

Im Zuge der Entwicklung des Paradigmas der großen Sprachmodellierung und der technischen Praxis hat sich eine Reihe von Anwendungen für Intelligenzen herausgebildet, die den menschlichen Forschungsprozess nachahmen sollen. Diese Intelligenzen sind nicht nur einfache Frage-und-Antwort-Tools, sondern komplexe Systeme, die in der Lage sind, Informationen autonom zu planen, auszuführen, zu reflektieren und zu synthetisieren. In diesem Beitrag werden wir das architektonische Design und die funktionale Umsetzung verschiedener forschungsbasierter intelligenter Körper dekonstruieren, von OpenAI Offizielle Freigabe DeepResearch Der Leitfaden ist eine Ideenquelle, die die wesentlichen Unterschiede und Designphilosophien verschiedener Open-Source-Frameworks eingehend analysiert und Entwicklern und Anwendern eine systematische und strategische Referenz bei der Auswahl von Tools bietet.
Open Source Deep Research Intelligence Body Framework
Vergleich der wichtigsten Konzepte
Derzeit gibt es auf dem Markt zahlreiche Allzweck-Frameworks für intelligente Körper (z. B. Auto-GPT、AutoGen etc.) sind in der Lage, Forschungsaufgaben zu erfüllen, aber dieses Papier konzentriert sich auf sechs Open-Source-Projekte, die mit spezifischen Architekturen für Deep-Research-Szenarien optimiert wurden.
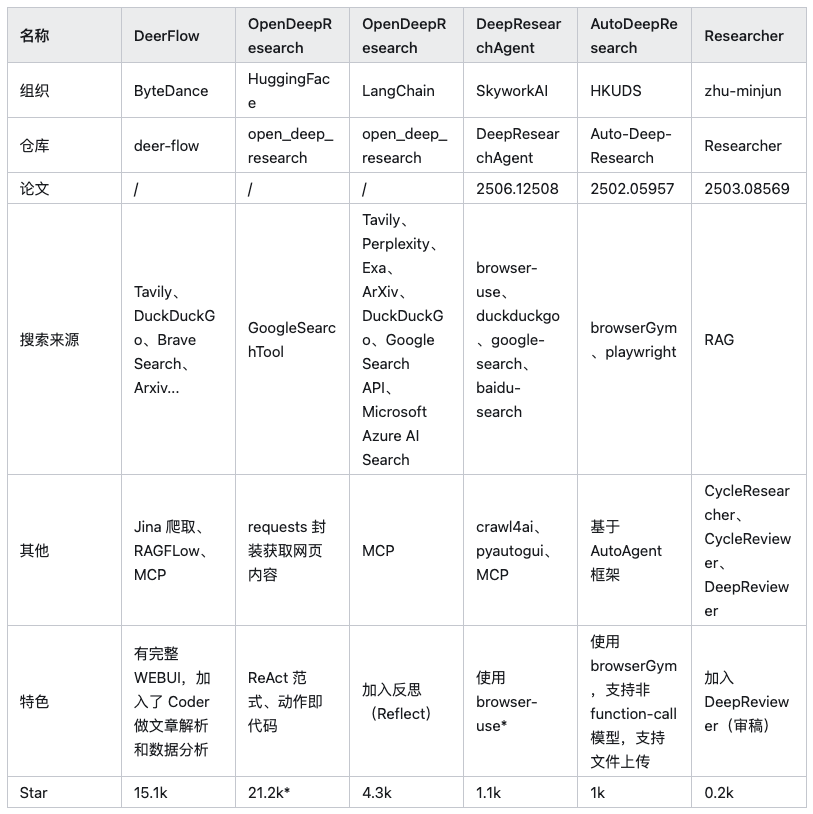
Anmerkung: In der obigen Tabelle HuggingFace/OpenDeepResearch Die Anzahl der Sterne ergibt sich aus der zentralen Abhängigkeit von SmolAgents Projekt.
Bevor wir die einzelnen Rahmenwerke eingehend analysieren, muss eines klar sein: Das Wesen einer eingehenden Untersuchung besteht in der Beschaffung und Integration von Informationen. Als solches ist etwas wie browser-use Solche KI-gesteuerten Browser-Automatisierungstools sind eine wichtige Ergänzung zu all diesen Frameworks. Sie sind für die Durchführung von Aufgaben wie das Laden dynamischer Webseiten, die Interaktion mit Seitenelementen, das Extrahieren von Daten usw. zuständig, wodurch das Problem herkömmlicher Web-Crawler gelöst wird, die Schwierigkeiten haben, mit JavaScript Der Schmerzpunkt des Renderings von Inhalten, aber nicht der Kern der Diskussion in diesem Artikel - der Rahmen selbst.
OpenAI Ein Leitfaden: Das dreistufige Paradigma
OpenAI Die offizielle Dokumentation für das Deep Research Leitfaden wird eine Architektur vorgeschlagen, die als Ideenquelle für fast alle nachfolgenden forschungsbasierten Intelligenzen dient. Der Kerngedanke besteht darin, sich von der Illusion zu verabschieden, Probleme in einem Schritt mit einem einzigen, sperrigen Prompt zu lösen, der extrem anfällig und schwer zu beheben ist. Der Leitfaden plädiert dafür, komplexe Forschungsaufgaben in drei separate modulare Prozesse aufzuteilen:Planen -> Ausführen -> SynthetisierenDies ist eine typische "Teile-und-herrsche"-Strategie, die darauf abzielt, die mit großen Sprachmodellen verbundenen Herausforderungen in Bezug auf weitreichende Schlussfolgerungen und Kontextlängenbeschränkungen zu überwinden. Dies ist eine typische "Teile-und-herrsche"-Strategie, die darauf abzielt, die mit großen Sprachmodellen verbundenen Herausforderungen in Bezug auf weitreichende Schlussfolgerungen, faktische Konsistenz und Kontextlängenbeschränkungen zu überwinden.

