

テック業界で最もディストピア的な脚本が展開されている。自動ボットをブロックすることからスタートした数百億ドル規模のセキュリティの巨人が、現在世界で最もシンプルで、おそらく最も強力な自動クローラーツールを構築することになったのだ。
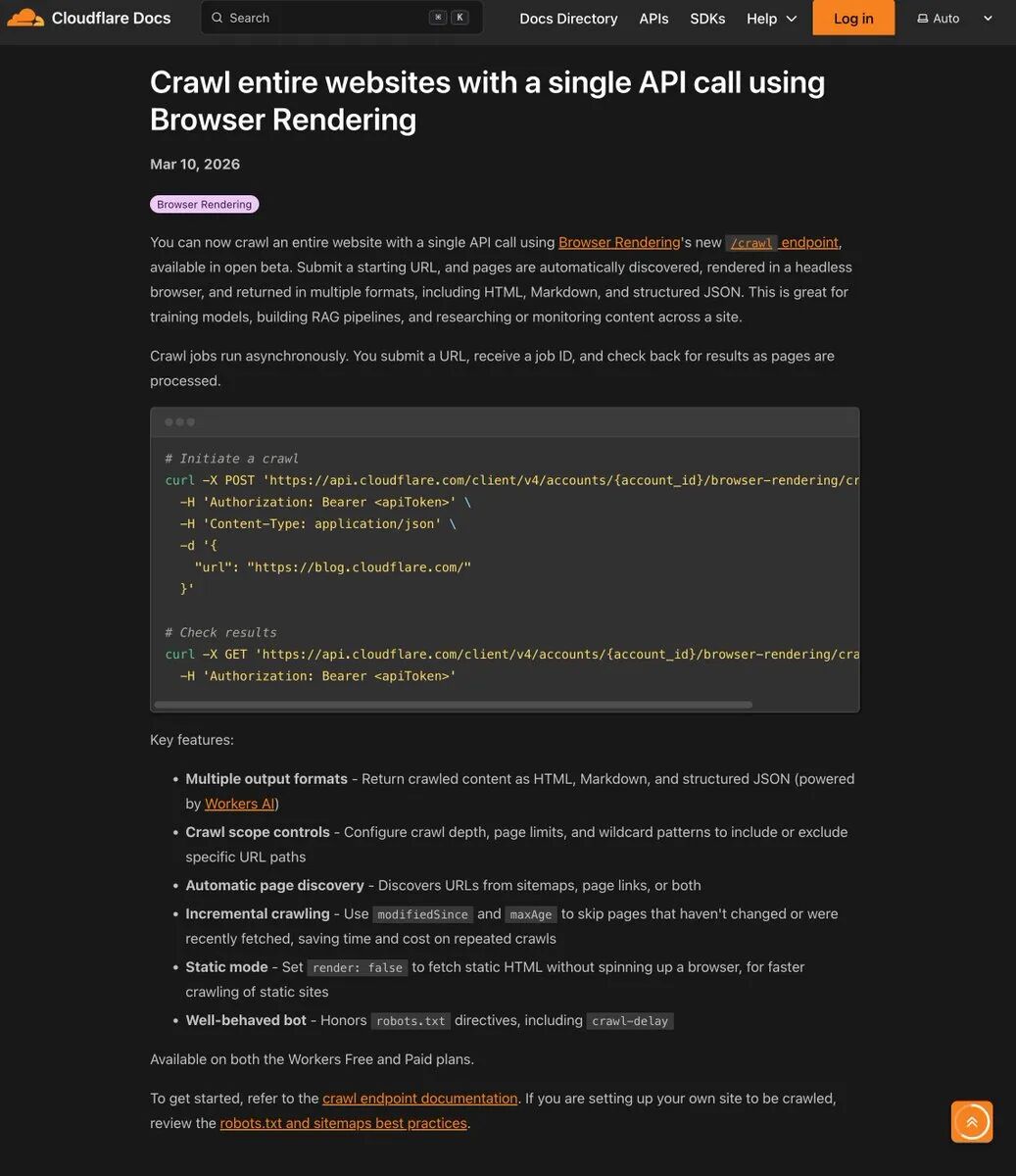
2026年3月、CloudflareはBrowser Renderingの新しいベータ機能を公開しました:/crawl API。
複雑なフレームワークを設定したり、CAPTCHAに対処したり、メモリリークのあるサーバー上でPuppeteerやPlaywrightのヘッドレス・ブラウザー・クラスターを維持したりする必要はない。必要なのは、開始URLを指定してHTTP POSTリクエストを送ることだけで、残りのページ発見、JavaScriptのレンダリング、ページングなどは同社のグローバル・エッジ・ネットワークが行う。一日の終わりには、素直にきれいなHTML、Markdown、または構造化JSONを吐き出してくれる。

皮肉なことに、数え切れないほどの開発者が過去数年間、クローラーから防御するためにCloudflareのサービスにお金を払ってきた。今、同じ人々がドキュメントを見て、CloudflareのAPIを使って他人のウェブサイトをクロールする方法を学んでいる。
隠された野望:9つの終着点を持つレンダリング帝国
というのも、すべての人々の視線がこの試合に注がれていたからだ。 /crawl ショックというと、その背後にあるインフラを見落とす人が多い。/crawl 孤立したハックおもちゃではなく、Cloudflare Browser RenderingのREST APIマトリックス全体のパズルの最後のピースです。
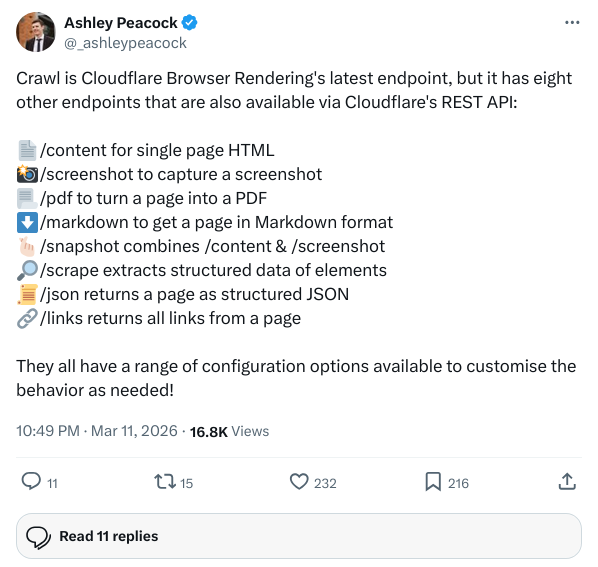
現在のエンドポイントの全リストをよく見てみると、ブラウザができることを実際には完全に解体してしまっていることがわかるだろう:
| ふりだし | 機能説明 |
|---|---|
/content |
完全にレンダリングされたHTMLの単一ページを取得する |
/screenshot |
ウェブページのビジュアルスクリーンショット |
/pdf |
ページからPDFへ |
/markdown |
AIのためのマークダウン抽出 |
/snapshot |
コンテンツとビジュアルのハイブリッド・スナップショットを含む |
/scrape |
DOMノードに基づく構造化クローリング |
/json |
抽出した構造化データをWorkers AIと組み合わせて直接出力 |
/links |
トポ・クロール・エッセンシャル 全ページリンク抽出 |
/crawl |
サイト全体の自動クロール(新規追加) |
