



Web Crawler ist ein Open-Source-Web-Crawler-Tool, das als Befehlszeilenschnittstelle (CLI) ausgeführt wird und den Benutzern einen übersichtlichen Echtzeitkanal für die Suche nach Informationen im Internet bietet. Das Tool wurde speziell entwickelt, um das Web auf der Grundlage der vom Benutzer eingegebenen Suchbegriffe zu durchsuchen und die Ergebnisse im JSON-Format (mit Titel, URL und Veröffentlichungsdatum) direkt im Terminal in der Reihenfolge der Veröffentlichungszeit vom nächsten bis zum entferntesten auszugeben. Dieses Projekt ist Teil der "financial-datasets"-Organisation, die sich der Bereitstellung von benutzerfreundlichen Finanzdaten-APIs und Tools für Large Language Models (LLMs) und Agenten der Künstlichen Intelligenz (KI-Agenten) widmet. Dieser Web-Crawler, ein Mitglied ihrer Tool-Suite, wurde entwickelt, um schnell und effizient die neuesten Informationen aus dem Internet zu crawlen, um Rohdaten für die anschließende Datenanalyse und KI-Anwendungen bereitzustellen.
Funktionsliste
- Websuche in EchtzeitSuchbegriff: Empfängt jeden vom Benutzer über die Befehlszeilenschnittstelle eingegebenen Suchbegriff und führt die Suche sofort aus.
- Ausgabe im JSON-FormatDie Suchergebnisse werden in einem strukturierten JSON-Format zurückgegeben und enthalten jeweils die
title(Titel),url(Website) undpublished_date(Veröffentlichungsdatum) drei Felder. - Nach Pünktlichkeit sortierenDie zurückgegebenen Suchergebnisse sind streng nach dem Datum der Veröffentlichung sortiert, um sicherzustellen, dass die Nutzer die aktuellsten Informationen zuerst sehen.
- Interaktive AbfragenDas Tool unterstützt die kontinuierliche Suche. Nach Abschluss einer Suche kann der Benutzer sofort neue Schlüsselwörter für die nächste Suche eingeben, ohne das Programm neu zu starten.
- Plattformübergreifende KompatibilitätBasierend auf Python-Entwicklung, kann es in jeder Umgebung laufen, die Python 3.12+ unterstützt.
- Einfache Ausstiegsmechanismen: Der Benutzer kann einen Namen eingeben, indem er
q、quit、exitoder verwenden Sie das TastenkürzelCtrl+Cum das Programm einfach zu verlassen.
Hilfe verwenden
Das Tool ist ein leichtgewichtiges Befehlszeilenprogramm, das keine komplexe Installation oder Konfiguration erfordert, um schnell starten zu können. Nachfolgend finden Sie eine detaillierte Beschreibung der Installation und Verwendung.
Vorbereitung der Umwelt
Bevor Sie beginnen, vergewissern Sie sich, dass Sie die folgenden beiden wichtigen Softwareprogramme auf Ihrem Computer installiert haben:
- PythonDie Versionsanforderungen sind
3.12Oder höher. - uvEin schnelles Werkzeug zur Installation und Verwaltung von Python-Paketen.
Installationsschritte
- Code-Repository klonen
Öffnen Sie Ihr Terminal (Befehlszeilentool) und verwenden Sie den BefehlgitBefehl klont den Quellcode des Projekts von GitHub auf Ihren lokalen Computer.git clone https://github.com/financial-datasets/web-crawler.git - Wechseln Sie in das Projektverzeichnis
Nachdem das Klonen abgeschlossen ist, verwenden Sie diecdin den soeben erstellten Projektordner.cd web-crawler
laufendes Programm
Wenn Sie sich im Stammverzeichnis des Projekts befinden (web-crawlerOrdner), können Sie direkt den folgenden Befehl ausführen, um dieses Webcrawler-Tool zu starten:
uv run web-crawler
uv run übernimmt automatisch die Installation der Abhängigkeiten und die Konfiguration der virtuellen Umgebung, die für das Projekt erforderlich ist, gefolgt vom Start der Hauptanwendung.