- Plan: Verwenden Sie ein Modell höherer Ordnung mit einem hohen Abstraktionsgrad und logischer Argumentation (z. B. das
GPT-4o), zerlegt das Hauptproblem des Nutzers in eine Reihe spezifischer, unabhängig erforschbarer und erschöpfender Teilprobleme. Die Qualität dieses Schrittes bestimmt die Breite und Tiefe der Forschung. - Ausführen:: Jedes Teilproblem wird parallel verarbeitet. Für jedes Teilproblem wird eine externe Such-API aufgerufen, um Informationen zu erhalten und es dem Modell zu ermöglichen, eine erste Zusammenfassung und Faktenextraktion aus einer einzigen Informationsquelle durchzuführen. Dies ist eine hochparallele Phase der Informationsbeschaffung.
- Synthese (Synthesieren)Zusammenfassen der Antworten auf alle Teilfragen und Übergabe an das übergeordnete Modell zur abschließenden Integration, Analyse und Ausschmückung zu einem logisch zusammenhängenden und klar strukturierten Abschlussbericht.
Umsetzungsstrategien und bewährte Praktiken
Auf der Grundlage dieser Kernstruktur werden im Folgenden einige wichtige Praxisstrategien vorgestellt:
1. die Wahl des richtigen Modells für die richtige Aufgabe
Dies ist das Kernstück der Kosten- und Leistungsoptimierung. Die verschiedenen Phasen erfordern unterschiedliche Arten von "Intelligenz". Die Phasen "Planung" und "Synthese" erfordern leistungsfähigeGlobales Denken, logische Organisation und kreative generative FähigkeitenNachfolgend ein Beispiel für die Art der Daten, die in der GPT-4o 或 GPT-4 Turbo Dies sind die Spitzenmodelle, da ihre Leistung die Obergrenze für die Qualität des endgültigen Berichts bestimmt. In der "Ausführungsphase" konzentriert sich die Aufgabe, einzelne Webseiten zusammenzufassen, mehr aufInformationsextraktion und faktische AnreicherungVerwenden Sie GPT-3.5-Turbo oder andere schnellere Modelle können Kosten und Latenzzeiten bei gleichbleibender Qualität drastisch reduzieren. Eine einzige Deep Research-Anfrage kann Dutzende von API-Aufrufen auslösen, und ohne Modellhierarchien können die Kosten schnell eskalieren.
2. parallele Verarbeitung zur Maximierung der Effizienz
Die Teilprobleme der Studie sind in der Regel unabhängig voneinander, und eine serielle Bearbeitung ist äußerst zeitaufwändig. In der Phase "Ausführung" sollte die Liste der Teilprobleme nach ihrer Erstellung asynchron programmiert werden (z.B. durch den Python 的 asyncio), um Rechercheaufträge parallel zu initiieren. Dadurch kann ein mehrminütiger Prozess auf weniger als eine Minute verkürzt werden. Die Entwickler müssen jedoch die Ratenbeschränkungen der API-Anbieter beachten, insbesondere die TPM (Anzahl der verarbeiteten Token pro Minute). Parallele Anrufe können sofort eine große Anzahl von Anfragen generieren, die über die TPM Begrenzungen führen zu Fehlschlägen bei Anfragen, so dass gut konzipierte Warteschlangen und Wiederholungsmechanismen erforderlich sind.
3. eine strukturierte Ausgabe durch Funktionsaufrufe oder JSON-Muster zu gewährleisten
Um einen stabilen und zuverlässigen Arbeitsablauf zu gewährleisten, sollten Modelle stets maschinenlesbare, strukturierte Daten zurückliefern können, statt Code, der instabilen Text in natürlicher Sprache parst.OpenAI Der beste Weg, dies zu erreichen, ist die Funktion "Funktionsaufruf" oder "JSON-Modus". Es ist das Äquivalent eines Funktionsaufrufs zwischen dem Code und dem LLM Dadurch wird ein solider API-Vertrag geschaffen. In der Planungsphase können Sie das Modell zwingen, eine JSON-Liste mit allen Teilproblemstrings auszugeben, und in der Ausführungsphase können Sie auch verlangen, dass das Modell die Ergebnisse in einem festen JSON-Format zurückgibt, z. B. {"summary": "...", "key_points": [...]}。
4. die Integration von hochwertigen externen Suchwerkzeugen
Sprachmodelle haben von Natur aus keine Echtzeit-Vernetzungsfähigkeiten, und ihr Wissen leidet unter einer Verzögerung. Daher ist es wichtig, eine oder mehrere hochwertige Such-APIs zu integrieren (wie z. B. die Google Search API、Brave Search API、Serper usw.), um auf umfassende Informationen in Echtzeit zuzugreifen. Die explizite Information des Modells im Cue-Word, dass es diese Tools nutzen kann, und die Rückgabe der Outputs der Tools an das Modell durch Funktionsaufrufe usw. ist die Grundlage für die Ausstattung des Modells mit Forschungsfähigkeiten.
5. die Ausarbeitung von Prompts für jede Phase (Prompt Engineering)
Stichwortwörter sind der Schlüssel zur Bestimmung der Qualität jeder Phase. Die Stichworte für jede Phase sollten sorgfältig ausgewählt werden, um das Modell zu leiten, die richtige Rolle zu spielen und die gewünschten Ergebnisse zu erzielen. Die folgenden Beispieleingaben, die im offiziellen Leitfaden enthalten sind, sind sehr informativ.
Ursprüngliche Frage.
Research the economic impact of semaglutide on global healthcare systems.
Do:
- Include specific figures, trends, statistics, and measurable outcomes.
- Prioritize reliable, up-to-date sources: peer-reviewed research, health
organizations (e.g., WHO, CDC), regulatory agencies, or pharmaceutical
earnings reports.
- Include inline citations and return all source metadata.
Be analytical, avoid generalities, and ensure that each section supports
data-backed reasoning that could inform healthcare policy or financial modeling.
研究索马鲁肽对全球医疗保健系统的经济影响。
应做的:
- 包含具体的数字、趋势、统计数据和可衡量的成果。
- 优先考虑可靠、最新的来源:同行评审的研究、卫生组织(例如世界卫生组织、美国疾病控制与预防中心)、监管机构或制药公司
的盈利报告。
- 包含内联引用并返回所有来源元数据。
进行分析,避免泛泛而谈,并确保每个部分都支持
数据支持的推理,这些推理可以为医疗保健政策或财务模型提供参考。
Klärung der Frage.
