



DeepSeek-OCRは、DeepSeek-AIによって開発され、オープンソース化された光学式文字認識(OCR)ツールです。 大規模言語モデル(LLM)の観点から視覚コーダーの役割を再考する「文脈的光学圧縮」と呼ばれる新しいアプローチを提案しています。 単に画像内のテキストを認識するのではなく、このツールは文書ページのような長いテキストコンテンツを画像にレンダリングし、それをより小さな「視覚トークン」の集合に圧縮する。 次に言語モデルデコーダが、これらのビジョン・トークンから元のテキストを再構築する。このアプローチでは、入力トークンの数を7~20分の1に減らすことができるため、大規模なモデルでも、非常に長い文書を処理するのに使用する計算資源が少なくて済み、処理効率と処理速度が向上する。 このプロジェクトはMITオープンソースライセンスに従っている。
機能一覧
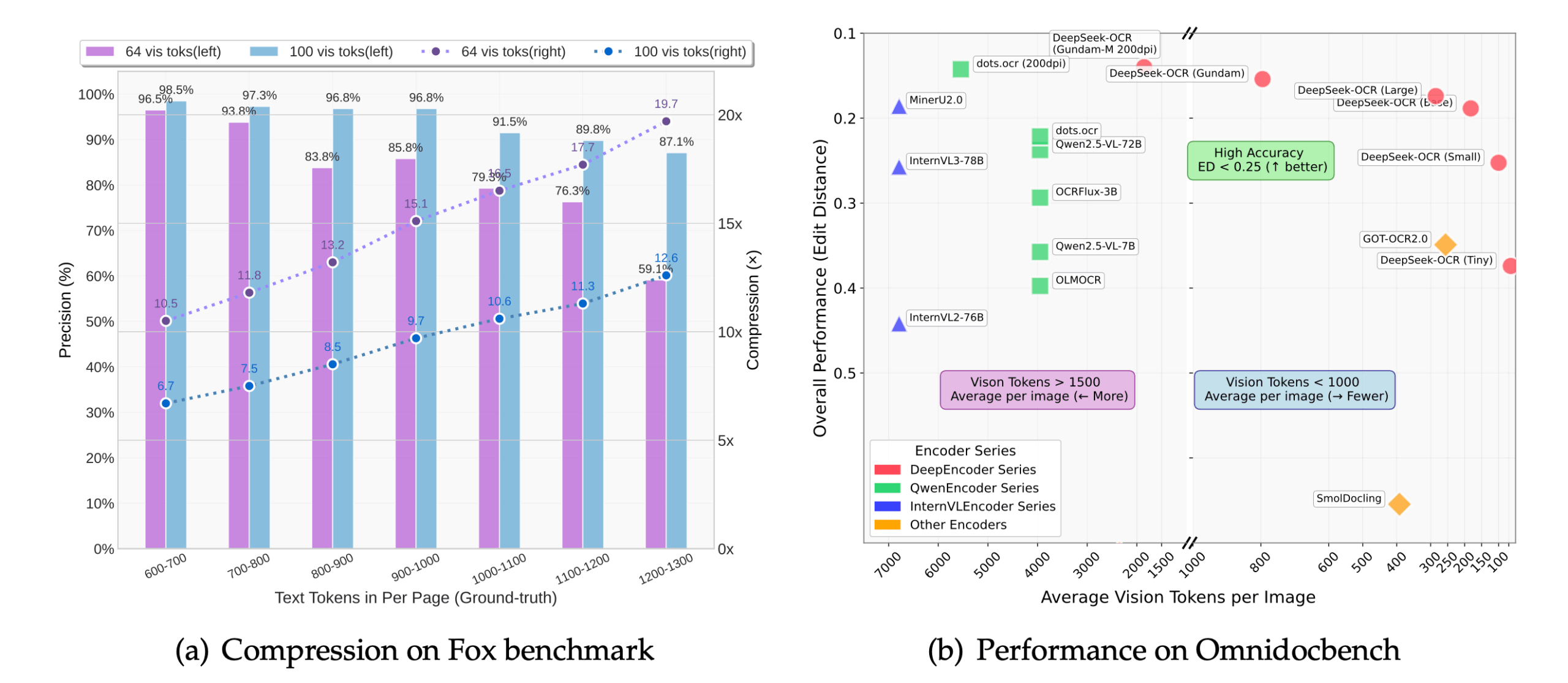
- コンテクスチュアル光圧縮画像をビジュアル・トークンに圧縮することで、モデルが処理するデータ量を劇的に減らし、メモリ使用量を削減し、推論速度を向上。
- 高精度の認識10倍圧縮でも、約97%の認識精度を達成し、文書のレイアウト、タイポグラフィ、空間関係を保持することができます。
- 構造化出力ドキュメント、特に複雑なレイアウト(表、リスト、見出しなど)を含むページを、元のテキストの構造を保持したまま直接Markdownフォーマットに変換する機能。
- マルチタスク対応入力プロンプトの単語(Prompt)を変更することで、モデルはさまざまなタスクを実行することができます:
- 文書全体をMarkdownに変換する。
- 画像の一般的なOCR認識。
- ドキュメント内のチャートを解析する。
- 画像の内容を詳しく説明してください。
- 複数の解像度モード512×512から1280×1280までの幅広い固定解像度と、超高解像度のドキュメントを処理するためのダイナミック解像度モードをサポート。
- ハイパフォーマンス推論vLLMとTransformersフレームワークと統合され、A100-40G GPUでPDFファイルを処理する場合、約2500トークン/秒の速度に達することができます。
- 手書き認識良好な照明と解像度の下で、従来の多くのOCRツールよりも優れた手書きコンテンツを認識します。
ヘルプの使用
DeepSeek-OCR のインストールと使用は、主に開発者向けであり、一定のプログラミングの基礎が必要です。以下はその詳細な操作手順で、主に環境設定、インストール、コード推論の 3 つのパートに分かれています。
ステップ1:環境準備
公式の推奨環境は、CUDA 11.8とPyTorch 2.6.0だ。始める前に、GitとCondaをインストールする必要がある。
- プロジェクト・ウェアハウスのクローン
まず、公式 DeepSeek-OCR コードベースを GitHub からローカル・コンピュータにクローンします。ターミナル(コマンドラインツール)を開き、以下のコマンドを入力します:git clone https://github.com/deepseek-ai/DeepSeek-OCR.git実行すると、カレント・ディレクトリに
DeepSeek-OCRフォルダの - Conda環境の作成と有効化
コンピュータ上の他のPythonプロジェクトとの依存関係の衝突を避けるために、別のConda仮想環境を作成することを推奨します。# 创建一个名为deepseek-ocr的Python 3.12.9环境 conda create -n deepseek-ocr python=3.12.9 -y # 激活这个新创建的环境 conda activate deepseek-ocrアクティベーションに成功すると、端末のプロンプトの前に次のように表示されます。
(deepseek-ocr)言葉だ。
ステップ 2: 依存関係のインストール
起動したConda環境では、モデルの実行に必要なPythonライブラリをインストールする必要があります。
