



ShareGPT-4o-Image ist ein großer multimodaler Bilderzeugungsdatensatz, der vom FreedomIntelligence-Team auf GitHub zur Verfügung gestellt wird. Er enthält 91K hochwertige Beispiele, die auf den Bilderzeugungsfunktionen von GPT-4o basieren. Der Datensatz ist in 45K Text-zu-Bild-Beispiele und 46K Text-plus-Bild-zu-Bild-Beispiele unterteilt und wurde entwickelt, um das multimodale Open-Source-Modell mit den Bilderzeugungsfähigkeiten von GPT-4o in Einklang zu bringen. Das Team hat auf der Grundlage dieses Datensatzes auch das Modell Janus-4o entwickelt, das Text-zu-Bild- und Bildbearbeitungsfunktionen unterstützt und seinen Vorgänger Janus-Pro übertrifft. Das Projekt hat sich zum Ziel gesetzt, die multimodale KI-Gemeinschaft durch Open-Source-Daten und -Modelle voranzubringen und hochwertige Ressourcen für Forschung und Entwicklung bereitzustellen.
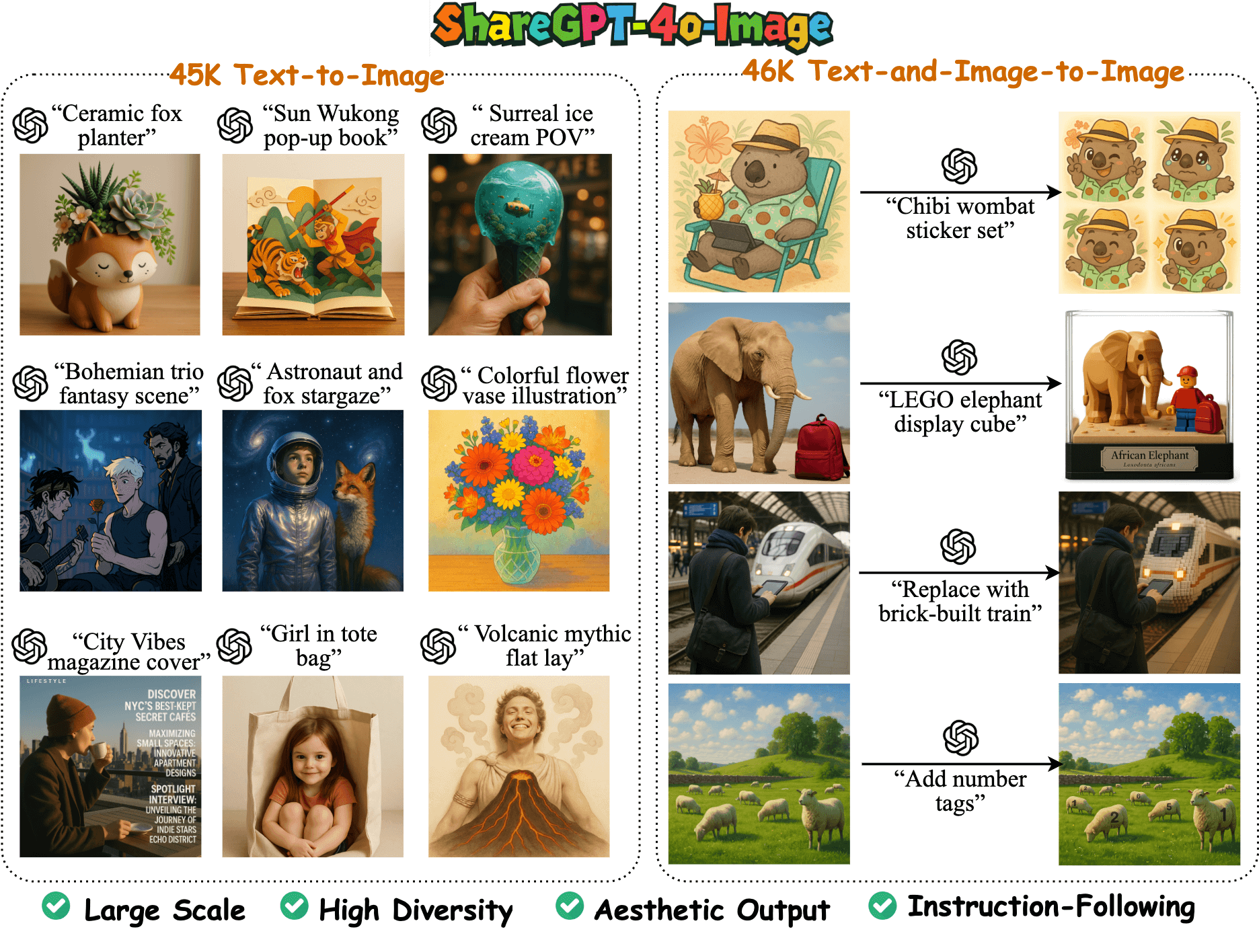
Funktionsliste
- Bietet 91K hochwertige Bilderzeugungsbeispiele, darunter 45K Text-zu-Bild- und 46K Text-plus-Bild-zu-Bild-Beispiele.