Der Zweck dieses Schrittes ist, dass der intelligente Körper wie ein echter Berater agiert und sicherstellt, dass die Absichten des Nutzers vollständig verstanden werden, bevor er mit der teuren Recherche beginnt.
You are talking to a user who is asking for a research task to be conducted. Your job is to gather more information from the user to successfully complete the task.
GUIDELINES:
- Be concise while gathering all necessary information
- Make sure to gather all the information needed to carry out the research task in a concise, well-structured manner.
- Use bullet points or numbered lists if appropriate for clarity.
- Don't ask for unnecessary information, or information that the user has already provided.
IMPORTANT: Do NOT conduct any research yourself, just gather information that will be given to a researcher to conduct the research task.
您正在与一位请求开展研究任务的用户交谈。您的工作是从用户那里收集更多信息,以成功完成任务。
指导原则:
- 收集所有必要信息时务必简洁
- 确保以简洁、结构良好的方式收集完成研究任务所需的所有信息。
- 为清晰起见,请根据需要使用项目符号或编号列表。
- 请勿询问不必要的信息或用户已提供的信息。
重要提示:请勿自行进行任何研究,只需收集将提供给研究人员进行研究任务的信息即可。
Umschreiben von Benutzeraufforderungen.
In diesem Schritt wird die gesprochene Anfrage des Benutzers in eine detaillierte und eindeutige schriftliche Anweisung an die Researcher Intelligence übersetzt.
You will be given a research task by a user. Your job is to produce a set of
instructions for a researcher that will complete the task. Do NOT complete the
task yourself, just provide instructions on how to complete it.
GUIDELINES:
1. **Maximize Specificity and Detail**
- Include all known user preferences and explicitly list key attributes or
dimensions to consider.
- It is of utmost importance that all details from the user are included in
the instructions.
2. **Fill in Unstated But Necessary Dimensions as Open-Ended**
- If certain attributes are essential for a meaningful output but the user
has not provided them, explicitly state that they are open-ended or default
to no specific constraint.
3. **Avoid Unwarranted Assumptions**
- If the user has not provided a particular detail, do not invent one.
- Instead, state the lack of specification and guide the researcher to treat
it as flexible or accept all possible options.
4. **Use the First Person**
- Phrase the request from the perspective of the user.
5. **Tables**
- If you determine that including a table will help illustrate, organize, or
enhance the information in the research output, you must explicitly request
that the researcher provide them.
6. **Headers and Formatting**
- You should include the expected output format in the prompt.
- If the user is asking for content that would be best returned in a
structured format (e.g. a report, plan, etc.), ask the researcher to format
as a report with the appropriate headers and formatting that ensures clarity
and structure.
7. **Language**
- If the user input is in a language other than English, tell the researcher
to respond in this language, unless the user query explicitly asks for the
response in a different language.
8. **Sources**
- If specific sources should be prioritized, specify them in the prompt.
- For product and travel research, prefer linking directly to official or
primary websites...
- For academic or scientific queries, prefer linking directly to the original
paper or official journal publication...
- If the query is in a specific language, prioritize sources published in that
language.
6. die Einführung von Human-in-the-Loop (HIL) an Schlüsselstellen.
Bei schwerwiegenden oder risikoreichen Forschungsaufgaben sind vollautomatische Prozesse unzuverlässig. Die Einführung eines "Human-in-the-Loop" ist nicht nur eine Funktion, sondern eine Philosophie der Mensch-Computer-Zusammenarbeit. Eine wirksame Praxis ist die Einbeziehung eines menschlichen Überprüfungsprozesses nach der "Planungs"-Phase, bei dem der Benutzer die vom Modell generierte Liste von Teilproblemen überprüft, ändert und validiert, um sicherzustellen, dass die Richtung der Forschung richtig ist, bevor die kostspielige "Ausführungs"-Phase eingeleitet wird. Auf diese Weise wird vermieden, dass "Müll reinkommt, Müll rauskommt", und die Verantwortlichkeit für die Endergebnisse wird sichergestellt.
Analyse der Open-Source-Architektur
Im Folgenden werden die architektonischen Merkmale der einzelnen Rahmenwerke nacheinander untersucht.
ByteDance/DeerFlowA graph-based hierarchical multi-intelligent body system
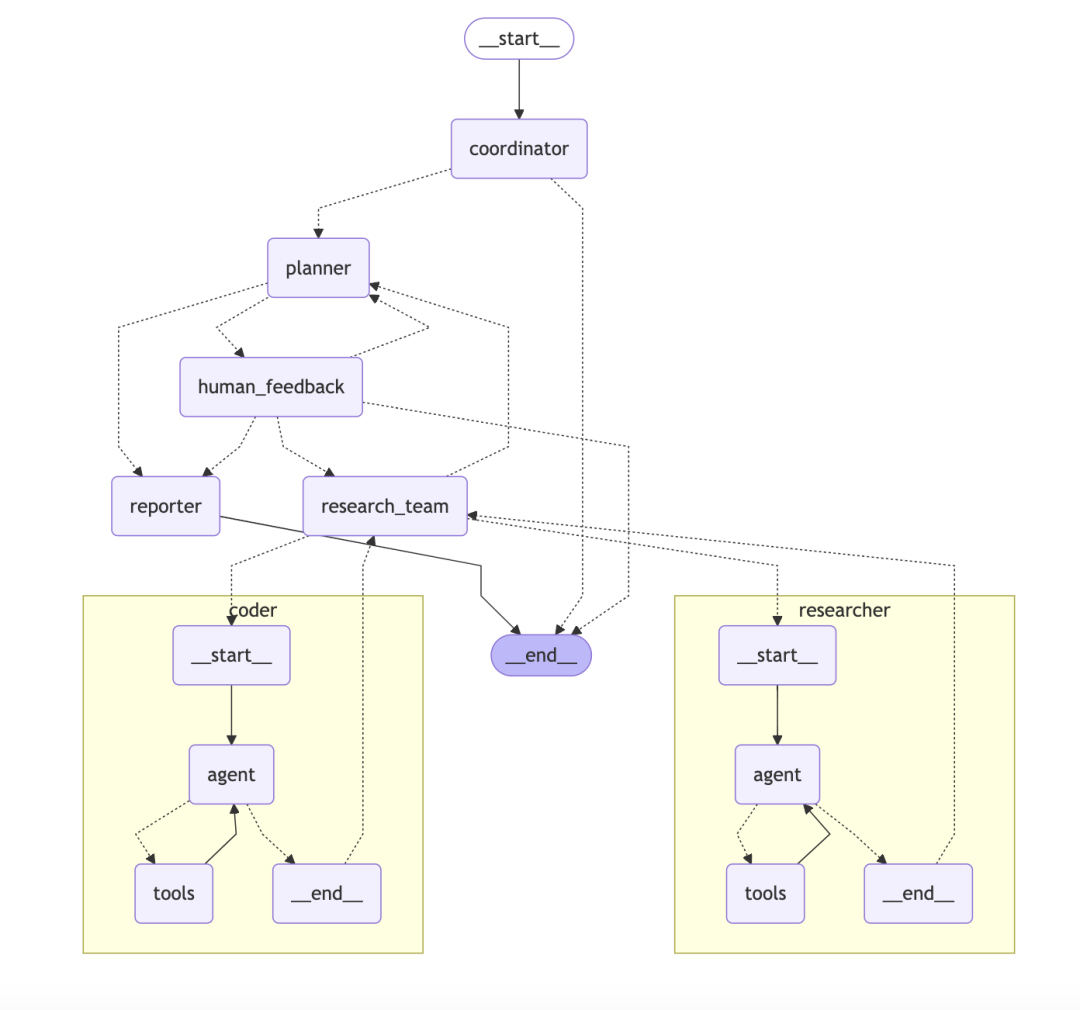
DeerFlow Die Architektur ist ein modulares, hierarchisches, multi-intelligentes Körpersystem, wie ein automatisiertes Forschungsteam mit klaren Zielen und einer klaren Arbeitsteilung.
