


SongGeneration ist ein Musikgenerierungsmodell, das von Tencent AI Lab entwickelt und freigegeben wurde. Es konzentriert sich auf die Generierung von qualitativ hochwertigen Songs, einschließlich Text, Begleitung und Gesang. Es basiert auf dem LeVo-Framework, kombiniert das Sprachmodell LeLM und Musik-Codecs und unterstützt die Generierung chinesischer und englischer Songs. Das Modell wurde anhand von Millionen von Songdatensätzen trainiert und kann Musik mit hervorragender Klangqualität und vollständiger Struktur erzeugen, die sich für Musikkompositionen, Videosoundtracks und andere Szenarien eignet. Die Open-Source-Natur von SongGeneration macht die Software für Entwickler, Musikenthusiasten und Autoren von Inhalten zugänglich, und die Unterstützung von Geräten mit geringem Speicherplatz senkt die Hürde für die Nutzung.
Funktionsliste
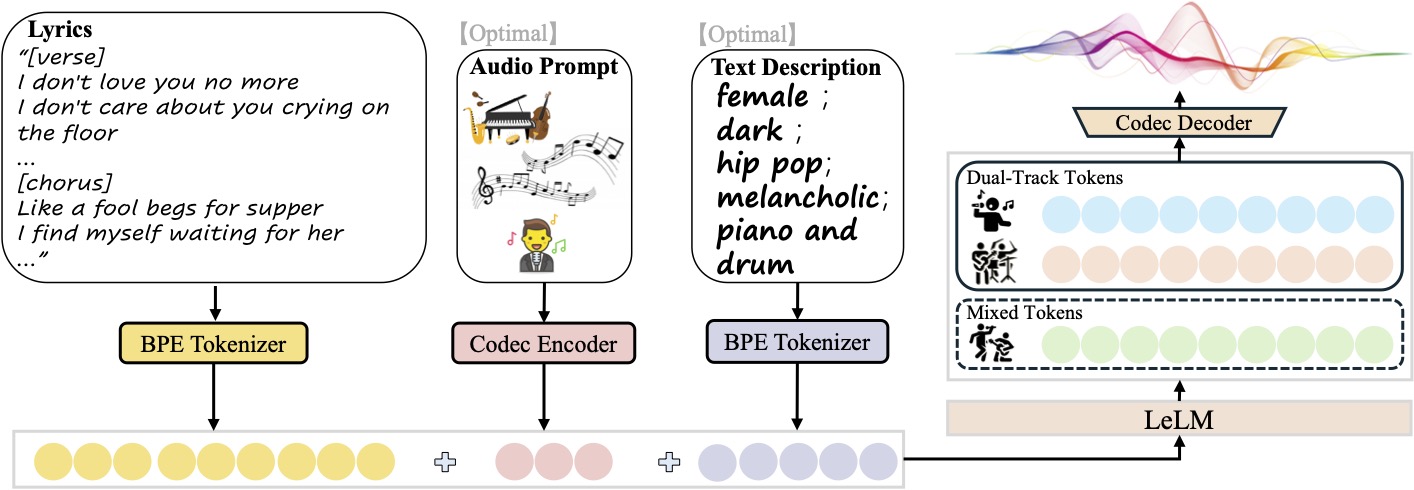
- Song-GenerationGenerieren Sie komplette Songs mit Gesang und Backing Tracks auf der Grundlage von eingegebenen Texten und Textbeschreibungen.
- Mehrspuriger AusgangUnterstützt die getrennte Erstellung von reiner Musik, reinem Gesang oder getrennten Gesangs- und Hintergrundspuren für eine einfache Nachbearbeitung.
- StilkontrolleMusikstile mit Textbeschreibungen anpassen (z. B. Geschlecht, Klangfarbe, Genre, Emotion, Instrument, Takt).
- Referenz AudioDas Modell kann mit einem 10-sekündigen Audioclip hochgeladen werden, und das Modell kann einen neuen Song im gleichen Stil wie diesen generieren.
- Optimierung für geringen SpeicherbedarfUnterstützt den Betrieb mit bis zu 10 GB GPU-Speicher für eine Vielzahl von Geräten.
- Open-Source-UnterstützungModellgewichte, Inferenzskripte und Konfigurationsdateien werden bereitgestellt und können vom Entwickler frei verändert und optimiert werden.