- Unterstützt das Training und die Optimierung von multimodalen Open-Source-Modellen zur Verbesserung der Bilderzeugung und -bearbeitung.
- Enthält das Janus-4o-Modell mit Unterstützung für die Text-zu-Bild-Generierung und die Text-plus-Bild-zu-Bild-Bearbeitung.
- Der Datensatz kann auf Hugging Face im Format einer Parquet-Datei heruntergeladen werden, die etwa 20,7 MB groß ist und 92.256 Datenzeilen enthält.
- Ausführliche Dokumentationen und Code-Beispiele unterstützen Entwickler dabei, sich schnell in Datensätze und Modelle einzuarbeiten.
- Der Open-Source-Code und die Modelle werden auf GitHub und Hugging Face gehostet, um der Community die Möglichkeit zu geben, sich einzubringen und zu erweitern.
Hilfe verwenden
Datensatzerfassung und Installation
Der ShareGPT-4o-Image-Datensatz ist frei verfügbar auf Hugging Face oder GitHub. Hier sind die genauen Schritte:
- Zugang zu Datensätzen:
- Öffnen Sie die Seite "Hugging Face": https://huggingface.co/datasets/FreedomIntelligence/ShareGPT-4o-Image.
- Oder besuchen Sie das GitHub-Repository unter https://github.com/FreedomIntelligence/ShareGPT-4o-Image.
- Der Datensatz ist im Parquet-Format gespeichert und hat eine Größe von ca. 20,7 MB und enthält 92.256 Datenzeilen.
- Datensatz herunterladen:
- Klicken Sie auf der Seite Hugging Face auf die Schaltfläche "Download", um die Parkettdatei direkt herunterzuladen.
- Oder verwenden Sie den Git-Befehl, um Ihr GitHub-Repository zu klonen:
git clone https://github.com/FreedomIntelligence/ShareGPT-4o-Image.git - Nach dem Herunterladen entpacken Sie die Datei (falls erforderlich) und stellen Sie sicher, dass die Parquet-Datei von der Python-Umgebung gelesen werden kann.
- Vorbereitung der Umwelt:
- Installieren Sie Python 3.7 oder höher.
- Installieren Sie die erforderlichen Abhängigkeits-Bibliotheken, z. B.
pandas和datasetszum Laden und Verarbeiten von Parquet-Dateien:pip install pandas datasets - Wenn Sie das Modell Janus-4o verwenden, müssen Sie die
torch和transformers:pip install torch transformers
- Laden von Datensätzen:
- Mit Pythons
datasetsDie Bibliothek lädt den Datensatz:from datasets import load_dataset dataset = load_dataset("FreedomIntelligence/ShareGPT-4o-Image") print(dataset) - Der Datensatz enthält Korrespondenzen zwischen textlichen Hinweisen und generierten Bildern, die direkt für das Modelltraining oder die Analyse verwendet werden können.
- Mit Pythons
Verwendung des Janus-4o-Modells
Janus-4o ist ein fein abgestimmtes multimodales Modell, das auf dem ShareGPT-4o-Image-Datensatz basiert und Text-zu-Bild-Generierung und Bildbearbeitung unterstützt. Im Folgenden werden die einzelnen Schritte beschrieben:
- Modelle laden:
- Laden Sie das Modell Janus-4o-7B von Hugging Face herunter:
from transformers import AutoModelForCausalLM, VLChatProcessor model_path = "FreedomIntelligence/Janus-4o-7B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained( model_path, trust_remote_code=True, torch_dtype=torch.bfloat16 ).cuda().eval() - Vergewissern Sie sich, dass Ihr Gerät GPUs unterstützt und CUDA installiert hat, andernfalls verwenden Sie eine CPU (geringere Leistung). [](https://huggingface.co/FreedomIntelligence/Janus-4o-7B)
- Laden Sie das Modell Janus-4o-7B von Hugging Face herunter:
- Text-zu-Bild-Generierung:
- Verwenden Sie das mitgelieferte
text_to_image_generateFunktion erzeugt das Bild:def text_to_image_generate(input_prompt, output_path, vl_chat_processor, vl_gpt, temperature=1.0, parallel_size=2, cfg_weight=5): torch.cuda.empty_cache() conversation = [{"role": "<|User|>", "content": input_prompt}, {"role": "<|Assistant|>", "content": ""}] sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts( conversations=conversation, sft_format=vl_chat_processor.sft_format, system_prompt="" ) prompt = sft_format + vl_chat_processor.image_start_tag # 后续生成步骤参考 GitHub 文档 - Geben Sie Beispiele ein, z. B. "Ein Bild von einem Strand bei Sonnenuntergang mit Kokospalmen im Sand und einem Segelboot in der Ferne".