- PyTorchのインストール
公式の要件に従って、CUDA 11.8に適応したバージョンのPyTorchをインストールします。pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118 - その他のコアの依存関係をインストールする
このプロジェクトは、高性能推論のためにvLLMライブラリに依存しており、また、以下のライブラリのインストールが必要である。requirements.txtファイルに記載されているその他のパッケージ。# 进入项目文件夹 cd DeepSeek-OCR # 安装vLLM(注意:官方提供了编译好的whl文件链接,也可以自行编译) # 示例是下载官方提供的whl文件进行安装 pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl # 安装requirements.txt中的所有依赖 pip install -r requirements.txt - フラッシュ・アテンションをインストールする。
最適な速度を得るには、Flash Attentionライブラリをインストールすることをお勧めします。pip install flash-attn==2.7.3 --no-build-isolation注目してほしい: GPUがサポートされていない場合やインストールに失敗した場合は、このライブラリをアンインストールしたままにしておくこともできます。コードの後半で
_attn_implementation='flash_attention_2'このパラメータでは、モデルは実行されるが、動作は遅くなる。
ステップ3:推論コードの実行
DeepSeek-OCR は、以下の 2 つの主流の推論アプローチを提供します。Transformersライブラリーの一発推論とvLLM高性能バッチ推論の
アプローチ1:変換器を用いた高速推論(単一画像のテストに適している)
このアプローチはコードが簡単で、モデル効果を素早くテストするのに理想的である。
- Pythonファイルを作成する。
test_ocr.py。 - 以下のコードをファイルにコピーしてください。このコードはモデルを読み込み、指定された画像に対してOCR認識を実行します。
import torch from transformers import AutoModel, AutoTokenizer import os # 指定使用的GPU,'0'代表第一张卡 os.environ["CUDA_VISIBLE_DEVICES"] = '0' # 模型名称 model_name = 'deepseek-ai/DeepSeek-OCR' # 加载分词器和模型 tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) # 加载模型,使用flash_attention_2加速,并设置为半精度(bfloat16)以节省显存 model = AutoModel.from_pretrained( model_name, trust_remote_code=True, _attn_implementation='flash_attention_2', use_safetensors=True ).eval().cuda().to(torch.bfloat16) # 定义输入的图片路径和输出路径 image_file = 'your_image.jpg' # <-- 将这里替换成你的图片路径 output_path = 'your/output/dir' # <-- 将这里替换成你的输出文件夹路径 # 定义提示词,引导模型执行特定任务 # 这个提示词告诉模型将文档转换为Markdown格式 prompt = "<image>\n<|grounding|>Convert the document to markdown. " # 执行推理 res = model.infer( tokenizer, prompt=prompt, image_file=image_file, output_path=output_path, base_size=1024, image_size=640, crop_mode=True, save_results=True, test_compress=True ) print(res) - 実行コード