- Kernarchitektur:: Das System besteht aus mehreren Rollen, die zusammenarbeiten:
- KoordinatorProjektleiter, Entgegennahme von Benutzeranfragen, Initiierung und Verwaltung des Prozesses.
- PlanerAls Stratege können Sie komplexe Probleme in strukturierte Schritte zerlegen.
- Forschungsteam:: Als Ausführende gibt es "Forscher", die das Web durchsuchen, und "Programmierer", die den Code ausführen.
- ReporterAls Endergebnis werden alle Informationen in Berichten, Podcasts und sogar PPTs konsolidiert.
- Technische Merkmale:
DeerFlowDas technologische Highlight ist, dass es aufLangChain和LangGraphOben.LangGraphist eine Schlüsselkomponente, die es Entwicklern ermöglicht, Multi-Intelligenz-Workflows in dieZustandsdiagrammeJede Intelligenz oder jedes Werkzeug kann als ein Knoten im Graphen betrachtet werden. Jede Intelligenz oder jedes Werkzeug kann als ein Knoten im Graphen betrachtet werden, und die Richtung des Arbeitsablaufs wird durch Kanten definiert. Dieser Ansatz unterstützt natürlich komplexe Prozesse, die Schleifen enthalten, wie die Reflect-Correct-Schleife, wodurch der gesamte Forschungsprozess nicht nur linear, sondern auch nachvollziehbar und debuggbar wird.
Kommentar des Kolumnisten: DeerFlow Das Design ist klar und gut definiert für Teams oder Unternehmensanwendungen, die stabil und skalierbar sein und komplexe Arbeitsabläufe unterstützen müssen. Dies wird erreicht durch die Einführung LangGraphDadurch wird die intelligente Zusammenarbeit von einfachen Kettenaufrufen zu einem überschaubaren, zyklischen grafischen Netzwerk, das eher einer "Plattform für das Management von Forschungsprozessen" als einem einfachen Werkzeug gleicht.
HuggingFace/OpenDeepResearchDie minimalistische Philosophie von Code-als-Aktion
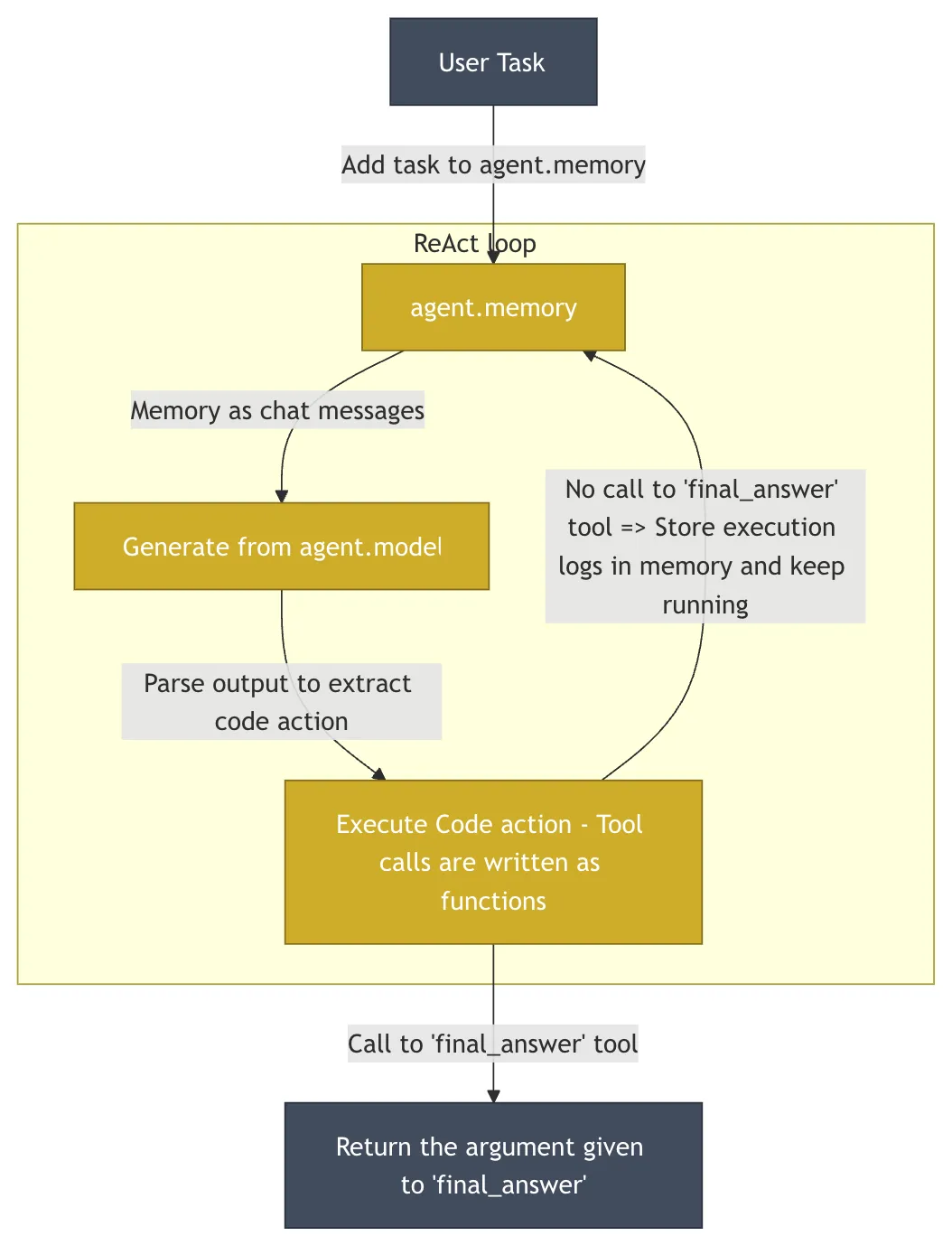
HuggingFace 的 OpenDeepResearch Das Projekt, das im Kern aus folgenden Elementen besteht smolagents Antrieb, der die gleichen Eigenschaften wie der DeerFlow sehr unterschiedliche Entwurfsphilosophien. Das Projekt ist in GAIA (General AI-Assisted Agent) - ein definitiver Benchmark zur Messung der Fähigkeiten allgemeiner KI-Intelligenzen anhand von Aufgaben aus der realen Welt - auf die erreichte Validierungsmenge 55% pass@1-Punktzahl. Diese Punktzahl ist niedriger als die ChatGPT 的 67%als Open-Source-Implementierung hat seine Leistungsfähigkeit unter Beweis gestellt.
- Kerngedanke:: Einfachheit und minimale Abstraktion.
