

im Zuge von wan2.1 Mit dem Aufkommen von Videomodellen wie der lokalisierten Videogenerierung reift das Technologie-Ökosystem für die lokalisierte Videogenerierung allmählich heran. In der Vergangenheit war leistungsstarke Hardware das Haupthindernis für die Erstellung von Video-Workflows, aber mit der Popularität von Cloud-Computing-Ressourcen und der Entwicklung von Modelloptimierungstechniken können nun auch Benutzer ohne Spitzenvideokarten Cloud-Computing-Ressourcen mieten. 4090 Grafikkarten und andere Möglichkeiten zum vertieften Lernen und Erforschen wan2.1 Video-Workflow.
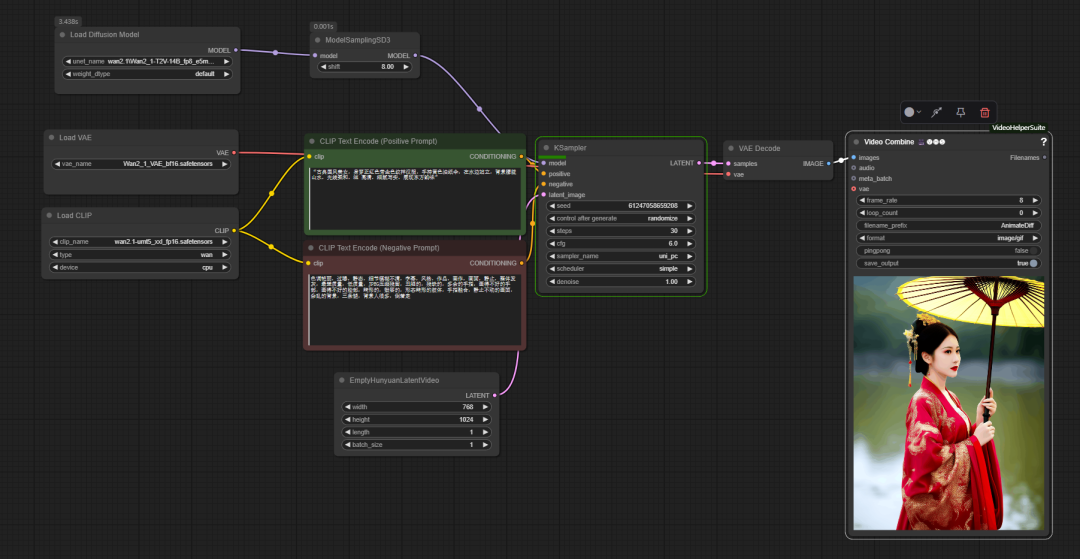
在 ComfyUI im offiziellen zugrunde liegenden Arbeitsablauf derwan2.1 wird ähnlich wie das traditionelle Vincennes-Diagramm verwendet, jedoch mit dem Zusatz eines Schlüsselknotens model sampling sd3. Dieser Knoten wird verwendet, um die UNet Dieser Parameter wirkt sich auf die Fähigkeit des Modells aus, die Stichwörter zu verstehen und zu kontrollieren und so die Detailgenauigkeit des erzeugten Bildes zu optimieren.
Zum Laufen wan2.1 Modell, das mit der entsprechenden Funktion ausgestattet sein muss unmt5 Text-Encoder und wan2.1 VAE (Variable Auto-Encoder): VAE besteht aus zwei Teilen, Encoder und Decoder. Der Encoder ist für die Komprimierung des Eingangsbildes in einen niedrigdimensionalen potenziellen Raum zuständig, während der Decoder aus dem potenziellen Raum Proben entnimmt und sie auf ein Bild reduziert.
Die Aufgabe des Textkodierers besteht darin, die eingegebenen Texthinweise in Merkmalsvektoren umzuwandeln, die vom Modell verstanden werden können. Dieser Prozess besteht aus zwei Hauptschritten:
- Extrahieren Sie semantische Informationsmerkmale des Textes, z. B. "1 Mädchen".
- Die semantischen Informationen werden in einen hochdimensionalen Einbettungsvektor umgewandelt.
Auf der Grundlage dieser Einbettungsvektoren erzeugen generative Modelle (z. B. UNet) Bildmerkmale im latenten Raum, die mit den Textbeschreibungen übereinstimmen, und bestimmen so die Art, Position, Farbe und Stellung der Objekte im Bild.
