



Whisper_Cloudflare ist ein Open-Source-Projekt des Entwicklers thun888, das auf GitHub gehostet wird. Es basiert auf OpenAIs Whisper Modell, kombiniert mit der serverlosen Architektur von Cloudflare Workers, bietet eine effiziente Sprache-zu-Text-Funktionalität. Die Benutzer können dies durch die Bereitstellung einer einzigen worker.js Das Projekt unterstützt mehrere Sprachen und Audioformate und ist für Entwickler einfach zu verwenden, um schnell Sprachverarbeitungsanwendungen zu erstellen. Das Projekt unterstützt mehrere Sprachen und Audioformate und ist für Entwickler einfach zu verwenden, um schnell Sprachverarbeitungsanwendungen zu erstellen. Das Projekt ist völlig kostenlos, der Code ist öffentlich zugänglich und es ist nicht notwendig, einen Server für die Bereitstellung zu verwalten, so dass es für Einzelpersonen oder Teams geeignet ist, die sich mit der Audiotranskription und der Erzeugung von Untertiteln beschäftigen müssen.
Funktionsliste
- Sprache zu Text: Konvertierung von Audiodateien in Text, Unterstützung von mehrsprachiger Erkennung.
- Untertitelgenerierung: Generieren Sie Untertiteldateien mit Zeitstempel im SRT-Format.
- Unterstützung mehrerer Audioformate: kompatibel mit MP3, WAV und anderen gängigen Audioformaten.
- Serverless Deployment: Schnelle Bereitstellung mit Cloudflare Workers, für die nur
worker.jsDokumentation. - API-Schnittstelle: Bietet
/raw(Transkriptionsrohdaten) und/srt(Untertiteldatei) zwei Schnittstellen. - Voice Activity Detection (VAD): Unterstützung
vad_filterum Nicht-Sprachteile zu filtern. - Optimierung des Kontextes: durch
initial_prompt和prefixParameter zur Verbesserung der Transkriptionsgenauigkeit. - Übersetzungsfunktion: Unterstützung bei der Übersetzung von Audioinhalten in eine bestimmte Sprache (z. B. Englisch, Chinesisch usw.).
Hilfe verwenden
Prozess der Bereitstellung
Die Bereitstellung des Whisper_Cloudflare-Projekts erfordert lediglich, dass die bereitgestellten worker.js Der Code wird auf die Cloudflare Workers-Plattform kopiert, ohne Ihr gesamtes GitHub-Repository zu klonen. Hier sind die detaillierten Schritte:
- Registrieren Sie sich für ein Cloudflare-Konto
Besuchen Sie die Cloudflare-Website, um sich zu registrieren oder ein Konto einzurichten. Vergewissern Sie sich, dass die Workers-Funktion aktiviert ist (der kostenlose Plan ist in Ordnung). Gehen Sie im Cloudflare-Dashboard auf die Seite "Workers" und klicken Sie auf "Create Worker". - Erstellen Sie einen Worker und fügen Sie den Code ein
- Erstellen Sie im Workers-Editor einen neuen Worker (standardmäßig mit dem Namen
worker(oder einen benutzerdefinierten Namen). - Angebot
worker.jsDer Code wird kopiert und in den Editor eingefügt, wobei der Standardcode überschrieben wird. - Speichern Sie den Code.
- Erstellen Sie im Workers-Editor einen neuen Worker (standardmäßig mit dem Namen
- Installieren Sie Wrangler (optional, für den Einsatz auf der Befehlszeile)
Wenn Sie Ihre Worker über die Kommandozeile verwalten möchten, müssen Sie Wrangler (das Kommandozeilentool für Cloudflare Worker) installieren. Stellen Sie sicher, dass Sie Node.js installiert haben (empfohlene Version 16.17.0 oder höher) und führen Sie es aus:npm install -g wrangler - Konfigurieren von Wrangler und AI-Bindungen
- Führen Sie den folgenden Befehl aus, um sich bei Cloudflare anzumelden:
wrangler login - Erstellen oder bearbeiten
wrangler.tomlfügen Sie die folgende Konfiguration hinzu:name = "whisper-cloudflare" compatibility_flags = ["nodejs_compat"] [ai] binding = "AI" - Wenn Sie Wrangler nicht verwenden, können Sie das KI-Modell manuell in den Worker-Einstellungen des Cloudflare-Dashboards binden (wählen Sie die Option
@cf/openai/whisper-large-v3-turbo)。
- Führen Sie den folgenden Befehl aus, um sich bei Cloudflare anzumelden:
- Entsendung von Arbeitnehmern
- Klicken Sie im Workers-Editor auf die Schaltfläche "Bereitstellen", um den Code direkt zu veröffentlichen.
- oder über Wrangler laufen:
wrangler deploy - Nach erfolgreichem Einsatz stellt Cloudflare eine Worker-URL zur Verfügung (z.B. https://whispercloudflare.tchepai.com/).