認識する画像を配置します。your_image.jpgをスクリプトと同じディレクトリにコピーして実行する:python test_ocr.pyプログラム実行の最後には、認識されたテキストがターミナルに印刷され、結果は指定した出力パスに保存される。
方法2:バッチ推論にvLLMを使う(大量の画像やPDFの処理に適している)
vLLMモードはよりパフォーマンスが高く、本番環境に適している。
- 設定ファイルの変更
入るDeepSeek-OCR-master/DeepSeek-OCR-vllmディレクトリでconfig.pyファイルの入力パスを変更する (INPUT_PATH)と出力パス(OUTPUT_PATH)などの設定を行う。 - 実行スクリプト
さまざまなタスクのスクリプトがこのディレクトリに用意されている:- ストリーミング画像データを扱う:
python run_dpsk_ocr_image.py - PDFファイルを処理します:
python run_dpsk_ocr_pdf.py - ベンチマークテストを実行する:
python run_dpsk_ocr_eval_batch.py
- ストリーミング画像データを扱う:
アプリケーションシナリオ
- 文書のデジタル化
紙の書籍、契約書、報告書などをスキャンして画像化した後、DeepSeek-OCRを使用すると、元のキャプション、リスト、表の構造を保持したまま、編集可能で検索可能な電子テキストにすばやく変換できます。 - 情報の抽出
請求書、領収書、帳票などの画像から、金額、日付、プロジェクト名などの主要情報を自動的に抽出し、データ入力の自動化と手作業の削減を実現します。 - 教育・研究
研究者はこのツールを使って、論文、古書、古文書、その他の文書資料に含まれるテキストコンテンツを素早く識別・変換し、その後のデータ分析やコンテンツ検索に役立てることができる。 - アクセシビリティ・アプリケーション
画像内のテキストを認識し、詳細な説明を生成することで、視覚障害者がメニューや道路標識、製品の説明書きを読むなど、画像の内容を理解するのに役立つ。
QA
- DeepSeek-OCRは無料ですか?
DeepSeek-OCRは、MITライセンスに従ったオープンソースプロジェクトであり、ユーザは自由に使用、変更、配布できます。 - 対応言語は?
このモデルは主に英語と中国語の文書処理でその威力を発揮する。大規模な言語モデルをベースにしているため、理論的には多言語処理の可能性を持っているが、正確な効果は実際のテストに基づいて評価する必要がある。 - PDFファイルの処理原理は?
DeepSeek-OCR 自体は画像を扱います。PDFファイルが入力されると、プログラムはまずPDFの各ページを画像にレンダリング(変換)し、次にこれらの画像をページごとにOCRし、最後にすべてのページの結果を単一の出力にマージします。 - NVIDIA GPUがなくても使えますか?
公式ドキュメントとチュートリアルは、NVIDIA GPUとCUDA環境に基づいています。 このモデルは理論的にはCPUでも動作しますが、動作が非常に遅くなり、実用的なアプリケーションには適しません。したがって、NVIDIA GPUを搭載したデバイスで使用することを強くお勧めします。 - コンテクスチュアル光圧縮」の利点とは?
主な利点は効率性である。従来のモデルが長いテキストを処理する場合、計算量とメモリフットプリントはテキストの長さに応じて劇的に増加します。テキスト画像を少数の視覚的トークンに圧縮することで、DeepSeek-OCRはより少ないリソースで同じ、またはさらに長いコンテンツを処理することができ、限られたハードウェアで大規模なドキュメントを処理することが可能になります。