Im Gegensatz zum statischen Venn-Diagramm-Workflow ist der letzte Schritt im Videoerstellungsprozess die Video Combine (Video Compositing) Knoten.
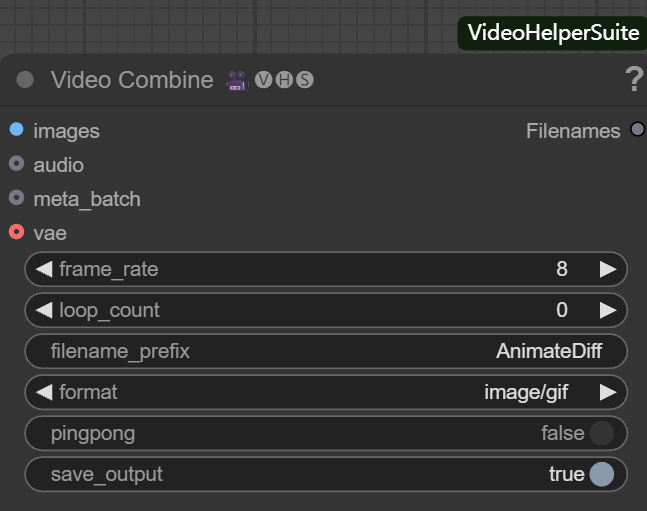
Dieser Knoten ist für die Entzerrung von Bildsequenzen in Video- oder Laufbilddateien zuständig. Zu seinen wichtigsten Parametern gehören:
- frame_rate. Bestimmt die Glätte der Videowiedergabe, z. B. auf
8Das bedeutet, dass 8 Bilder pro Sekunde wiedergegeben werden. - Schleifen_Zahl.
0Stellt eine Endlosschleife dar, anwendbar auf GIFs;1Dann heißt es einmal spielen und dann aufhören. - filename_prefix (Dateinamen-Präfix). Setzen Sie ein Präfix für die Ausgabedatei, z. B.
AnimateDiffDas Programm ist einfach zu verwalten. - Format. wählbar
image/gifein bewegtes Bild ausgibt, odervideo/mp4und andere Videoformate. - Pingpong (Hin- und Rückfahrt).
falsefür die normale sequenzielle Wiedergabe.trueDann wird eine Rundum-Wiedergabe vom Anfang zum Ende und zurück zum Anfang realisiert. - speichern_ausgeben. eingestellt auf
trueWenn der Knoten ausgeführt wird, wird die Datei automatisch nach der Ausführung des Knotens gespeichert.
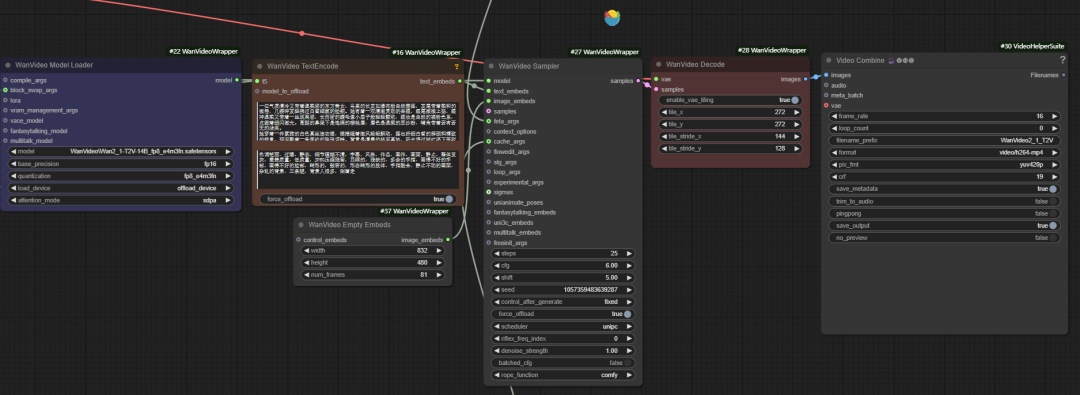
Der offizielle Workflow implementiert nur grundlegende Funktionen und hat Einschränkungen in Bezug auf Speicheroptimierung, Videoverbesserung und so weiter. Aus diesem Grund hat der Entwickler "K-God" den wanvideo wrapper Toolkit, das eine Reihe von Optimierungsknoten bietet.
