



LangExtractはGoogleが開発したオープンソースのPythonライブラリで、非構造化テキストから構造化データを抽出することに特化している。このライブラリは、Google言語モデルのような大規模言語モデル(LLM)を利用します。 Gemini LangExtractシリーズは、正確な原文の位置決めとインタラクティブな視覚化を組み合わせることで、ユーザが複雑なテキストを明確なデータ形式に素早く変換するのに役立ちます。LangExtractは、特に長い文書を扱うのに適しており、並列処理や複数回の抽出をサポートし、ヘルスケアや文学分析などの分野で広く使用されています。このツールはApache 2.0ライセンスの下でリリースされ、コードはGitHubでホストされており、オープンなコミュニティによる貢献があります。
機能一覧
- 多言語モデルのサポート:Google Geminiやその他のクラウドベースのモデルと互換性があります。 Ollama ユーザーのニーズに柔軟に適応するローカルモデリング。
- 構造化情報抽出: 構造化されていないテキストからエンティティ、関係、属性を抽出し、JSONL形式の出力を生成します。
- インタラクティブな視覚化:抽出結果からHTMLの視覚化ファイルが生成され、ユーザーは抽出されたエンティティを簡単に表示して分析することができます。
- 長文処理:インテリジェントなチャンキングと並列処理により、小説全体や医学レポートなどの非常に長いテキストを効率的に処理します。
- カスタマイズされた抽出タスク: キューワードと一握りの例を使用して、特定のドメインに適用可能な抽出ルールをすばやく定義します。
- 医療用テキスト処理:医療分野の臨床記録から薬剤名、用法、その他の情報の抽出をサポートします。
- API統合:クラウドベースのモデルAPIコールをサポートし、サードパーティのローカルモデル推論エンドポイントにも拡張可能。
ヘルプの使用
設置プロセス
LangExtractはPythonで開発されており、最新のPythonパッケージ管理方法をサポートしています。詳しいインストール手順は以下の通りです:
- クローン・コード・リポジトリ
ターミナルを開き、以下のコマンドを実行してLangExtractリポジトリをクローンします:git clone https://github.com/google/langextract.git cd langextract - 依存関係のインストール
pipを使用してLangExtractをインストールします。コードの修正には開発モードを推奨します:pip install -e .開発環境またはテスト環境が必要な場合は、追加の依存関係をインストールする:
pip install -e ".[dev]" # 包含 linting 工具 pip install -e ".[test]" # 包含 pytest 测试工具 - APIキーの設定(クラウドベースのモデルの使用など)
Google Geminiのようなクラウドモデルを使用する場合は、APIキーを設定する必要があります。キーを.envドキュメンテーションcat >> .env << 'EOF' LANGEXTRACT_API_KEY=your-api-key-here EOFキーを保護するには
.env到.gitignore:echo '.env' >> .gitignoreローカルモデル(例えばOllamaを通して実行される)はAPIキーを必要としない。
- インストールの確認
以下のコマンドを実行して、インストールが成功したかどうかを確認する:python -c "import langextract; print(langextract.__version__)"
使用方法
LangExtractの中核機能は、プロンプトの単語や例文を通してテキストから構造化データを抽出することです。以下はその手順である:
1.基本情報の抽出
テキストから文字、感情、関係を抽出したいとすると、コード例は次のようになる:
import langextract as lx
import textwrap
# 定义提示词
prompt = textwrap.dedent("""
Extract characters, emotions, and relationships in order of appearance. Use exact text for extractions. Do not paraphrase or overlap entities.
""")
# 提供示例
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks?",
extractions=[
{"entity": "Romeo", "type": "character", "emotion": "hopeful"},
]
)
]
# 输入文本
text = "ROMEO. But soft! What light through yonder window breaks? It is Juliet."
# 执行提取
result = lx.extract(text, prompt=prompt, examples=examples, model="gemini-2.5-flash")
# 保存结果
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
実行後、抽出結果は extraction_results.jsonl ファイルには、抽出されたエンティティとその属性が含まれる。