Arbeitsablauf
- Eingabe einer Abfrage
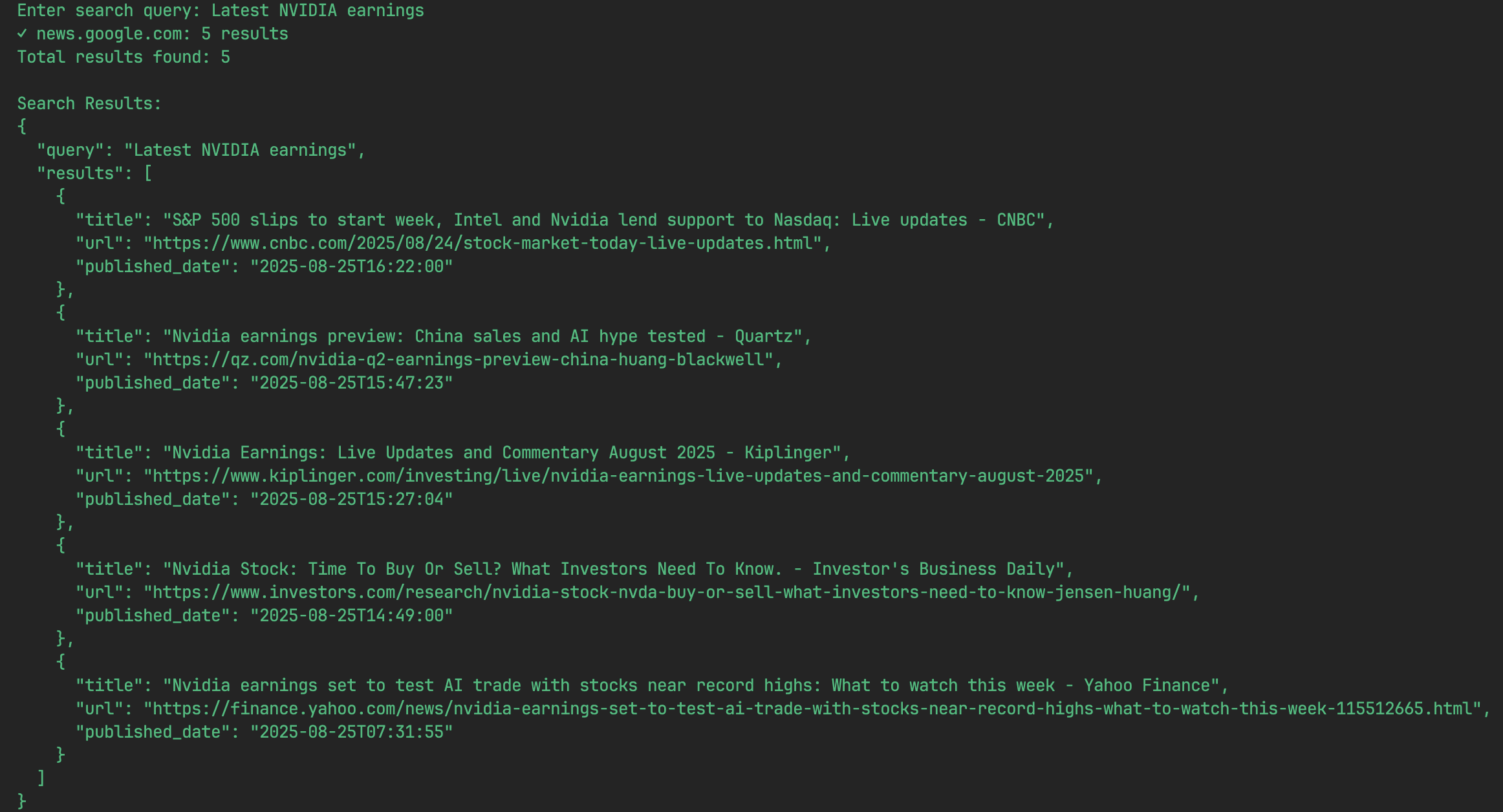
Sobald das Programm gestartet ist, fordert das Terminal Sie auf, einzugeben, wonach Sie suchen möchten. Sie können ein beliebiges Stichwort eingeben, um zum Beispiel das Protokoll der letzten Apple-Konferenz zu finden:Enter your search (e.g., "AAPL latest earnings transcript"):Geben Sie hier Ihre Anfrage ein und drücken Sie die Eingabetaste.
- Ergebnisse anzeigen
Das Programm startet die Suche sofort und gibt die Ergebnisse innerhalb weniger Sekunden in Form einer Liste von JSON-Objekten auf dem Bildschirm aus. Jedes JSON-Objekt stellt ein Suchergebnis dar und enthält den Titel, die URL und das Datum der Veröffentlichung.Die Ergebnisse einer Suche könnten zum Beispiel wie folgt aussehen:
[ { "title": "Apple Inc. (AAPL) Q3 2025 Earnings Call Transcript", "url": "https://example.com/aapl-q3-2025-transcript", "published_date": "2025-07-30" }, { "title": "Analysis of Apple's Latest Financial Report", "url": "https://example-news.com/aapl-q3-analysis", "published_date": "2025-07-29" } ] - Fortfahren oder zurückziehen
- Suche fortsetzenAm Ende einer Suche zeigt das Programm wieder die Eingabeaufforderung an, und Sie können direkt neue Suchbegriffe für die nächste Suche eingeben.