Das Herzstück der Optimierung: wanvideo wrapper
wanvideo model loader
wanvideo model loader ist ein leistungsfähiger Modellladeknoten, der nicht nur die wanvideo Modell und bietet darüber hinaus eine Fülle von Optimierungsmöglichkeiten.
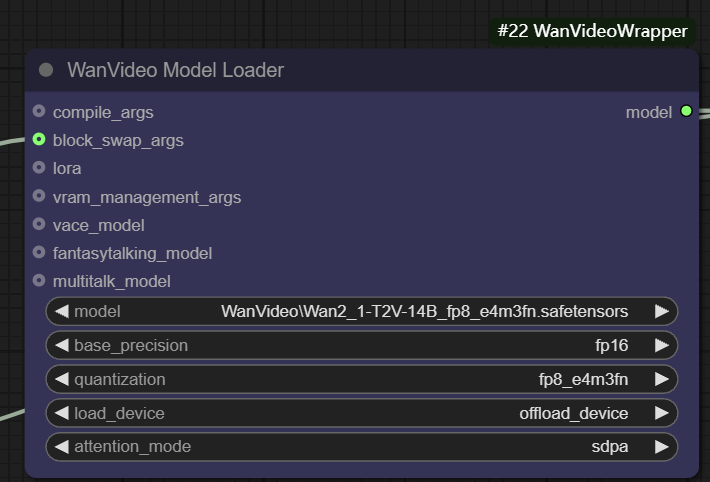
- Basispräzision. Der Benutzer kann verschiedene Modellgenauigkeiten auswählen, z. B.
fp32、bf16、fp16。fp32(32-Bit-Gleitkomma) Höchste Genauigkeit, aber größter Speicherplatzbedarf und Rechenaufwand;fp16(16-Bit-Gleitkomma) kann die Speichernutzung erheblich reduzieren und die Geschwindigkeit erhöhen, aber möglicherweise zu Lasten der Präzision gehen. - Quantifizierung. passieren (eine Rechnung oder Inspektion etc.)
quantizationkann das Modell für eine weitere Verdichtung quantifiziert werden. Zum Beispiel kann diefp8_e4m3fnDas Format verwendet eine 8-Bit-Gleitkommadarstellung, die den Speicherbedarf erheblich reduziert und sich besonders für Geräte mit begrenztem Videospeicher eignet, aber in der Regel erfordert, dass das Modell über eine vorab unterstützte Quantisierung verfügt.
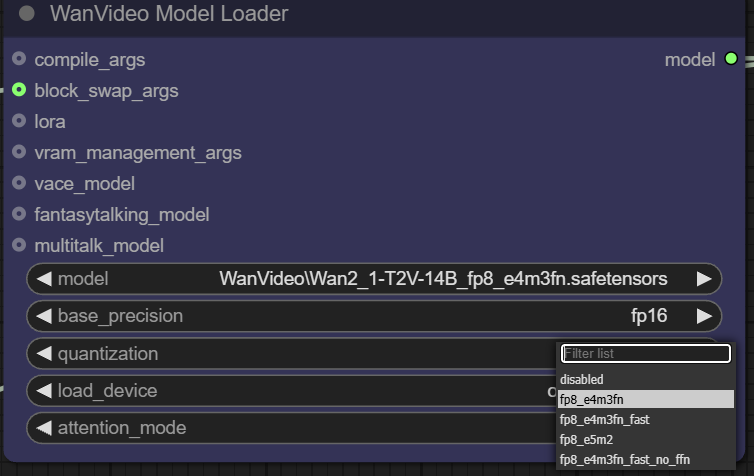
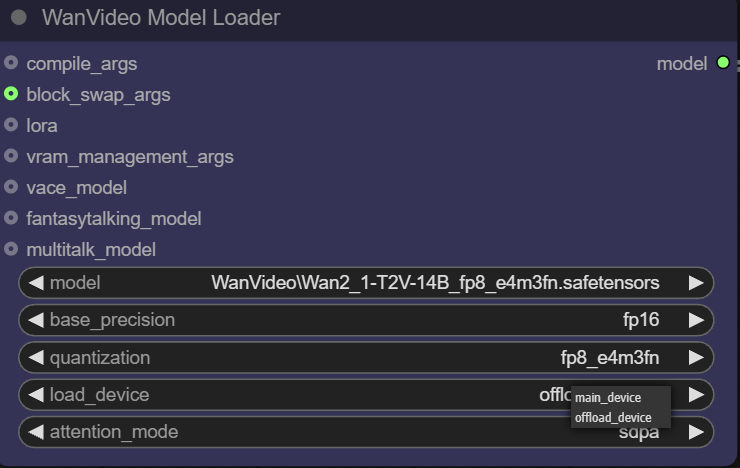
- Gerät laden.
main devicebezieht sich normalerweise auf die GPU, währendoffload deviceMit dieser Funktion können einige Komponenten des Modells an die CPU ausgelagert werden, um wertvolle Videospeicherressourcen zu sparen.