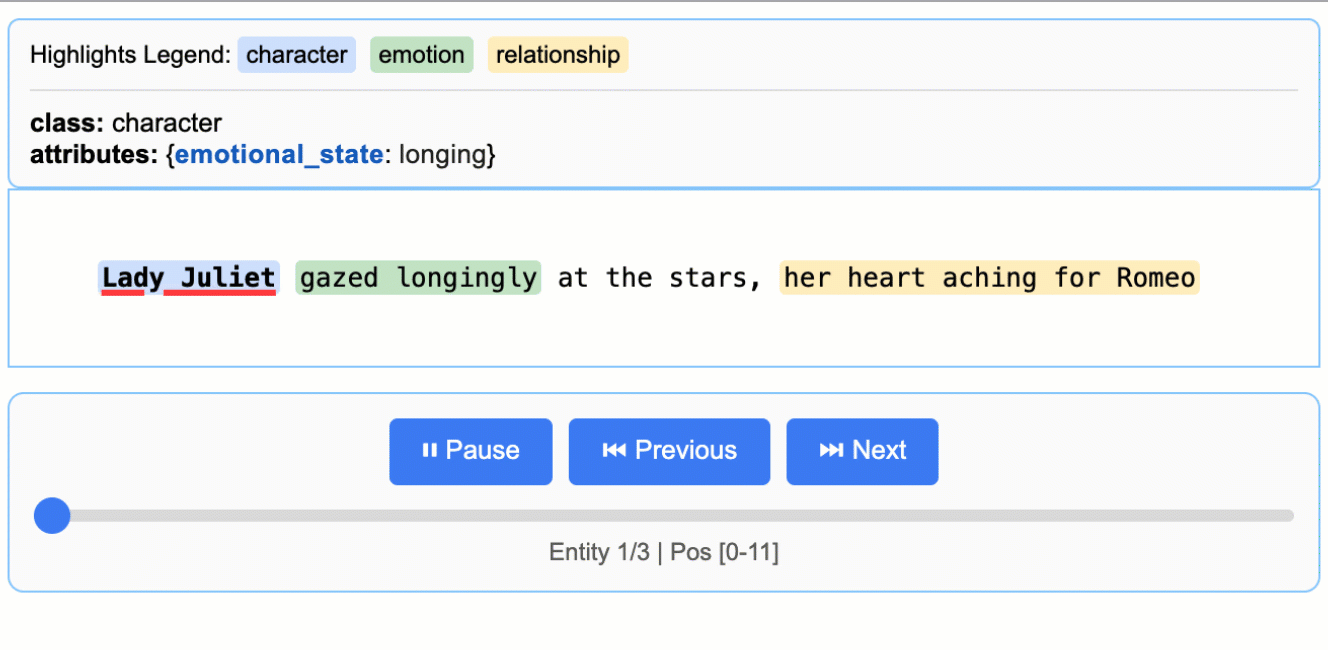
2.インタラクティブなビジュアライゼーションの作成
LangExtractは、抽出結果のHTMLビジュアライゼーションを生成し、見やすくします:
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)
生成された visualization.html ファイルはブラウザで開くことができ、抽出されたエンティティとそのコンテキストが表示される。
3.長い文書の取り扱い
長いドキュメント(ロミオとジュリエットの本全体のような)には、LangExtractはインテリジェントなチャンキングと並列処理を使用します:
url = "https://www.gutenberg.org/files/1513/1513.txt"
result = lx.extract_from_url(url, prompt=prompt, examples=examples, max_workers=4)
lx.io.save_annotated_documents([result], output_name="long_doc_results.jsonl")
max_workers パラメータは並列処理のスレッド数を制御し、大きなファイルの処理に適している。
4.医療テキストの抽出
LangExtractは医療分野を得意とし、薬品名、用量、その他の情報を抽出します。例
prompt = "Extract medication names, dosages, and administration routes from clinical notes."
text = "Patient prescribed Metformin 500 mg orally twice daily."
result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro")
その結果、以下のような医薬品情報が抽出される:
{"entity": "Metformin", "dosage": "500 mg", "route": "orally"}
注目の機能操作
- モデルの選択デフォルトは
gemini-2.5-flashスピードと品質のバランスが取れたモデル。複雑な作業にはgemini-2.5-pro:result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro") - マルチラウンド抽出複雑な文書の複数抽出で精度を向上:
result = lx.extract(text, prompt=prompt, num_passes=2) - RadExtract デモ: LangExtractは放射線科レポートに特化したRadExtractのオンラインデモを提供します。HuggingFace Spaces (
https://google-radextract.hf.space)をインストールせずに試すことができる。
ほら
- クラウドモデルは、安定したAPIキーとネットワーク接続を必要とする。
- 非常に長い文書を処理する場合は、レート制限を避けるためにTier 2 Geminiクォータを使用することをお勧めします。
- APIキーを保存する際に
.env文書セキュリティ。
アプリケーションシナリオ
- 医療データ処理
病院や研究機関では、LangExtractを使用して、クリニカルノートや放射線科レポートから薬剤、投与量、診断などの情報を抽出することができます。例えば、放射線科レポートは、データ分析や臨床上の意思決定を容易にするために、見出しやキーエンティティを含むフォーマットに構造化することができます。 - ぶんしょう
研究者は、長い文学作品から登場人物、感情、人間関係を抽出することができる。例えば、『ロミオとジュリエット』の登場人物のやりとりを分析し、登場人物の関係性のネットワークを研究するために視覚化を行う。 - ビジネス・インテリジェンスの抽出
企業は、市場分析や競合情報収集のために、ニュース、レポート、ソーシャルメディアから主要なエンティティ(企業名、製品、イベントなど)を抽出することができます。 - 法的文書
法律事務所は、契約書や法的文書から条項、日付、当事者、その他の情報を抽出し、構造化された要約を迅速に作成することができます。
QA
- LangExtractは無料ですか?
LangExtractはオープンソースツールで、コードは無料で使用できます(Apache 2.0ライセンス)。ただし、クラウドベースモデル(Geminiなど)を使用する場合はAPIコール料金が発生します。 - ローカルモデルはサポートされているか?
Ollamaを通じて、APIキーなしでローカルのオープンソースモデルを実行することができます。 - 非常に長い文書はどのように扱えばよいですか?
スマート・チャンキングと並列処理の使用(セットアップ)max_workersを複数回抽出することが推奨される。num_passes)の精度を向上させる。 - ビジュアライゼーションの結果はどのように表示されますか?
うごきだすlx.visualize抽出結果をインタラクティブに表示するために、ブラウザで開くことができるHTMLファイルを生成します。 - 医療用アプリはコンプライアンスに適合しているか?
LangExtractはデモツールであり、医療診断機器ではありません。健康関連のアプリケーションは、Health AI Developer Foundationsの利用規約に従います。





