これまでは、古いScrapyを使ってハードコアな静的ページを作成するか、重いNode.jsサービスを構築して実際のブラウザを実行する必要がありました。Cloudflareはこのプロセスを最小限の2つのステップに変えます:
- タスクを開始する開始URLを
/crawl非同期実行のジョブIDはすぐに利用できる。 - 投票ジョブIDを取得し、進捗状況を確認します。ジョブは最長7日間データセンターで実行でき、結果は14日間保持されます。
システムに組み込まれたパラメーターにより、極めて高度なコントロールが可能です。あなたは limit クロールの上限を100,000ページに設定するには depth リンクの深さを制限するか includePatterns などのワイルドカードは、特定のパスの下にあるコンテンツだけを取得する。さらに致命的なのは render パラメータ。純粋に静的なドキュメントステーションだけをクロールする必要がある場合は render として設定した。 falseシングル・ページ・アプリケーション(SPA)であれば、ブラウザのレンダリングをスキップして直接高速コンカレント・キャプチャを実行します。 render JavaScriptを実行した後、コンテンツを抽出することができます。
しきい値ゼロのドロップストライク
このインフラレベルの下降打撃は、直ちに既存のビジネス・エコシステムに引力を及ぼす。
RAG(Retrieval Augmented Generation)アプリケーションの開発者は、受益者の最初の波である。大きなモデルはクリーンなテキストを必要とし、HTMLタグはノイズとなる。かつて開発者は、あらゆる種類の通常の抽出スクリプトやクリーニング・スクリプトを書かなければならなかったが、今では1回のリクエストでMarkdownがすぐに戻ってくる。iデータ・エンジニア、インディーズ開発者、そして小さなスタートアップ・チームでさえ、クローラー・パイプラインを維持するために専任の担当者を雇う必要がなくなった。
しかし、クローラーSaaSを専門とする企業にとっては、これは火中の栗を拾うようなものだ。例えば、Firecrawlは、クローラーを利用可能なAPIにカプセル化することを中核としたビジネスモデルを持っている:
| 次元 | Cloudflare /crawl | Firecrawl |
|---|---|---|
| 根源的志向 | インフラレベルのAPI | 垂直シナリオのためのSaaS |
| 課金モデル | ブラウザベースの課金 | クロールされたページ数による課金 |
| ノードネットワーク | エッジノードの大規模なグローバルプール | 比較的制限されたサーバー輸出 |
| ユーザビリティ | Workers の Cloudflare アカウントが必要です。 | 簡単な登録と使用 |
| 構造化抽出 | ネイティブ・インテグレーション ワーカーズ AI /json ふりだし |
内蔵の大型モデル抽出機能により、すぐに使用できる。 |