Hilfe verwenden
Einbauverfahren
Um SongGeneration zu verwenden, müssen Sie Ihre Umgebung konfigurieren und das Modell installieren. Hier sind die Schritte, basierend auf dem offiziellen GitHub-Repository, für Linux (Windows-Benutzer können sich an ComfyUI (Version):
- Erstellen einer Python-Umgebung
Mit Python 3.8.12 oder höher wird empfohlen, eine virtuelle Umgebung über conda zu erstellen:conda create -n songgeneration python=3.8.12 conda activate songgeneration - Installation von Abhängigkeiten
Installieren Sie die erforderlichen Abhängigkeiten, einschließlich PyTorch und FFmpeg:yum install ffmpeg pip install -r requirements.txt --no-deps --extra-index-url https://download.pytorch.org/whl/cu118 - Flash Attention installieren (optional)
Um die Inferenz zu beschleunigen, installieren Sie Flash Attention (erfordert CUDA 11.8 oder höher):wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl -P /home/ pip install /home/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whlWenn die GPU Flash Attention nicht unterstützt, können Sie eine Schlussfolgerung zu der
--not_use_flash_attnParameter. - Download Modellgewichte
Laden Sie die Modellgewichte und Profile von Hugging Face herunter und stellen Sie sicher, dass dieckpt和third_partyDer Ordner wird in seiner Gesamtheit im Stammverzeichnis des Projekts gespeichert:git clone https://github.com/tencent-ailab/SongGeneration cd SongGenerationBesuchen Sie das Hugging Face Repository (
https://huggingface.co/tencent/SongGeneration) Herunterladensonggeneration_base_zhoder andere Versionen der Modellgewichte. - Docker-Installation (optional)
Um die Konfiguration zu vereinfachen, können die offiziellen Docker-Images verwendet werden:docker pull juhayna/song-generation-levo:hf0613 docker run -it --gpus all --network=host juhayna/song-generation-levo:hf0613 /bin/bash
Verwendung
SongGeneration unterstützt das Erzeugen von Musik über die Kommandozeile oder ein Skript. Der Hauptvorgang besteht darin, die Eingabedatei vorzubereiten und das Inferenzskript auszuführen. Nachfolgend finden Sie den detaillierten Arbeitsablauf:
- Vorbereiten der Eingabedatei
Die Eingabedatei sollte JSON Lines sein (.jsonl), stellt jede Zeile eine generierte Anfrage dar und enthält die folgenden Felder:idxDateiname: Der Dateiname (eindeutiger Bezeichner) des erzeugten Audios.gt_lyric: Liedtext im Format[结构] 歌词文本z.B..[Verse] 这是第一段歌词。. Zu den unterstützten Strukturen gehören[intro-short]、[verse]、[chorus]usw., unter besonderer Berücksichtigung vonconf/vocab.yaml。descriptions(optional): beschreibt die Musikattribute wiefemale, pop, sad, piano, the bpm is 125。prompt_audio_path(Optional): 10-Sekunden-Referenz-Audiopfad für die Stil-Imitation.
typisches Beispiel
lyrics.jsonl:{"idx": "song1", "gt_lyric": "[intro-short]\n[verse] 这些逝去的回忆。我们无法抹去泪水。\n[chorus] 像傻瓜乞求晚餐。我在等待她的归来。", "descriptions": "female, pop, sad, piano, the bpm is 125"} - Ausführen von Inferenzskripten
Verwenden Sie das Standardskript, um Lieder zu erzeugen:sh generate.sh <ckpt_path> <lyrics.jsonl> <output_path><ckpt_path>Modellgewichtspfade.<lyrics.jsonl>: Geben Sie den Dateipfad ein.<output_path>Speicherpfad für die Audioausgabe.