- Das erzeugte Bild wird in dem angegebenen
output_path。
- Verwenden Sie das mitgelieferte
- Text und Bild-zu-Bild-Bearbeitung:
- Janus-4o unterstützt die Bildbearbeitung auf der Basis von Eingabebildern und Textaufforderungen. Geben Sie zum Beispiel ein Landschaftsbild ein und die Aufforderung "Ersetze Himmel durch Sterne".
- Der Prozess ist ähnlich wie bei Text-zu-Bild, aber Sie müssen einen zusätzlichen Bildpfad angeben. Beispiele finden Sie im GitHub-Repository.
- Dokument anzeigen:
- In der README-Datei im GitHub-Repository finden Sie detaillierte Modellparameter und Anweisungen zur Erstellung des Setups.
- Die Seite "Hugging Face" bietet auch eine Vorschau auf die Struktur des Datensatzes und Beispiele zum besseren Verständnis des Datenformats.
caveat
- Die Datensätze und Modelle erfordern eine stabile Internetumgebung zum Herunterladen.
- Beschleunigte Modellinferenz unter Verwendung der GPU, mindestens 16 GB Grafikspeicher werden empfohlen.
- Wenn Sie Probleme beim Laden oder Generieren von Modellen haben, können Sie auf der GitHub Issues-Seite nachsehen oder Feedback zu dem Problem senden.
- Der Datensatz und das Modell sind quelloffen, und die Gemeinschaft ermutigt dazu, Code oder Verbesserungen für den Datensatz beizusteuern.
Anwendungsszenario
- Entwicklung multimodaler Modelle
Entwickler können den ShareGPT-4o-Image-Datensatz verwenden, um ihre eigenen multimodalen Modelle zu trainieren oder zu verfeinern, um die Text-zu-Bild-Generierung oder die Bildbearbeitung für Szenarien wie die Erstellung von Kunstwerken, Design-Skizzen und mehr zu verbessern. - akademische Forschung
Forscher können den Datensatz nutzen, um die Bilderzeugungsmuster von GPT-4o zu analysieren und die semantische Ausrichtung und Erzeugungsqualität des multimodalen Modells zu untersuchen, das sich für die akademische Forschung im Bereich der künstlichen Intelligenz und des Computerbildes eignet. - Kreative Inhaltserstellung
Designer oder Inhaltsersteller können Janus-4o-Modelle verwenden, um schnell hochwertige Bilder auf der Grundlage von Textbeschreibungen zu generieren oder um bestehende Bilder für Anwendungen in der Werbung, bei Spielen oder in der Filmproduktion stilistisch zu bearbeiten. - Bildung und Unterricht
Lehrer und Schüler können die Datensätze und Modelle nutzen, um mit KI-Lektionen zu experimentieren, zu lernen, wie multimodale Modelle funktionieren, und Aufgaben zur Text-zu-Bild-Erstellung und Bildbearbeitung zu üben.
QA
- Ist der ShareGPT-4o-Image-Datensatz kostenlos?
Ja, der Datensatz ist vollständig quelloffen und kann unter der Apache-2.0-Lizenz bei Hugging Face und GitHub frei heruntergeladen und verwendet werden. - Wie schneidet das Modell Janus-4o im Vergleich zu GPT-4o ab?
Janus-4o ist ein Open-Source-Modell, das auf der Grundlage des ShareGPT-4o-Image-Datensatzes feinabgestimmt wurde und die Text-zu-Bild- und Bildbearbeitung unterstützt, aber in der Gesamtleistung GPT-4o noch leicht unterlegen ist. - Welche Hardware wird für den Betrieb von Janus-4o benötigt?
CUDA-fähige Grafikprozessoren (mindestens 16 GB RAM) werden für die beste Leistung empfohlen, CPUs können es zwar ausführen, aber mit geringerer Geschwindigkeit. - Wie kann ich zu dem Projekt beitragen?
Im GitHub-Repository können Pull Requests eingereicht werden, um Code beizusteuern, Modelle zu optimieren oder Datensätze zu ergänzen, wie in den Beitragsrichtlinien des Repositorys beschrieben.































