



MCPMarkは、大規模なモデル知能(Agentic)の能力を評価するためのベンチマークテストです。モデルコンテキストプロトコル(MCP)を統合したさまざまな実際のソフトウェア環境でストレステストを行うことで、複雑なタスクを計画、推論、実行するモデルの自律性のレベルを測定します。テスト環境は、Notion、GitHub、ファイルシステム、Postgresデータベース、Playwrightなどの主流ツールを幅広くカバーしている。研究者やエンジニアのために設計されたこのプロジェクトは、安全なサンドボックス機構、再現可能な自動タスク、統一された評価メトリクスを通じて、客観的で信頼性の高い評価プラットフォームを提供します。
機能一覧
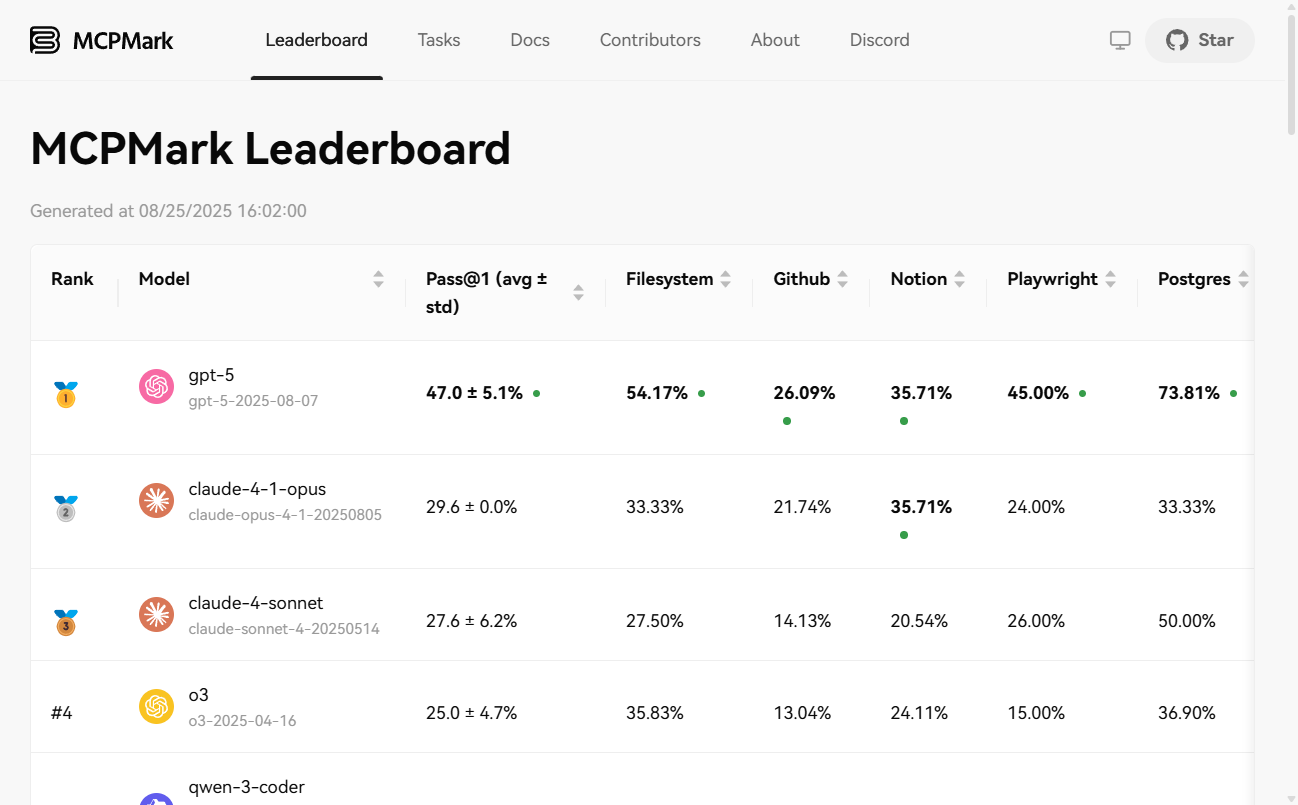
- 多彩なテスト環境現実的で複雑な6つのソフトウェア環境でのテストをサポート。
Notion、GitHub、Filesystem、Postgres、Playwright和Playwright-WebArena。 - 自動タスク検証各テストタスクには、タスク完了の客観的かつ再現可能な評価を可能にする、厳格な自動検証スクリプトが付属しています。
- 安全なサンドボックス機構すべてのタスクは独立したサンドボックス環境で実行され、タスク終了時に破棄されるため、ユーザーの個人情報が漏れたり汚染されたりすることはありません。
- 自動更新の不履行ネットワーク変動などのPipeline Errorにより実験が中断された場合、実験が完了したタスクは自動的にスキップされ、実験が再実行される際に、以前に失敗したタスクが再試行されます。
- 豊富な評価指標:: 以下のような複数の集約されたメトリクスの生成をサポートする。
pass@1、pass@K、pass^K和avg@Kこれは、モデルの1回の成功率と複数回の試行における安定性を総合的に測るために使用される。 - 柔軟な展開オプションPipによるローカル(macOS, Linux)インストールをサポートし、迅速なデプロイと運用のためのDockerイメージも提供します。
ヘルプの使用
MCPMarkの評価モデルを使用する場合、通常以下の4つのステップを踏む:
1.MCPMarkのインストール
ローカルにインストールするか、Dockerを使うかを選択できる。
現地設置(ピップ)。
# 从GitHub克隆仓库
git clone https://github.com/eval-sys/mcpmark.git
cd mcpmark
# 安装依赖
pip install -e .