Wenn der GPU-Speicher nicht ausreicht (<30 GB), verwenden Sie den Modus für geringen Speicherbedarf:
sh generate_lowmem.sh <ckpt_path> <lyrics.jsonl> <output_path> - Benutzerdefinierte Generierungsoptionen
- Reine Musik generieren: hinzufügen
--pure_musicLogo. - Reine Vocals erzeugen: hinzufügen
--pure_vocalLogo. - Separate Gesangs- und Hintergrundspuren: Hinzufügen
--separate_tracksum getrennte Gesangs- und Backing-Spuren zu erzeugen. - Flash deaktivieren Achtung: Hinzufügen
--not_use_flash_attn。
- Reine Musik generieren: hinzufügen
- Windows-Benutzer (ComfyUI-Version)
Windows-Benutzer können die ComfyUI-Oberfläche verwenden, um die Bedienung zu vereinfachen:- Klonen Sie das ComfyUI-Plugin-Repository:
cd ComfyUI/custom_nodes git clone https://github.com/smthemex/ComfyUI_SongGeneration.git - Montage
fairseqBibliothek (vorkompilierte wheel-Dateien werden für Windows empfohlen):pip install liyaodev/fairseq - Setzen Sie die Modellgewichte in die
ComfyUI/models/SongGeneration/Katalog. - Laden Sie das Modell über die ComfyUI-Schnittstelle, geben Sie Text und Beschreibung ein und klicken Sie auf die Schaltfläche Generieren.
- Klonen Sie das ComfyUI-Plugin-Repository:
Vorsichtsmaßnahmen bei der Handhabung
- Eingabeaufforderung: Vermeiden Sie die gleichzeitige Bereitstellung von
prompt_audio_path和descriptionsAndernfalls kann die Qualität der Erzeugung aufgrund von Konflikten beeinträchtigt werden. - TextformatDer Text muss in Abschnitte gegliedert sein (z.B.
[verse]、[chorus]), nicht-lyrische Segmente (wie z. B.[intro-short]) sollte keinen Text enthalten. - Referenz AudioEs wird empfohlen, den Refrain des Liedes (10 Sekunden oder weniger) zu verwenden, um eine optimale Musikalität zu erreichen.
- Hardware-Voraussetzung: 10 GB GPU-Speicher für das Basismodell und 16 GB mit Referenz-Audio.
Anwendungsszenario
- Musikkomposition
Musiker können Texte und Stilbeschreibungen eingeben, um schnell Song-Demos zu erstellen und Zeit zu sparen. Geben Sie zum Beispiel "Männerstimme, Jazz, Klavier, 110 BPM" ein, um einen Jazz-Song zu erstellen. - Video-Soundtrack
Videoersteller können 10 Sekunden Referenzton hochladen, um einen stilisierten Soundtrack für kurze Videos, Werbespots oder Filmmusik zu erstellen. - Spieleentwicklung
Spieleentwickler können mehrspurige Musik generieren und die Gesangs- und Hintergrundspuren separat anpassen, um sie an verschiedene Spielszenarien wie Kämpfe oder Handlungsstränge anzupassen. - Bildung und Experimentieren
Studierende und Forscher können den Open-Source-Code nutzen, um Algorithmen zur Musikerzeugung zu untersuchen oder die Auswirkungen der KI-Musikerzeugung im Unterricht zu testen.
QA
- Welche Sprachen werden von SongGeneration unterstützt?
Das Modell wurde mit einem Datensatz von einer Million Liedern (einschließlich chinesischer und englischer Lieder) trainiert und könnte in Zukunft weitere Sprachen unterstützen. - Wie kann ich die Klangqualität der erzeugten Musik sicherstellen?
Verwenden Sie die offiziellen Modellgewichte und die mitgelieferten Musikcodecs, und stellen Sie sicher, dass die Audio-Sample-Rate 48 kHz beträgt. Vermeiden Sie zu kurze Texte, das Modell wird automatisch vervollständigt, um die strukturelle Integrität zu gewährleisten. - Wie viel Speicherplatz wird für die Ausführung des Modells benötigt?
10 GB GPU-Speicher für das Basismodell und 16 GB mit Referenz-Audio. Low-Memory-Modus (generate_lowmem.sh) kann die Speichernutzung optimiert werden. - Kann kommerziell erzeugte Musik verwendet werden?
Die Musterlizenz (CC BY-NC 4.0) muss überprüft werden, die generierten Inhalte können urheberrechtlichen Einschränkungen unterliegen, und es wird empfohlen, vor der kommerziellen Nutzung einen Rechtsexperten zu konsultieren.


