smolagentsDie Codebasis ist absichtlich sehr klein gehalten (~1000 Zeilen), um die in vielen Frameworks übliche Überabstraktion zu vermeiden und den Entwicklern ein hohes Maß an Transparenz und Kontrolle zu bieten. - KernarchitekturDas Herzstück ist die "Code Intelligence" (
CodeAgent). Die Handlungen der intelligiblen Wesen werden direkt ausgedrückt alsPythonCodefragment anstelle desJSONObjekt.LLMErzeugen Sie einen kleinen AbsatzPythonCode, um die nächste Aktion auszuführen. Dieser Ansatz ist viel aussagekräftiger alsJSONDenn der Code unterstützt natürlich komplexe Logik wie Schleifen, Bedingungen, Funktionsdefinitionen und mehr. Allerdings birgt die Ausführung von beliebigem, durch KI erzeugtem Code erhebliche Sicherheitsrisiken. Aus diesem Grund ist diesmolagentsUnterstützung in Bereichen wieE2BwieSandkasten Führen Sie den Code in derE2BEine isolierte Wolke bereitstellenLinuxUmgebung, in der der von der KI erzeugte Code ausgeführt wird, mit Zugriff auf das Dateisystem und das Netzwerk, aber ohne die Möglichkeit, das Hostsystem zu beeinflussen.
Kommentar des Kolumnisten: smolagents Das Konzept "Code ist Aktion" ist eine attraktive Möglichkeit, zu den Grundlagen der Programmierung zurückzukehren und den Intelligenzen mehr Flexibilität als je zuvor zu geben. Es ist eine gute Wahl für Entwickler, die das Verhalten ihrer Intelligenz umfassend anpassen und vollständig kontrollieren wollen. Die Philosophie besteht darin, dem Entwickler ein Maximum an Macht zu geben und gleichzeitig Sicherheitsleitplanken zu setzen.
LangChainAI/OpenDeepResearch: Diagrammatische Arbeitsabläufe und metakognitive Reflexion
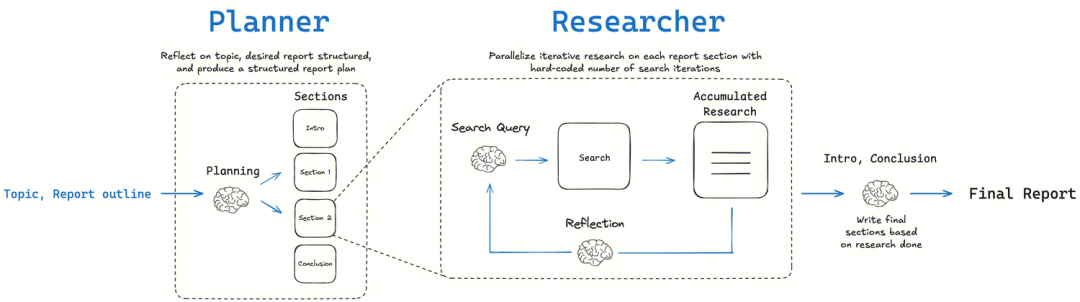
LangChain gemeindebasiert open_deep_research Das Herzstück des Projekts ist ein mehrstufiger, iterativer und selbstreflexiver Arbeitsablauf, der den Forschungsprozess eines menschlichen Experten nachahmen soll.
- Grundlegende Konzepte: Planen-Suchen-Reflektieren-SchreibenDer Schlüssel zu dieser Struktur ist die Komponente "Reflexion". Der Schlüssel zu dieser Struktur ist die Komponente "Reflexion". Hier geht es nicht nur um die Überprüfung auf Fehler, sondern um eineMetakognition Dies ist der Ausdruck für das "Nachdenken über den eigenen Denkprozess". Nach dem Sammeln erster Informationen bewertet die Intelligenz die Vollständigkeit der aktuellen Informationen und ob es Widersprüche oder Wissenslücken gibt. Werden Unzulänglichkeiten festgestellt, wird eine neue, präzisere Suchanfrage gestellt und die nächste Iteration eingeleitet.