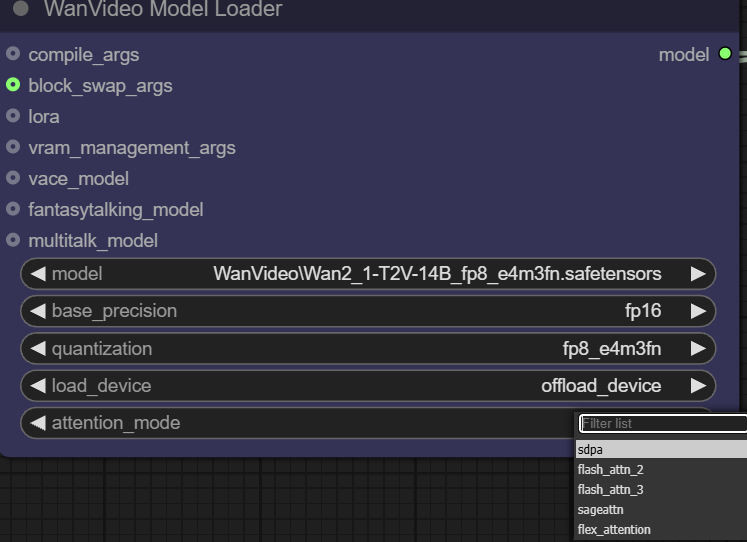
- Aufmerksamkeitsmodus. Diese Option ermöglicht es dem Benutzer, eine andere Implementierung des Aufmerksamkeitsmechanismus zu wählen, um ein Gleichgewicht zwischen Leistung und Gedächtnis herzustellen. Der Aufmerksamkeitsmechanismus ist das Herzstück des Transformer-Modells und bestimmt, wie sich das Modell bei der Erstellung von Inhalten auf die relevanten Teile der Eingabedaten "konzentriert".
Der Lader bietet außerdem mehrere Eingabeschnittstellen für eine erweiterte Optimierung:
- Args kompilieren. Über diese Schnittstelle können Sie Folgendes konfigurieren
torch.compile或xformersund andere Kompilierungsoptimierungen.xformersist ein spezielles Werkzeug zur Optimierung der Transformer Bibliotheken für Berechnungen, und dietorch.compileist der in PyTorch 2.0 eingeführte On-the-fly-Compiler. Wenn Sie überTritonCompiler kann eine Beschleunigung von etwa 30% erreicht werden.