- Vorbereiten von Audiodateien
Stellen Sie sicher, dass die Audiodatei im MP3- oder WAV-Format vorliegt und die Dateigröße 25 MB nicht überschreitet (vorbehaltlich der Cloudflare Workers-Limits). Audiodateien müssen in binärer Form hochgeladen werden oder über eine öffentliche URL zugänglich sein (z. B. auf einen Cloud-Speicher hochgeladen).
Hauptfunktionen
Sprache-zu-Text
Whisper_Cloudflare verwendet das Whisper-Modell zur Umwandlung von Audio in Text. Die Schritte sind wie folgt:
- Audio hochladen: sendet Audio-Binärdaten per POST-Anfrage an die
/rawSchnittstellen. Beispiel:curl -X POST "https://whisper.ohen5pbf93.workers.dev/raw" \ -H "Content-Type: application/octet-stream" \ --data-binary "@audio.mp3" - Ergebnisse erzielenRückgabe des Transkriptionsergebnisses im JSON-Format, das Text und einen Zeitstempel enthält:
{ "response": { "text": "这是一个测试音频。", "segments": [ {"text": "这是一个", "start": 0.0, "end": 1.2}, {"text": "测试音频", "start": 1.3, "end": 2.5} ] } } - Umgang mit großen DateienWenn die Audiodatei größer als 25 MB ist, müssen Sie sie manuell in kleinere Stücke aufteilen (1 MB pro Stück wird empfohlen), die Stücke einzeln hochladen und die Ergebnisse zusammenführen.
Untertitel Generation
Generieren Sie Untertiteldateien im SRT-Format für Videos oder Podcasts. Verfahren:
- Untertitel anfordern: Audio senden an
/srtSchnittstelle:curl -X POST "https://whispercloudflare.tchepai.com/srt" \ -H "Content-Type: application/octet-stream" \ --data-binary "@audio.mp3" - Ergebnisse erzielenRückgabe einer Datei im SRT-Format, zum Beispiel:
1 00:00:00,000 --> 00:00:01,200 这是一个 2 00:00:01,300 --> 00:00:02,500 测试音频
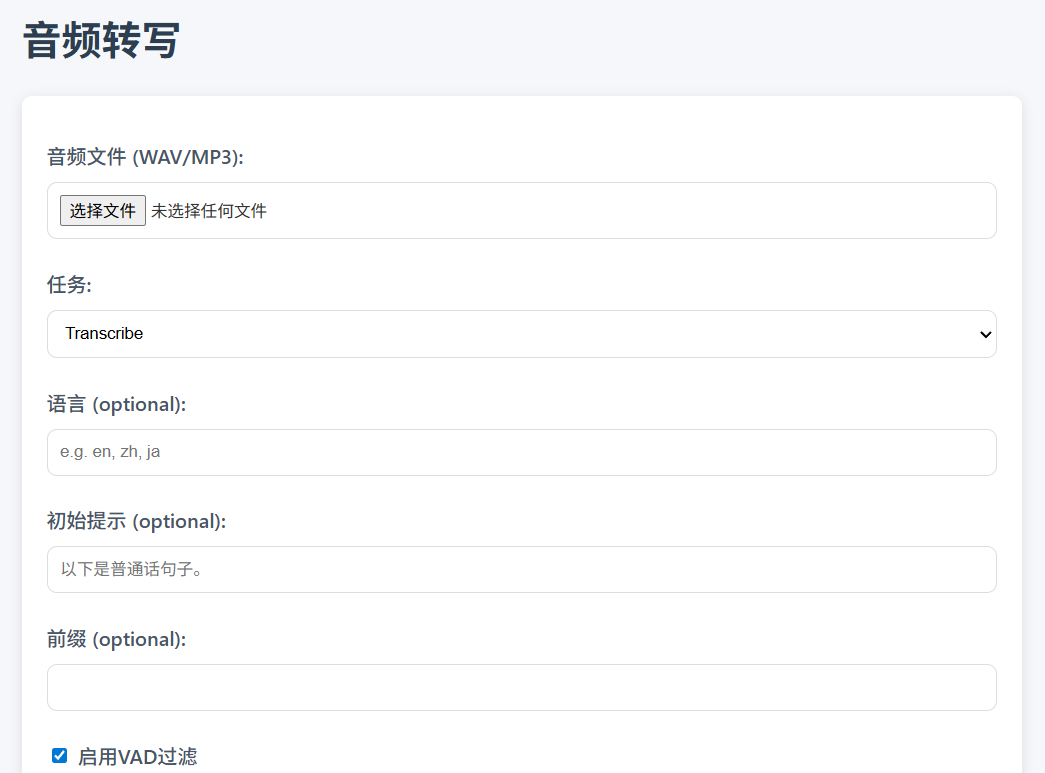
Nutzung der Webschnittstelle
worker.js Bietet eine integrierte HTML-Schnittstelle (Root-Pfad zur Worker-URL) /), die vom Nutzer über den Browser bedient werden können:
- ZugangsschnittstelleÖffnen Sie die URL des Workers (z. B. https://whispercloudflare.tchepai.com/).
