当する。重要な事実を自動的に抽出し、外部ソースをチェックし、最終的に構造化された企業プロフィールを生成する。Miraの中心は、フレームワークにとらわれないライブラリで、npmパッケージとして既存のアプリケーション、データパイプライン、またはカスタムワークフローに簡単に統合することができる。理解しやすく使いやすいように、このプロジェクトはサンプルオペレーターインターフェースとしてNext.jsフロントエンドアプリケーションも提供しています。
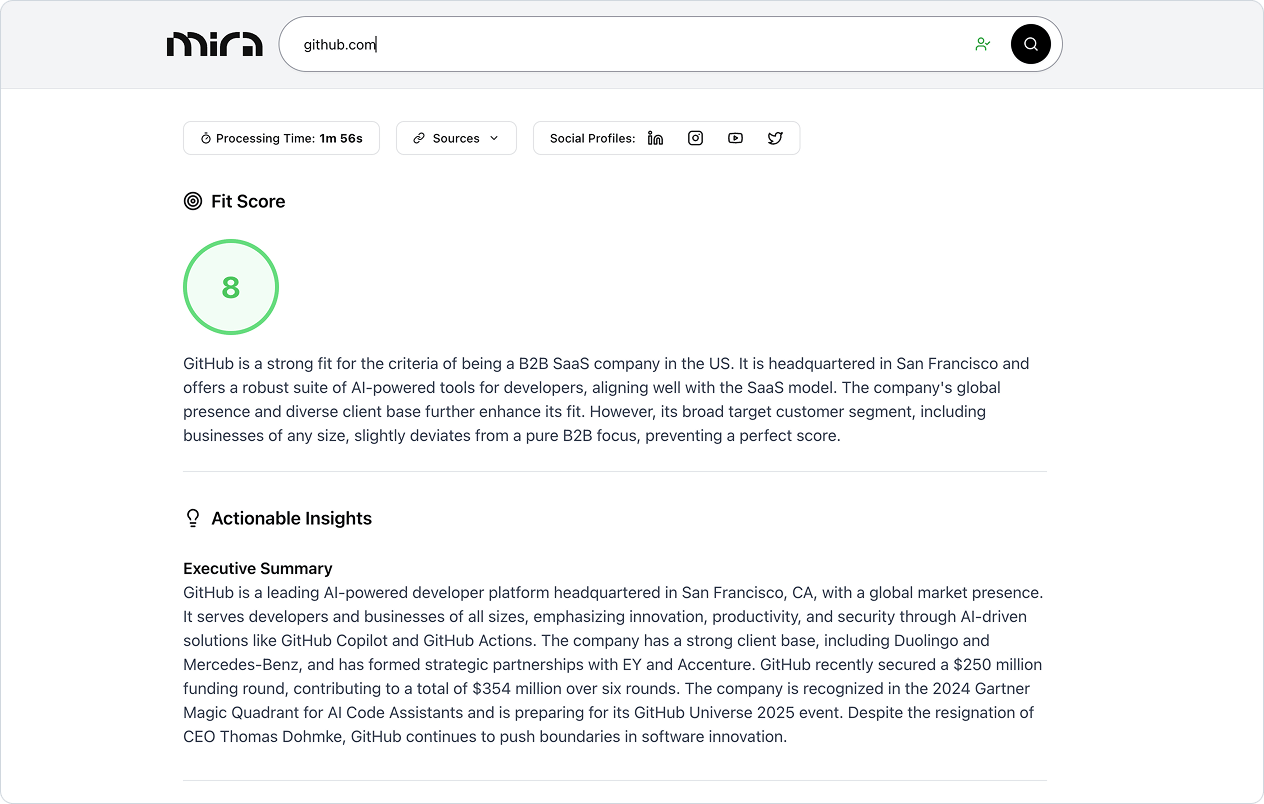
機能一覧
- マルチインテリジェント・ボディ・アーキテクチャ(MIBA)このシステムには、企業情報の発見、イントラネット・ページのクロール、コラージュ・データの収集、グーグル検索、総合的な分析を処理する複数の専門インテリジェンスが含まれており、最終的に結果を統合して統一された企業像を作成する。
- 柔軟でカスタマイズ可能ユーザーは、インテリジェンスの動作、取得するデータポイント、プロンプトを簡単に変更し、特定のワークフローや研究ニーズに適応させることができます。
- リアルタイム進行イベント研究タスクの実行中、システムは構造化されたイベントを発行し、ユーザーはリアルタイムでタスクの進捗状況を追跡し、表示することができます。
- 信頼度スコアとソース帰属抽出された各情報には信頼度スコアが含まれ、出典が明記されているため、調査結果の透明性が確保されている。
- カンパニー・スタンダード・マッチユーザー定義の基準に照らして対象企業を評価し、マッチングスコアと詳細な分析根拠を提供します。
- 内蔵データ収集サービスウェブクローリング、Google検索、Collabsからのデータ収集、そしてクッキー同意バナーの自動化まで対応する統合サービス。
- 組み込みのビジネスプロセスの調和このシステムは、個々のインテリジェンスのタスクを自動的に調整し、結果を統合し、すべてのデータソースを統一的に管理することができる。
- コンポーザブル・コア・ライブラリコア・ライブラリはフレームワークにとらわれず、Node.jsやTypeScriptのプロジェクトで簡単に使えるようにnpmパッケージとして配布できる。
- サンプル・フロントエンド・インターフェースこのプロジェクトは、Next.jsをベースとしたサンプルウェブサイトを提供し、コアライブラリの呼び出し方と、研究の実行と結果の閲覧のためのシンプルなインターフェイスを提供します。
ヘルプの使用
Miraの中核は強力なライブラリだが、このプロジェクトは、ローカル環境で簡単に実行しテストできる完全なフロントエンド・アプリケーションも提供している。Miraは2つの方法で使用できる。
1.フロントエンドインターフェースを持つ完全なアプリケーションをローカルで実行する。
このアプローチは、Miraの機能を手っ取り早く味わいたい開発者に最適である。
環境要件:
- Node.js(バージョン18以上)
npm(通常はNode.jsと一緒にインストールされます)- OpenAI APIキー
- ScrapingBee APIキー
インストール手順:
- クローン・コード・リポジトリ
まずgitプロジェクトのコードをローカル・コンピューターにクローンする:git clone https://github.com/dimimikadze/mira.git - プロジェクト・ディレクトリに移動し、依存関係をインストールする。
クローンしたフォルダに移動してnpmプロジェクトに必要な依存パッケージをすべてインストールする。cd mira npm install - 環境変数の設定