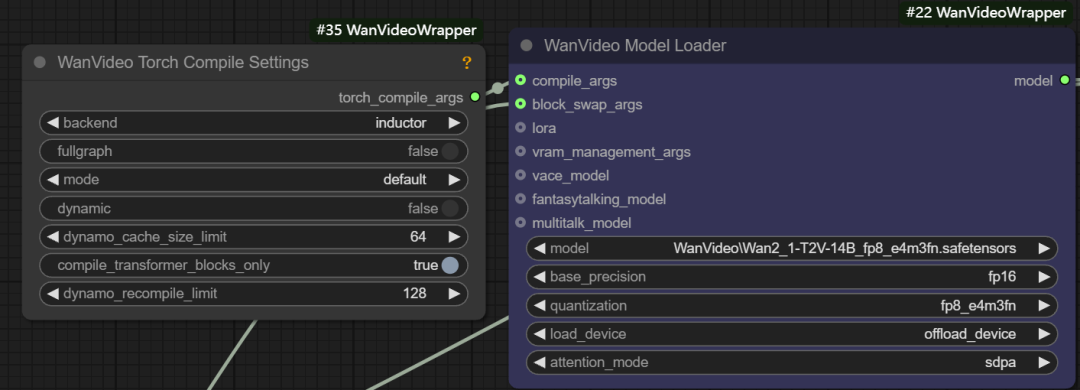
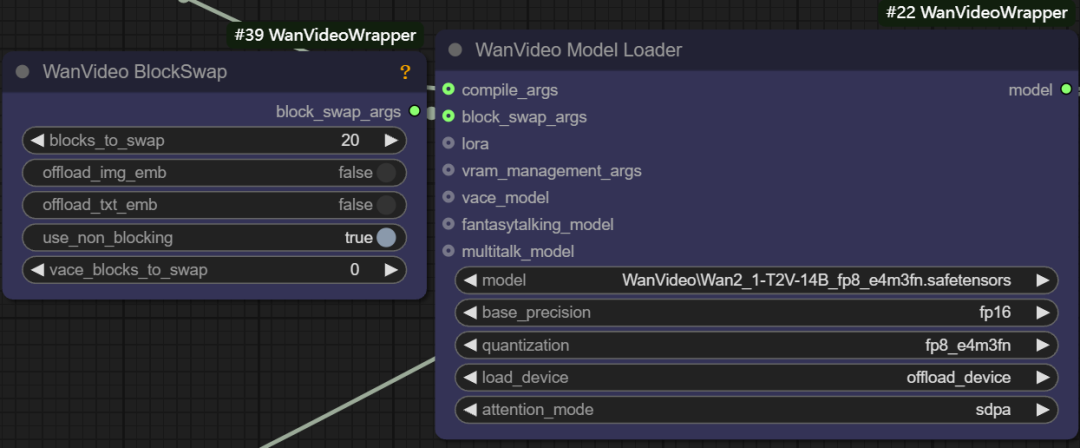
- Block Swap-Argumente. Mit dieser Funktion können einige "Blöcke" des Modells vorübergehend in der CPU gespeichert werden, wenn der Speicher nicht ausreicht, um das gesamte Modell zu speichern, z. B. durch Setzen des Parameters
blocks to swapist 20, was bedeutet, dass 20 Blöcke des Modells aus der GPU verschoben und bei Bedarf über Non-Blocking wieder zurückgeschickt werden. Je mehr Blöcke verschoben werden, desto größer sind die Speichereinsparungen, aber ein gewisses Maß an Generierungsgeschwindigkeit wird durch die Hin- und Herübermittlung von Daten geopfert.
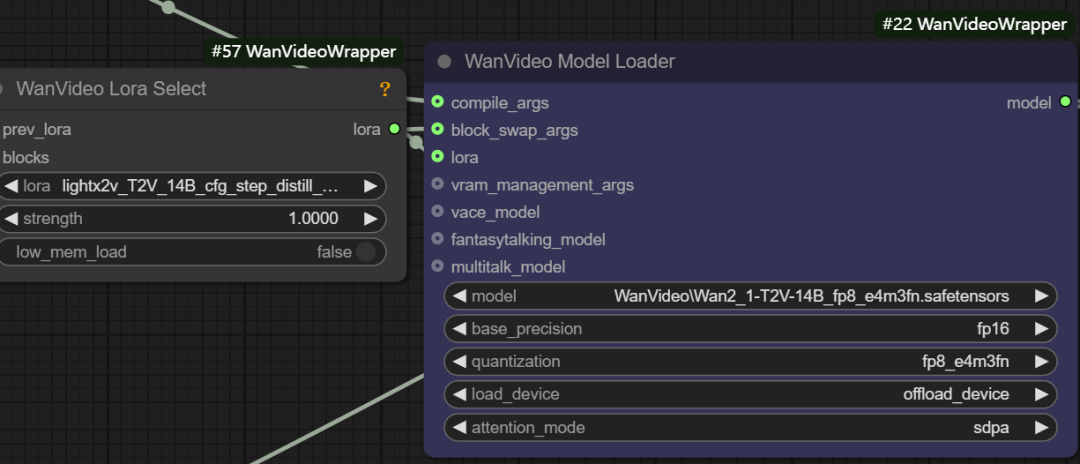
- LoRA Laden. Diese Schnittstelle kann angeschlossen werden an
wanvideo lora selectKnoten zum Laden verschiedener Arten von LoRA-Modellen, z. B. zur Beschleunigung von Vincennes-Videolight x2v t2vLoRA.