- Umsetzungsmethode:
- Graphenbasierter Arbeitsablauf:: Wie in
DeerFlowEs wird hauptsächlich verwendetLangGraphAufbauen. Jeder Schritt der Studie wird als Knoten im Graphen modelliert, wodurch der gesamte Prozess sehr anschaulich, nachvollziehbar und leicht zu debuggen ist. Dieser Ansatz eignet sich ideal für Szenarien, die menschliches Eingreifen und eine hochpräzise Steuerung erfordern. - Iterative Schleife mit mehreren AgentenDurch rekursive Rechercheschleifen wertet die Intelligenz vorhandene Informationen aus, generiert neue Fragen und sucht in jeder Schleife weiter. Dieser Ansatz wird in zwei Modi unterteilt:
简单模式 (Simple)Der direkte Zugriff auf eine einzelne iterative Schleife ist schnell und für bestimmte Probleme geeignet;深度模式 (Deep)Beinhaltet die anfängliche Planung und setzt parallele Forscher für jedes Unterthema ein, vertieft und umfassend für komplexe Themen.
- Graphenbasierter Arbeitsablauf:: Wie in
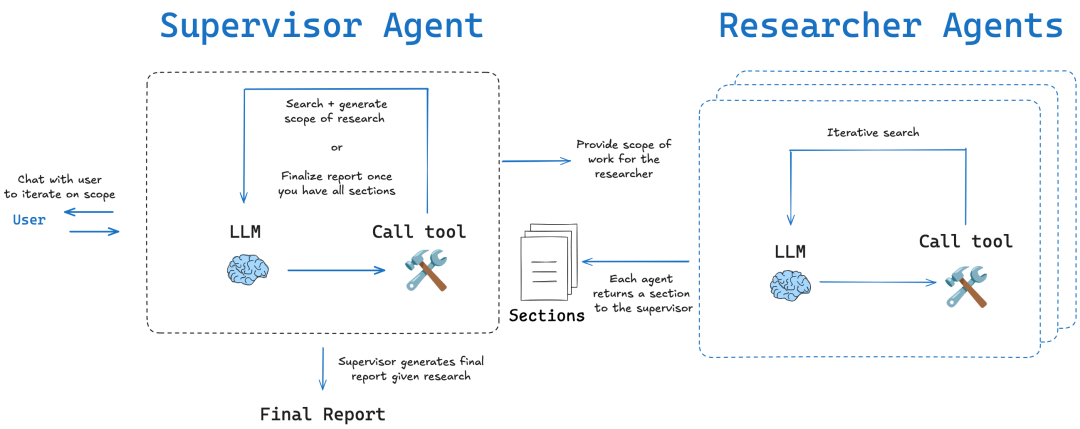
Kommentar des Kolumnisten: LangChain Diese Version ist ein hervorragendes Beispiel für Modularität und Flexibilität. Sie setzt das kognitionswissenschaftliche Konzept der "Selbstreflexion" erfolgreich um durch die Verwendung von LangGraph Bietet leistungsstarke Modellierungsfunktionen für komplexe, nicht-lineare Forschungsaufgaben und ist ideal für Teams, die ihre Forschungsprozesse produktiv gestalten müssen.
SkyworkAI/DeepResearchAgentKlassische Schichtung und Trennung von Belangen
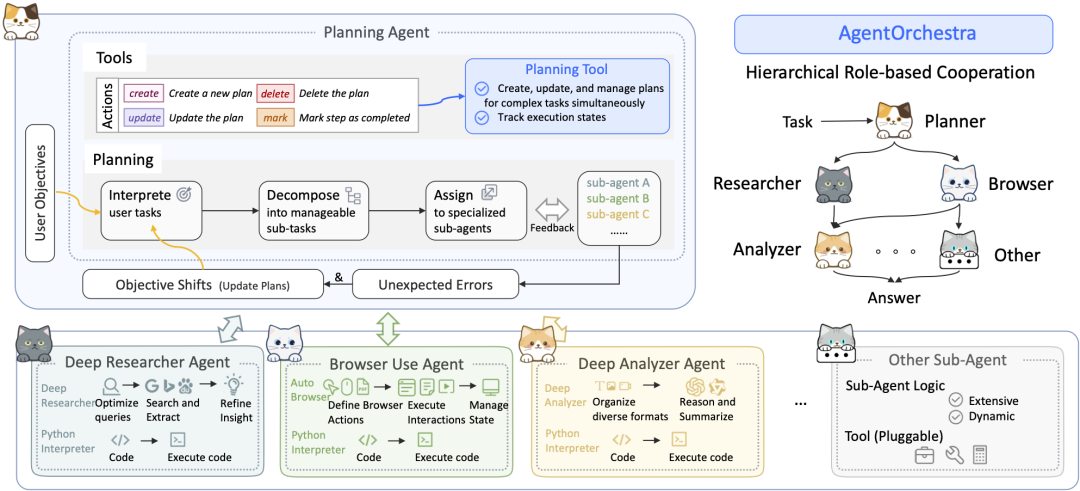
SkyworkAI 的 DeepResearchAgent Es wird eine explizite Zwei-Schichten-Architektur (Two-Layer) verwendet, ein sehr klassisches Entwurfsmuster in der Softwareentwicklung, dessen Kernstück dieTrennung der Belange。
- Kernarchitektur:
- Schicht 1: Top-Level-Planungsagent:: Dient als "Strategieschicht" oder "Geschäftslogikschicht". Sie führt keine spezifischen Forschungsaufgaben aus, sondern ist dafür verantwortlich, die Absicht der Benutzer zu verstehen, ehrgeizige Ziele in eine Reihe von überschaubaren Teilaufgaben zu zerlegen und Arbeitsablaufpläne zu entwickeln.
- Agenten der unteren Ebene (spezialisierte Agenten der unteren Ebene):: Spielt die Rolle der "Ausführungsschicht" oder "Dienstschicht". Sie besteht aus mehreren Intelligenzen mit unterschiedlichen Spezialisierungen, wie "Deep Analyzers" für die Informationsanalyse, "Deep Researchers" für die Websuche und "Browser User" für die Browserbedienung. "Sie führen die von den oberen Schichten zugewiesenen Aufgaben gewissenhaft aus.