- Opt-out-VerfahrenWenn Sie die Nutzung beenden wollen, können Sie nach der Eingabeaufforderung eingeben
q、quit或exitund drücken Sie die Eingabetaste. Alternativ können Sie auch das Tastaturkürzel verwendenCtrl+Cum eine Unterbrechung zu erzwingen und das Programm zu beenden.
Anwendungsszenario
- Finanzanalysten und -forscher
Analysten können mit diesem Tool schnell die neuesten Ertragsberichte, Pressemitteilungen, Marktanalysen und Interviews mit Führungskräften für ein bestimmtes Unternehmen abrufen. Geben Sie beispielsweise einen Unternehmenscode und "earnings transcript" ein, um schnell einen Link zum Text der letzten Bilanzsitzung zu erhalten, der aktuelle Daten zur Unterstützung von Finanzmodellen und Investitionsentscheidungen liefert. - Dateneingabe für KI-Agenten und große Sprachmodelle
Das Tool kann als Teil eines automatisierten Arbeitsablaufs verwendet werden, um KI-Agenten mit Echtzeitdaten zu versorgen. Beispielsweise könnte ein KI-Agent, der Marktzusammenfassungen erstellt, diesen Crawler aufrufen, um Links zu den neuesten Nachrichten über eine bestimmte Branche oder ein bestimmtes Unternehmen zu finden, und dann auf diese Links zugreifen, um einen Bericht zusammenzufassen und zu erstellen. - Software-Entwickler und Datenwissenschaftler
Entwickler können diesen Crawler in ihre Anwendungen integrieren, um Webinformationen zu bestimmten Themen zu überwachen. Erstellen Sie beispielsweise ein System zur Überwachung der öffentlichen Meinung, um das neueste Nutzerfeedback und Medienberichte zu sammeln, indem Sie regelmäßig Schlüsselwörter zu einem Produkt abfragen. - Nachrichtenpraktiker und Journalisten
Journalisten können das Tool nutzen, um die neuesten Entwicklungen bei aktuellen Ereignissen zu verfolgen. Durch die Eingabe von Schlüsselwörtern zu Ereignissen können Links zu Berichten aus verschiedenen Nachrichtenquellen schnell abgerufen und nach Zeitleiste geordnet werden, so dass man auf effiziente Weise mit den Ereignissen Schritt halten kann.
QA
- Durchsucht dieses Tool das gesamte Web?
Das Tool nutzt derzeit die Such-API von DuckDuckGo für die Informationsbeschaffung, die theoretisch ein breites Spektrum von Internetinhalten abdecken könnte. Der künftige Entwicklungsplan sieht jedoch vor, weitere Datenquellen wie Bing und Reddit einzubeziehen, um den Umfang und die Vielfalt der Suche weiter auszubauen. - Warum sind die Suchergebnisse im JSON-Format?
JSON ist ein leichtgewichtiges, einfach zu lesendes und zu schreibendes Datenaustauschformat, das auch von Maschinen leicht geparst und erzeugt werden kann. Für Entwickler ist dieses Format sehr benutzerfreundlich und es ist einfach, die Ausgabe dieses Tools als Eingabe für andere Programme zu verwenden, was automatisierte Verarbeitungsprozesse erleichtert. - Kann dieses Projekt verwendet werden, um Websites zu crawlen, für die eine Anmeldung erforderlich ist oder die komplexes JavaScript laden?
Die aktuelle Version ist nur begrenzt in der Lage, mit Seiten umzugehen, die viel JavaScript benötigen, um Inhalte dynamisch zu laden (wie z. B. einige der großen Finanznachrichtenseiten). Dies ist eine der bekannten Aufgaben, und künftige Versionen sind geplant, um das Parsen von Inhalten für solche "JavaScript-lastigen" Seiten zu verbessern. - Ich bin ein Entwickler, kann ich zu diesem Projekt beitragen?
Unbedingt. Dies ist ein Open-Source-Projekt und die Hilfe und Beiträge der Gemeinschaft sind sehr willkommen. Die offizielle Roadmap nennt eine Reihe von Bereichen, in denen Hilfe benötigt wird, unter anderem: Verbesserung des Parsings von JavaScript-Seiten, Integration großer Sprachmodelle für die Zusammenfassung von Inhalten, Hinzufügen neuer Datenquellen und Verbesserung der Geschwindigkeit durch Parallelisierung von Abfragen.