APIキーなどの機密情報は、環境変数で設定する必要がある。そのためには.env.localファイルこのファイルはpackages/mira-frontend/カタログ
プロジェクトのルート・ディレクトリで以下のコマンドを実行すれば、すぐに作成・編集できる:# 注意:请在项目根目录(mira/)下执行此命令 touch packages/mira-frontend/.env.local次に、このファイルをコード・エディターで開き、APIキーを以下のフォーマットで記入する:
OPENAI_API_KEY=sk-xxxx SCRAPING_BEE_API_KEY=xxxxを含めてください。
sk-xxxx和xxxxキーを自分のものと交換する。 - フロントエンド・アプリケーションの実行
上記の手順が完了したら、以下のコマンドを実行して開発サーバーを起動する:npm run dev:mira-frontend起動に成功すると、ターミナルはローカルURL(通常は
http://localhost:3000).このURLをブラウザで開くと、Miraのインターフェイスが表示され、使い始めることができる。
2. NPM パッケージとしてプロジェクトに組み込む
Miraの自動調査機能を自分のアプリケーションに統合したい場合は、npmパッケージとして直接使用することができる。
取り付け:
Node.jsまたはTypeScriptプロジェクトに、以下のコマンドでインストールする。mira-aiコアライブラリ: "`bash
npm install mira-ai
**使用方法**:
安装后,你可以在你的代码中导入`researchCompany`函数来调用Mira的核心功能。下面是一个基本的使用示例:
```javascript
import { researchCompany } from "mira-ai";
async function runResearch() {
// 配置API密钥
const config = {
apiKeys: {
openaiApiKey: process.env.OPENAI_API_KEY,
scrapingBeeApiKey: process.env.SCRAPING_BEE_API_KEY,
},
};
// 定义研究参数和回调函数
const options = {
// 你可以提供一个自定义的公司标准,让AI进行评估
companyCriteria: "B2B SaaS领域的公司,且员工人数超过50人",
// onProgress是一个回调函数,用于接收实时进度更新
onProgress: (event) => {
console.log("实时进度事件:", event);
},
};
try {
// 调用函数,传入公司网址、配置和选项
const result = await researchCompany("https://www.example.com", config, options);
// 打印最终的研究结果
console.log(result);
} catch (error) {
console.error("研究过程中发生错误:", error);
}
}
// 确保在运行前已设置好环境变量 OPENAI_API_KEY 和 SCRAPING_BEE_API_KEY
runResearch();
この例ではresearchCompanyこの関数は3つの引数を取ります。会社のURL、APIキーを含む設定オブジェクト、そしてオプションの引数オブジェクトです。設定オブジェクトはonProgressコールバックを使用すると、研究の進捗状況をリアルタイムで表示するユーザーインターフェイスを構築できます。