- Audio hochladenWählen Sie eine MP3- oder WAV-Datei aus, stellen Sie Parameter wie Aufgabentyp (Transkription oder Übersetzung), Sprache, VAD-Filterung usw. ein.
- Ergebnisse erzielenNach der Übermittlung zeigt die Schnittstelle den SRT-Untertitel an und unterstützt das Herunterladen des Untertitels als
.srtDokumentation. - zur Kenntnis nehmenDie Schnittstelle unterstützt einen Fortschrittsbalken und benötigt etwa 1,9 Minuten für die Verarbeitung von 41 Minuten Audio.
API-Verwendung
Das Projekt bietet zwei API-Schnittstellen:
/rawRückgabe von Transkriptions-Rohdaten im JSON-Format, geeignet für die Weiterverarbeitung durch Entwickler./srtUntertitel: Liefert Untertiteldateien im SRT-Format zur direkten Verwendung in der Videobearbeitung.
Beispiel für einen JavaScript-Aufruf:
const response = await fetch('https://whispercloudflare.tchepai.com/srt', {
method: 'POST',
headers: { 'Content-Type': 'application/octet-stream' },
body: audioFile // 音频二进制数据
});
const srt = await response.text();
console.log(srt); // 输出 SRT 字幕
Optimierung des Kontextes
ausnutzen initial_prompt 或 prefix Parameter liefern Kontext, um die Transkriptionsgenauigkeit zu verbessern. Beispiel:
curl -X POST "https://whispercloudflare.tchepai.com/raw?initial_prompt=技术会议" \
-H "Content-Type: application/octet-stream" \
--data-binary "@audio.mp3"
Erkennung von Sprachaktivität (VAD)
Aktivieren Sie die VAD-Filterung (vad_filter=true) kann nichtsprachliche Teile entfernen:
curl -X POST "https://whispercloudflare.tchepai.com/raw?vad_filter=true" \
-H "Content-Type: application/octet-stream" \
--data-binary "@audio.mp3"
Übersetzungsfunktion
aufstellen task=translate 和 language um das Audio in die angegebene Sprache zu übersetzen. Beispiel:
curl -X POST "https://whispercloudflare.tchepai.com/raw?task=translate&language=en" \
-H "Content-Type: application/octet-stream" \
--data-binary "@audio.mp3"
Leistung und Beschränkungen
- TempoTests zeigen, dass es nur 1,9 Minuten dauert, 41 Minuten und 39 Sekunden Audio zu verarbeiten.
- EinschränkungRessourcenbeschränkungen von Cloudflare Workers können gelegentlich zu Fehlern führen, ein erneuter Versuch wird empfohlen.
- DateigrößeNicht mehr als 25 MB an Audiodaten in einer einzigen Anfrage.
caveat
- API-SicherheitKonfigurieren Sie AI-Bindungen im Cloudflare-Dashboard und geben Sie keine API-Tokens heraus.
- FehlerbehandlungWenn die Anfrage fehlschlägt, warten Sie ein paar Sekunden und versuchen Sie es erneut.
- Browser-KompatibilitätDie Weboberfläche funktioniert gut auf modernen Browsern (z.B. Chrome, Firefox).
Anwendungsszenario
- Abschrift von Sitzungsunterlagen
Laden Sie Audiodaten hoch und erstellen Sie Text- oder SRT-Untertitel für die mehrsprachige Organisation von Besprechungen. - Erzeugung von Podcast-Untertiteln
Podcast-Produzenten erstellen SRT-Untertitel, um die Zugänglichkeit der Inhalte und die Suchoptimierung zu verbessern. - Transkription von Bildungsressourcen
Lehrer oder Schüler laden Unterrichtsaufzeichnungen hoch, um Notizen oder Untertitel für eine einfache Wiederholung zu erstellen. - Entwicklung von Sprachanwendungen
Entwickler integrieren APIs zur Erstellung von Echtzeituntertiteln oder Sprachassistenten für leichtgewichtige Projekte.
QA
- Welche Audioformate werden unterstützt?
MP3, WAV und andere Formate werden unterstützt, wobei eine hohe Audioqualität empfohlen wird. - Wie gehen Sie mit großen Dateien um?
Manuelle Aufteilung in 1-MB-Chunks, Hochladen und Zusammenführen der Ergebnisse Chunk für Chunk. - Muss ich für die Bereitstellung bezahlen?
Der kostenlose Plan von Cloudflare Workers unterstützt Implementierungen mit 10.000 kostenlosen Neuronen pro Tag für KI-Modelle, darüber hinaus werden $0,011 pro 1000 Neuronen berechnet. - Wie lässt sich die Transkription optimieren?
ausnutzeninitial_prompt、prefix或vad_filterDie Parameter verbessern die Genauigkeit. - Welche Sprachen werden unterstützt?
Englisch, Chinesisch, Japanisch und andere Sprachen werden unterstützt. Den genauen Code finden Sie in der Whisper-Dokumentation.






