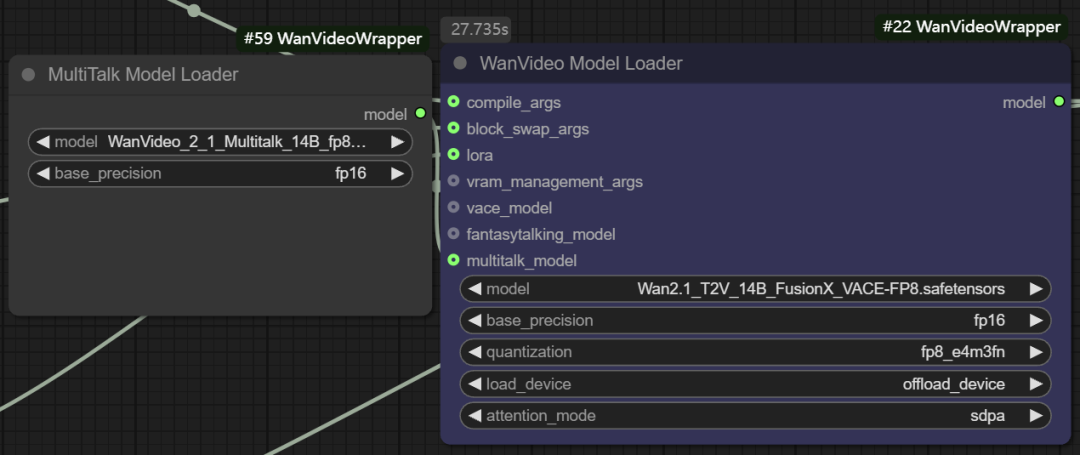
- Multitalk Funktionsmodellierung. Der Knoten unterstützt auch das Laden von
Multitalk、Fantasytalkingund andere digitale Menschenmodelle, die vom Entwickler in die Software integriert werden.wanvideo wrappervon neuen Open-Source-Projekten.
wanvideo sampler
wanvideo sampler stützt sich auf wan2.1 Modellierung kundenspezifischer Videoabtastknoten, die für die Erzeugung von Videosequenzbildern von zentraler Bedeutung sind.
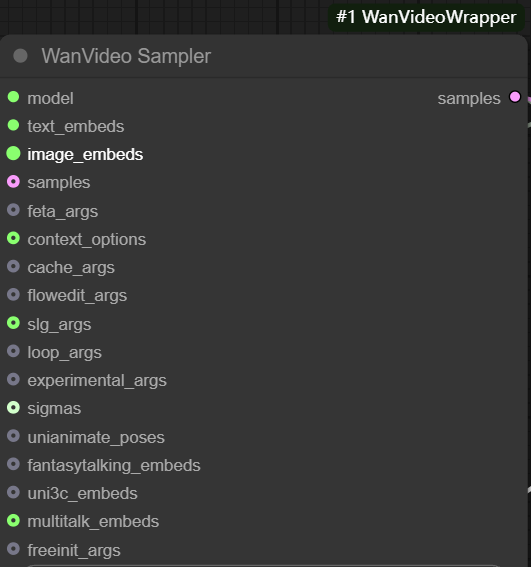
Die wichtigsten Inputs sind:
- model: Verbindung von
wanvideo model loaderDas Modell. - Text einbetten. Mörtel
wanvideo text encodeAusgabe, die dieunmt5Der kodierte Textvektor wird übergeben.
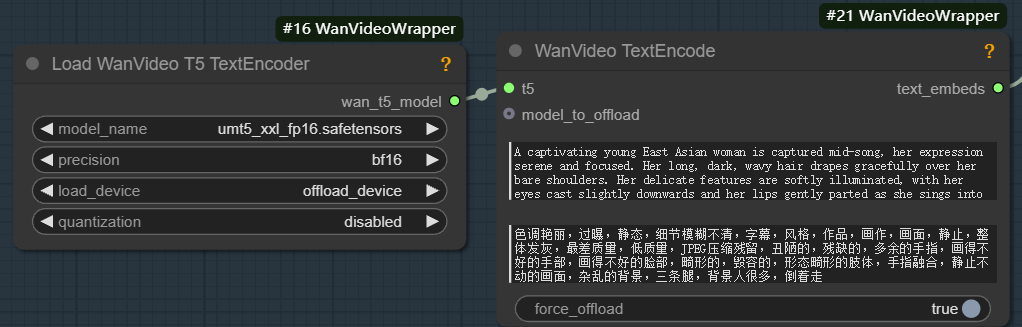
- Bilder einbetten. Wird verwendet, um die Bild-zu-Video-Erzeugung zu ermöglichen. Dieser Arbeitsablauf beginnt normalerweise mit dem
wanvideo clipvision encodeExtrahieren Sie die Referenzkarte derCLIPMerkmale und dann durch diewanvideo image to video encodeDie Knoten verwenden VAE, um Bildmerkmale in eine für das Modell verwendbare Vektordarstellung zu kodieren.