Dockerのインストール。
# 克隆仓库后,直接构建Docker镜像
./build-docker.sh```
### **2. 授权服务**
如果你需要测试GitHub或Notion相关的任务,你需要先根据官方文档进行授权,让MCPMark能够以编程方式访问这些服务。
### **3. 配置环境变量**
在项目根目录创建一个名为<code>.mcp_env</code>的文件,并填入你需要的模型API密钥和相关服务的授权凭证。
```dotenv
# 示例:配置OpenAI模型
OPENAI_BASE_URL="https://api.openai.com/v1"
OPENAI_API_KEY="sk-..."
# 示例:配置GitHub
GITHUB_TOKENS="your_github_token"
GITHUB_EVAL_ORG="your_eval_org"
# 示例:配置Notion
SOURCE_NOTION_API_KEY="your_source_notion_api_key"
EVAL_NOTION_API_KEY="your_eval_notion_api_key"
4.運用評価実験
必要に応じて、さまざまな範囲のタスクを実行できる。
# 假设实验名为 new_exp,模型为 gpt-4.1,环境为 notion,运行K次
# 评估该环境下的所有任务
python -m pipeline --exp-name new_exp --mcp notion --tasks all --models gpt-4.1 --k K
# 评估一个任务组 (例如 online_resume)
python -m pipeline --exp-name new_exp --mcp notion --tasks online_resume --models gpt-4.1 --k K
5.結果の表示と集計
結果はJSONとCSV形式で./results/ディレクトリに保存されます。実行回数Kが1より大きい場合は、以下のコマンドを実行して集計レポートを作成することができます。
python -m src.aggregators.aggregate_results --exp-name new_exp
アプリケーションシナリオ
- モデルの知的ボディ能力の評価
研究機関や開発者はこのベンチマークを利用することで、単純なAPI呼び出しだけでなく、複雑なワークフローを扱う際に、さまざまな最先端のAIモデルが自律的に計画を立て、推論し、ツールを使用する能力を客観的に測定することができる。 - AIインテリジェンス・ボディ回帰テスト
AIスマートボディアプリケーションを開発するチームにとって、MCPMarkは、モデルやアプリケーションのアップデートを繰り返しても、スマートボディの機能が低下しないことを確認するための標準的なリグレッションテストセットとして使用することができます。 - 知的身体AIの学術研究
学者はこの標準化されたプラットフォームを使って、AI知能の能力に関する再現可能な研究結果を発表し、この分野全体を発展させることができる。 - ビジネス・プロセスの自律性レベルの検証
組織はMCPMarkを使用して、AIモデルが特定のビジネスシナリオ(コードリポジトリ管理やデータベース操作など)で達成できる自律的自動化のレベルをテストすることができる。
QA
- MCPMarkとは何ですか?
これは標準的なベンチマークツールであり、一般ユーザー向けのAIアプリケーションではない。その中心的な目的は、異なるAIマクロモデルが「エージェント」として複雑なタスクを自律的に実行する能力を科学的に評価し、比較するための信頼できる環境とタスクのセットを提供することである。 - MCP(モデル・コンテキスト・プロトコル)とは?
MCP(モデルコンテキストプロトコル)とは、AIマクロモデルが外部のツールやソフトウェア環境と相互作用する方法を規定する技術標準とプロトコルのセットである。MCPMarkは、モデルとその環境との相互作用が制御、測定、再現可能であることを保証するために、このプロトコルのセットに基づいて構築されている。 - MCPMarkテストを実行しても大丈夫ですか?
はい、非常に安全です。各実験用に作成された完全に隔離されたサンドボックス環境で実行されます。ミッションが終わり次第、この環境は完全に破壊されるため、ローカルマシン上の個人ファイルやアカウントデータに触れたり、変更されたりすることはありません。 - パス@Kインジケーターとは何ですか?
pass@Kはモデルの信頼性の重要な尺度である。K回の独立した試行のうち、モデルが少なくとも1回はタスクを成功させる確率を示す。この指標が高ければ高いほど、知能体としてタスクを完了するモデルの能力が安定しており、信頼性が高いことを意味する。
