Firecrawlは、製品のパッケージングと技術的背景を持たないユーザーへの親しみやすさでは依然としてリードしている。しかし、Cloudflareには、コンピュートコストとノードサイズという越えられない堀がある。
ベータテスト中は、JavaScriptレンダリング(render: false)、インターフェイスは完全に無料です。レンダリングをオンにしても、無料版では1日あたり10分間のブラウザ利用が可能。有料版(月額わずか5ドルから)では、1ヶ月あたり10時間の利用が可能で、それ以上の利用は1時間あたりわずか0.09ドルの課金となる。時間単位の課金は、リクエストごとの課金という従来のロジックを完全に覆すものであり、クロールのニーズが多い場合、そのコストはほとんど無視できるものです。
りょうぶ
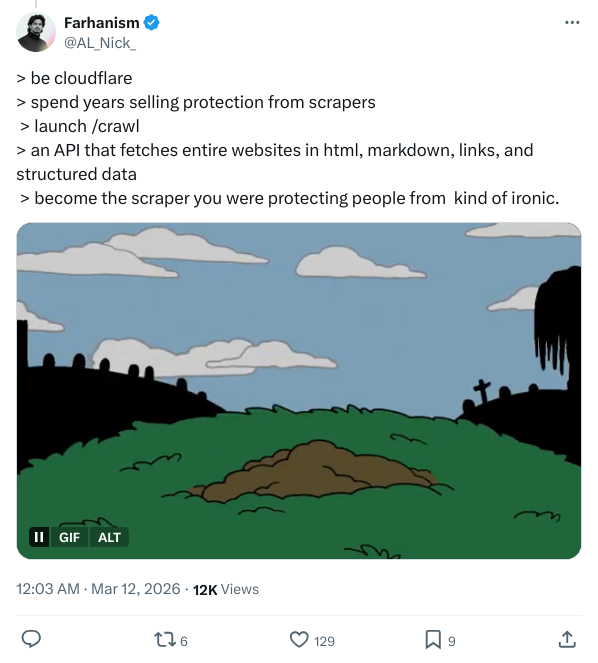
元の皮肉に戻ろう。ソーシャルネットワーク上の熱狂は、理由がないわけではなかった。x ユーザー@AL_Nick_のツイートは、ピンポイントで会社の論理を突いていた:
be cloudflare
spend years selling protection from scrapers
launch /crawl
become the scraper you were protecting people from
添えられた画像は、バットマンの古典的なセリフである「ヒーローとして名誉の引退をするか、悪役になるのを見届けるために生きるか」。“
ネット上のあらゆる非難に直面し、Cloudflareの関係者はコメント欄で非常に巧妙な弁明を行った。彼らは、今日インターネット上に氾濫している暴力的なクローラーの根本的な原因は、「丁寧なクローラーを作るための開発コストが高すぎる」ことだと考えている。そこで彼らは、デフォルトでrobots.txtを遵守し、ターゲットサーバーを圧倒しないように同時実行の頻度を制御し、canonical User-Agentを使用する公式APIを提供している。
それは論理的な主張ではあるが、ビジネス的な精通を隠すものではない。Cloudflareの高度なWAFに対価を支払っている企業は、Cloudflare自身による次のような送信を阻止できる防御を持っているのだ。 /crawl リクエストは?
中国コミュニティの開発者、@chuhaiquは、「昔は、クローラーをブロックするためにお金を請求した。今は、他人をクロールするのを助けるためにお金をもらう。“
これこそがプラットフォーム型企業の究極の特権なのだ。クローリング機能をコモディティ化することで、Cloudflareは開発者のWorkersコンピューティング・エコシステムへの依存をさらに深めている。クラウドフレアは、あなたが他人をクロールしようが、他人があなたをクロールするのを防ごうが、気にしない。データが流れ、トラフィックが同社のエッジノードを通過している限り、メーターは言葉を歩いている。