- Architektur-Inspiration:: Das Projekt wurde in seiner jetzigen Form umgesetzt.
READMESie weist ausdrücklich darauf hin, dass ihre Architektur Gegenstand vonsmolagentsinspiriert und baut mit modularen und asynchronen Verbesserungen darauf auf. Dies spiegelt seinen Versuch wider, diesmolagentsDie Einfachheit des Konzepts mit einem strukturierteren Modell der Zusammenarbeit mehrerer intelligenter Körper.
Kommentar des Kolumnisten: DeepResearchAgent Durch die zweistufige Architektur wird eine gute Entkopplung zwischen "Planung" und "Ausführung" erreicht. Der Entwurf ist gut strukturiert und skalierbar, und in Zukunft wird es einfach sein, der zweiten Ebene mehr spezialisierte Intelligenz hinzuzufügen (z. B. Datenvisualisierung, Codeausführung usw.), ohne die Kernplanungslogik auf der oberen Ebene ändern zu müssen. Dies ist eine pragmatische und technisch ausgereifte Implementierung.
zhu-minjun/ResearcherKonfrontative Selbstkritikmechanismen
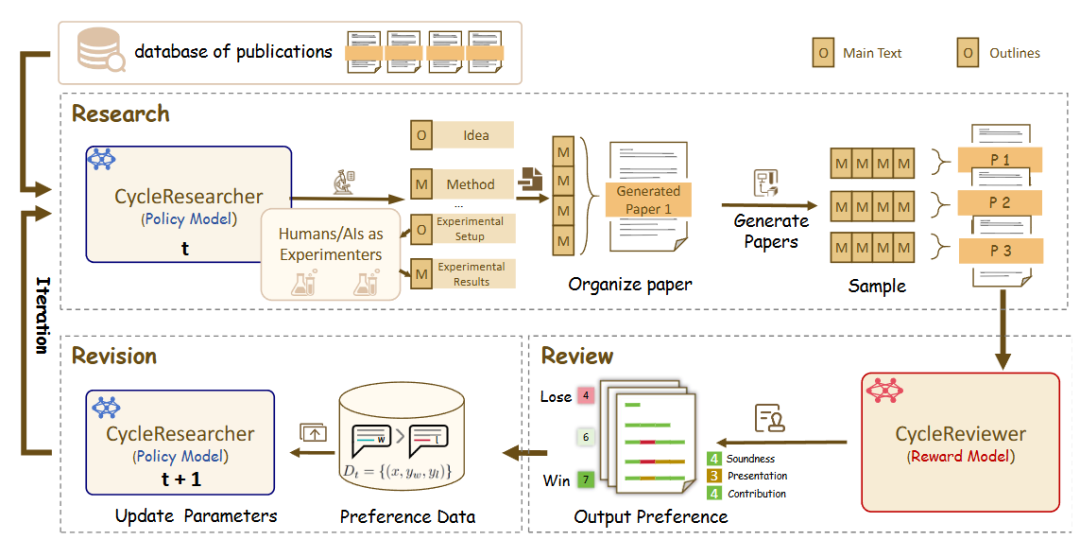
zhu-minjun/Researcher Architektur ist eine ähnlich gestaffelte Multi-Intelligenz-Zusammenarbeit, aber ihr bemerkenswertestes Merkmal ist die Einführung unabhängiger, man könnte sogar sagenKonfrontative "Selbstkritik"-Sitzungen。
- Kernarchitektur:
- Intelligente Planung:: Entwicklung von Forschungsprogrammen und Konzepten.
- Parallele Ausführungsintelligenz:: Unabhängige exekutive Intelligenzen für jedes Unterthema einführen, um Informationen parallel zu sammeln.
- Integration und Erstellung eines ersten Entwurfs:: Zusammenfassung aller Ergebnisse in einem ersten Entwurf.
- Kritische und revisionistische Intelligenz:: Dies ist der Höhepunkt der Architektur. Sie stellt die "Reflexion" als unabhängige "kritische Intelligenz" dar. Diese Intelligenz fungiert als strenger und skeptischer Prüfer, der die Qualität des ersten Entwurfs in Frage stellt und auf der Grundlage vordefinierter Regeln (z. B. sachliche Richtigkeit, Objektivität, Vollständigkeit der logischen Kette, Vorhandensein von Verzerrungen) spezifische und konstruktive Änderungen vorschlägt. Das System nimmt dann auf der Grundlage dieses Feedbacks Korrekturen vor, wodurch eine geschlossene Schleife iterativer Optimierung entsteht.
- DeepReviewer: In seinem
BestModus wird das Projekt durch eine Datei namensDeepReviewerModul, um diese umfassende Prüfungserfahrung zu erreichen, und es kann sogar dieMulti-Auditor-SimulationDer Bericht wird einem Stresstest unterzogen, der dem Peer-Review-Verfahren im akademischen Bereich ähnelt.