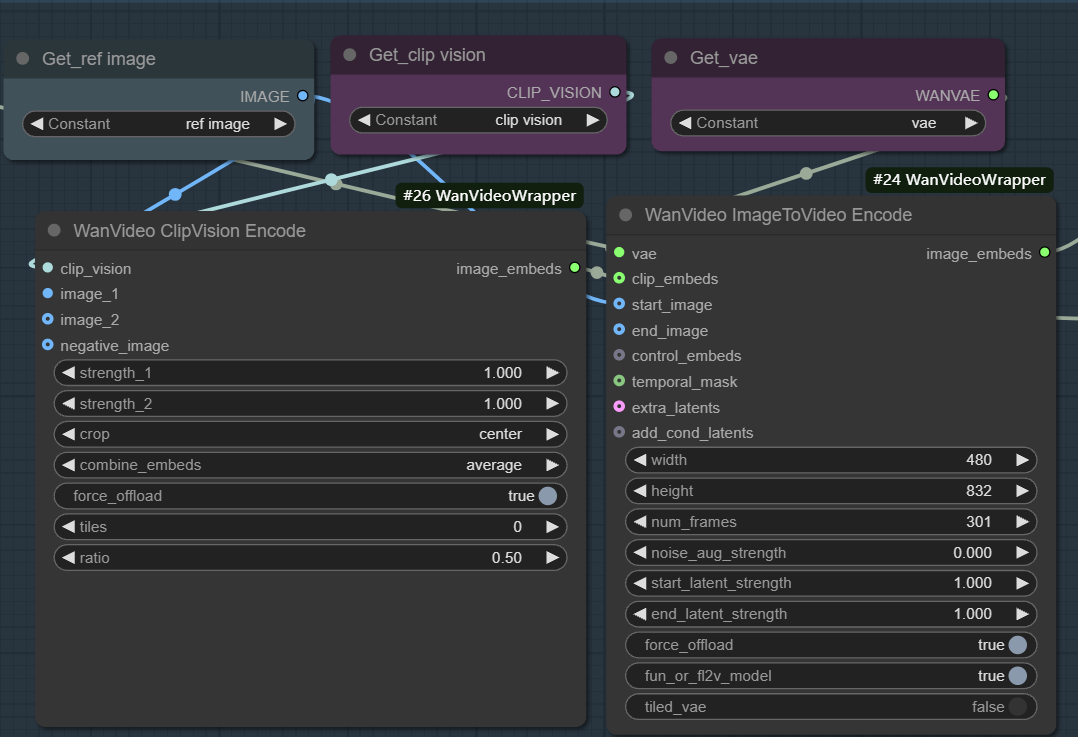
Der Kern dieses Prozesses besteht darin, dass die visuellen und semantischen Informationen eines Standbildes zunächst in Merkmalsvektoren umgewandelt werden und der Sampler dann diese Merkmale als Bootstrap-Bedingung für die iterative Entrauschung ausgehend vom Rauschen verwendet und schließlich aufeinanderfolgende Videobilder erzeugt, deren Inhalt und Stil mit der Referenzkarte übereinstimmen. Durch die Anpassung von Parametern wie Gewichtung, Rauschen und Anzahl der Frames kann der Einfluss der Referenzkarte sowie die Vielfalt des Videos genau gesteuert werden.
- samples: Dieser Eingang könnte theoretisch die Stichprobenergebnisse der vorangegangenen Stufe als Ausgangspunkt für die Diffusionsiteration erhalten, aber seine
latentFormatierung und Standard-Vincennes-TabellenlatentUnvereinbarkeit. - feta args: Dient zur Verbindung von Videoverbesserungsknoten zur Verbesserung der Videodetails, der Bildausrichtung und der Zeitstabilität.