ハンズオン:5分でデータポンプを導入する
ビジネス倫理はさておき、開発者の観点からすると、このツールは本当に素晴らしすぎる。必要なのは、Workersを有効にしたCloudflareアカウントと、ブラウザ・レンダリング権限を持つAPIトークンだけだ。
30行以下のコードで、完全なサイトレベルのデータ・クロール・タスクを実行できる:
async function crawlSite(url, apiToken, accountId) {
// 1. 发起 POST 请求,创建爬取任务
const startRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl`,
{
method: 'POST',
headers: {
'Authorization': `Bearer ${apiToken}`,
'Content-Type': 'application/json'
},
// 请求输出 Markdown,对于静态内容关闭渲染以加速
body: JSON.stringify({ url, formats:['markdown'], render: false })
}
);
const { result: jobId } = await startRes.json();
// 2. 轮询 GET 请求,等待庞大的任务集群完成作业
while (true) {
const checkRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}?limit=1`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
const data = await checkRes.json();
if (data.result.status !== 'running') break;
// 礼貌的等待时间
await new Promise(r => setTimeout(r, 3000));
}
// 3. 任务结束,提取洗净后的数据
const finalRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
return (await finalRes.json()).result.records;
}
また、この発表に同行した。 MCP つまり Cursor または Claude このようなAI IDEは、自然言語を通じてシステムを直接呼び出す。必要なデータは、AIが自動的にこの最小限のAPIを呼び出して取得する。
旧来の障壁は崩れ去り、データアクセスの限界コストは限りなくゼロに近づいている。これは、インターネット上のオープンコンテンツを擁護する人々にとって、絶対に悪いニュースだ。





