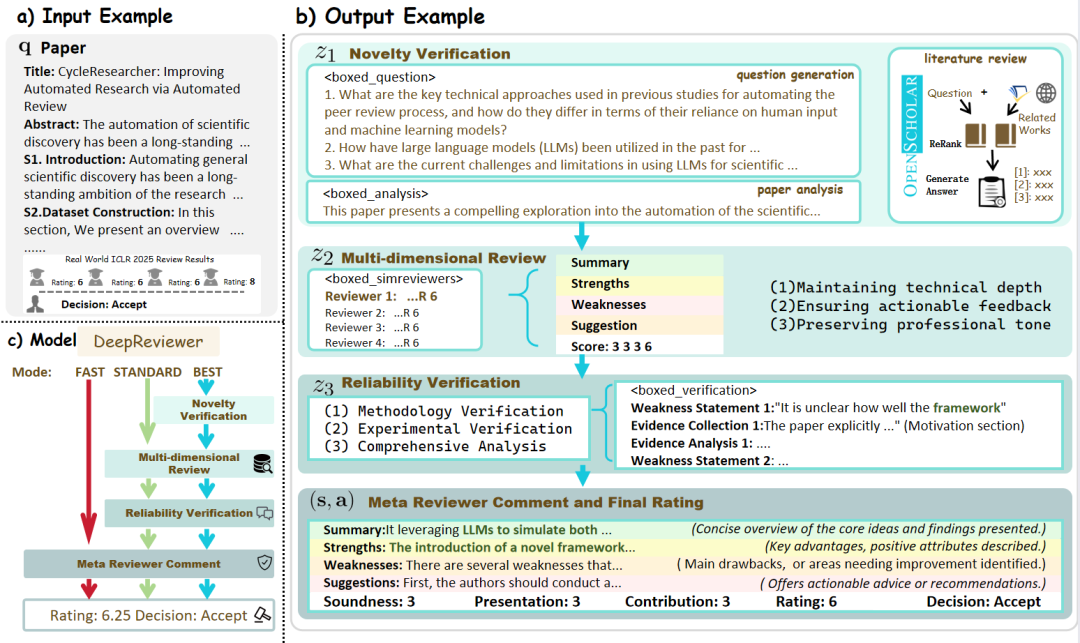
Kommentar des Kolumnisten:: Das Projekt wertet die "Reflexion" von einem internen Zustand zu einem externen, strukturierten Prozess der Konfrontation auf. Dieses "Links-Rechts"-Design macht es nicht nur zu einem Aggregator von Informationen, sondern auch zu einem "Forscher", der sich selbst ständig herausfordert, die Qualität seiner Inhalte zu verbessern, und der nach Objektivität und Vollständigkeit strebt.
Kommerzialisierung eingehende Forschung Intelligente Körperuhr
Nach der Analyse von Open-Source-Frameworks für Entwickler bieten kommerzielle Anwendungen für Endnutzer eine nahtlosere, produktorientierte Erfahrung.
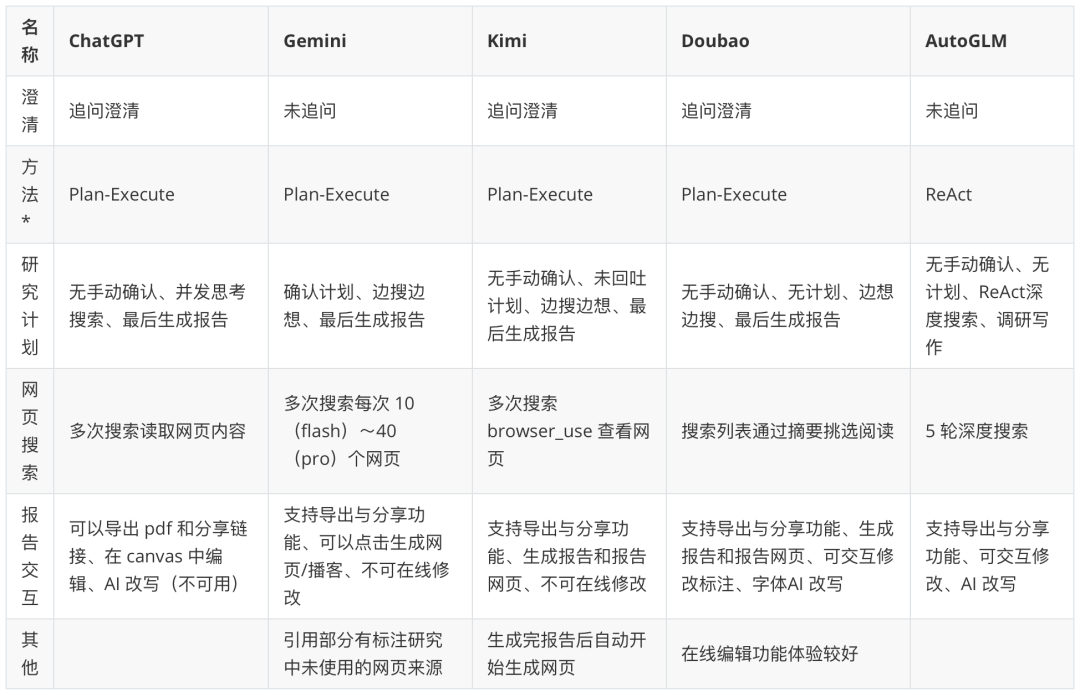
Hinweis: Das "Paradigma des intelligenten Körpers" in der Tabelle ist eine Spekulation auf der Grundlage des Produktverhaltens. Weitere großartige und tiefgreifende Forschungsergebnisse über Intelligenzen: https://www.kdjingpai.com/ai-learning/research-assistant/
Während Open-Source-Frameworks den "Motor" offenlegen, verbergen kommerzielle Produkte den "Motor" elegant unter einem schönen "Cockpit". Zum Beispiel Kimi So können beispielsweise tiefgreifende Forschungsprobleme gelöst werden, ohne dass sich der Benutzer um die Planung, Ausführung und Synthese hinter den Kulissen kümmern muss. Der Nutzer stellt eine komplexe Frage undKimi Automatisiert den internen Rechercheprozess: Planung von Suchbegriffen, gleichzeitiger Zugriff auf mehrere Webquellen, Verdauung und Integration von Informationen in Echtzeit mithilfe des Kontextfensters mit mehreren Millionen Wörtern und schließlich Präsentation einer umfassenden Antwort mit zitierten Quellen in einem flüssigen Dialog.
Andere Produkte wie z.B. ChatGPT、Gemini usw., werden ebenfalls weitergegeben CoT (Gedankenkette),Tree of Thoughts oder intern integrierte Multi-Intelligenz-Prozesse, die ihre Fähigkeit, komplexe Forschungsaufgaben zu erfüllen, kontinuierlich verbessern. Kommerzielle Produkte konkurrieren mit der Genauigkeit und dem Echtzeitcharakter der Suchergebnisse, der Tiefe und dem Einblick in die Informationsintegration und der Interaktivität des Endberichts (z. B. anklickbare Zitate, Erstellung von Diagrammen, Vorschläge für Folgemaßnahmen usw.). Sie nutzen die komplexe Architektur der Open-Source-Welt und verpacken sie in leistungsstarke Funktionen, die für den Durchschnittsnutzer zugänglich sind.




