アプリケーションシナリオ
- 営業チーム
営業チームはMiraを使ってリード生成プロセスを自動化できる。 理想的な顧客プロファイルをスクリーニング基準として定義し、多数の企業を一括調査して精度の高いターゲット顧客リストを作成することができます。調査レポート内の、技術スタック、最近のニュース、資金調達などの詳細な企業情報は、営業担当者がコンバージョン率を大幅に向上させる高度にパーソナライズされたアウトリーチキャンペーンを実施するのに役立ちます。 - 投資家
投資家、特にベンチャーキャピタル組織は、日々多数の新興企業をスクリーニングする必要があり、Miraは様々な企業のファンダメンタルズを迅速に評価するのに役立ちます。 投資家は、独自の投資基準(業界、企業規模、創業者の経歴など)を設定し、Miraにターゲット企業のリストの初期スクリーニングと調査を任せることで、最も有望な投資機会に労力を集中させることができます。 - 募集委員
採用担当者はMiraを使ってターゲット企業のリストを作成し、より正確に候補者を見つけることができる。 採用担当者は、「主要な開発言語としてRustを使用する企業」など、特定のフィルターを設定することで、条件を満たす企業を特定し、その企業の詳細に基づいて採用戦略を調整することで、より効果的に適切な人材を獲得することができます。 - 市場調査員
市場調査員は、特定の業界内の複数の企業を並べて比較分析する必要があります。Miraは、生成されたすべての企業プロファイルが統一されたフォーマットとデータ構造に従っていることを保証し、データの一貫性と比較可能性を大幅に改善します。 研究者は、業界内の複数の企業を一度に処理し、1つの統一されたビューで結果を確認し分析することができ、手作業でデータを収集し照合する時間を大幅に節約できます。
QA
- ミラとは?通常のチャットボットとの違いは?
Miraは、企業調査の自動化に使用される知的体のAIライブラリである。受動的に質問に答えるチャットボットではなく、複数のAI知能が能動的に協力するシステムだ。 企業のURLを与えると、その企業のウェブサイト、Collab、Google検索など複数のチャネルに積極的にアクセスして情報を収集・照合し、最終的に構造化された企業レポートを生成する。 - Miraを使用するにはどのようなAPIキーが必要ですか?
Miraは、外部サービスが正しく機能するために2つのAPIキーを必要とします。OPENAI_API_KEYもうひとつは、AIインテリジェンスの推論と調整能力を推進するために使われる「AIインテリジェンス」である。SCRAPING_BEE_API_KEYこれは、サイトによってブロックされるのを避けるために、ウェブクロールやグーグル検索を実行するために使用されます。 - Miraが収集する情報をカスタマイズできますか?
Miraは柔軟に設計されており、インテリジェンス、収集するデータポイント、および質問を分析するためのプロンプト(促し)を簡単にカスタマイズできます。ワークフローとアウトプットを特定のリサーチニーズに合わせてカスタマイズできます。 - Miraは既存の顧客関係管理(CRM)システムに統合できますか?
Miraの中核はスタンドアロンライブラリであり、APIコールを介してCRM、データ分析プラットフォーム、または社内ワークフローを含む、あらゆる外部システムに簡単に統合することができます。 このようにして、Miraが生成した調査レポートをCRMに自動的にフィードし、セールスリードに豊富なコンテキスト情報を追加することができます。