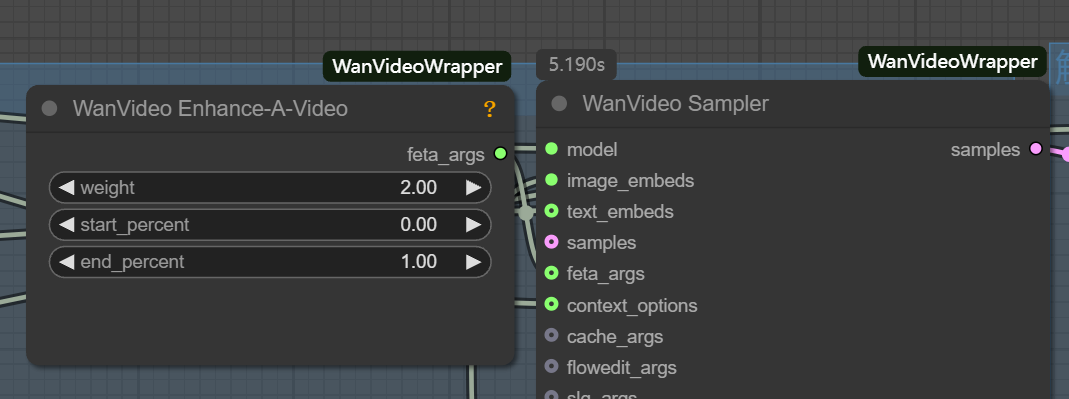
- wanvideo context options: Dies ist der wichtigste Controller zur Gewährleistung der Kohärenz zwischen Videobildern. Er löst das Problem unzusammenhängender Bilder und unnatürlicher Bewegungen, die durch unabhängige Bilderzeugung verursacht werden, indem er die Art und Weise steuert, wie das Modell bei der Erzeugung des aktuellen Bildes auf kontextbezogene Informationen Bezug nimmt.
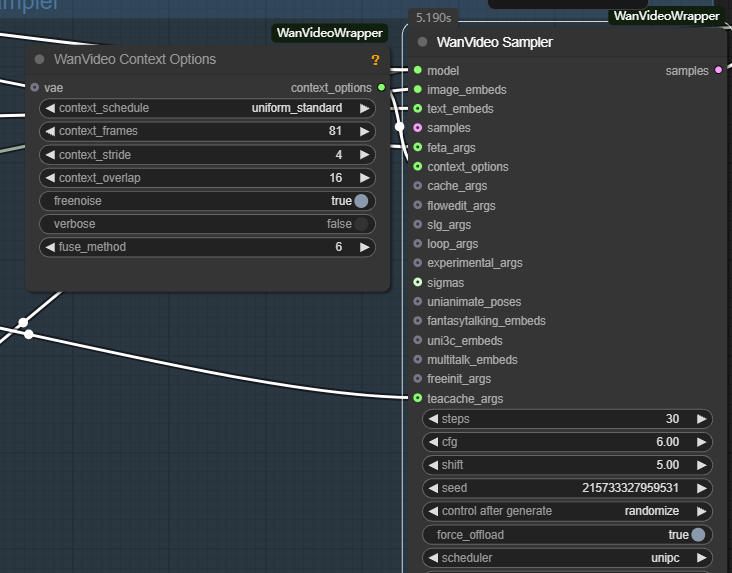
Die wichtigsten Parameter sind folgende:
- context_frames. Legt die Anzahl der benachbarten Frames fest, auf die sich das Modell gleichzeitig bezieht. Je größer der Wert, desto besser ist die Kohärenz von Bewegung und Szenenänderungen, aber der Rechenaufwand steigt entsprechend.
- context_stride (Kontextschritt). Steuert das Intervall zwischen den abgetasteten Referenzbildern. Je kleiner die Schrittweite ist, desto dichter ist die Referenz und desto weicher ist der Detailübergang; je größer die Schrittweite, desto effizienter ist die Berechnung.
- context_overlap. Legt die Anzahl der sich überlappenden Frames zwischen benachbarten Referenzfenstern fest. Eine höhere Überlappung sorgt für fließendere Übergänge zwischen den Frames und vermeidet abrupte Änderungen beim Fensterwechsel.
Das Potenzial der Videomodellierung im Bereich der Venn-Diagramme
Es ist erwähnenswert, dass es wan2.1 Wenn Sie die Ausgabebildrate des Workflows auf 1 setzen, wird er zu einem leistungsstarken Werkzeug für die Texterstellung, das noch besser ist als die Flux und andere spezialisierte Bildmodelle. Videomodelle können aufgrund der zusätzlichen Verarbeitung der zeitlichen Dimension ein besseres Verständnis für die interne Struktur und die Details eines Bildes haben. Dies deutet darauf hin, dass Videomodelle in Zukunft zu einer wichtigen Kraft im Bereich der Standbilderzeugung werden könnten.




























