


Die Vektoreinbettung ist das Herzstück der aktuellen Retrieval Augmented Generation (RAG) Anwendungen. Sie erfassen semantische Informationen über Datenobjekte (z. B. Text, Bilder usw.) und stellen sie als Zahlenreihen dar. In aktuellen generativen KI-Anwendungen werden diese Vektor-Embedding in der Regel durch Embedding-Modelle erzeugt. Wie wählt man das richtige Einbettungsmodell für eine RAG-Anwendung? Insgesamt hängt dies vom spezifischen Anwendungsfall und den spezifischen Anforderungen ab. Als Nächstes werden wir die einzelnen Schritte aufschlüsseln, um jedes Modell einzeln zu betrachten.
01. spezifische Anwendungsfälle identifizieren
Wir betrachten die folgenden Fragen auf der Grundlage der RAG-Anwendungsanforderungen:
Erstens: Reicht ein allgemeines Modell aus, um den Bedarf zu decken?
Zweitens: Gibt es besondere Anforderungen? Zum Beispiel Modalität (z. B. nur Text oder Bild, für multimodale Einbettungsoptionen siehe dieWie man das richtige Einbettungsmodell wählt"), bestimmte Bereiche (z. B. Recht, Medizin usw.)
In den meisten Fällen wird ein allgemeines Modell für die gewünschten Modi gewählt.
02. die Auswahl der generischen Modelle
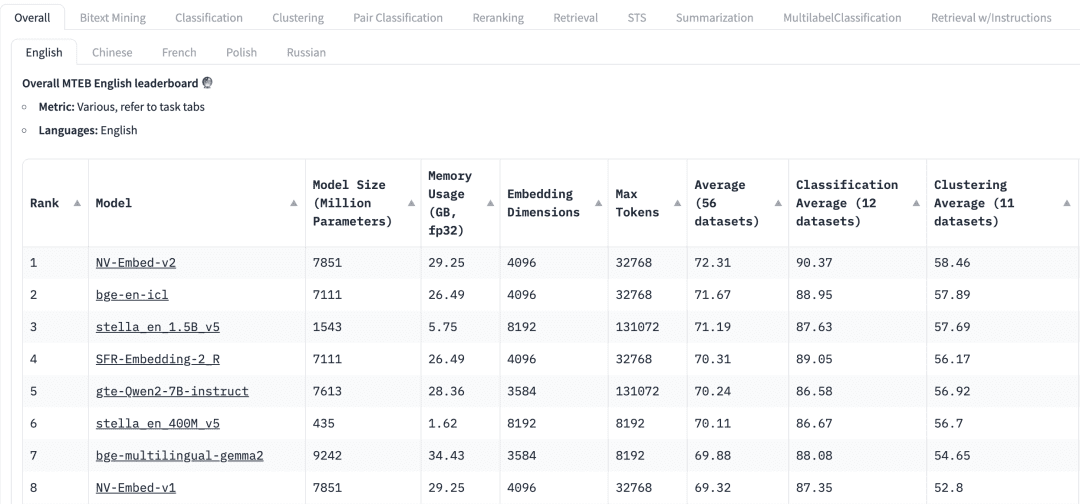
Der Massive Text Embedding Benchmark (MTEB) in HuggingFace listet eine Vielzahl aktueller proprietärer und quelloffener Texteinbettungsmodelle auf, und für jedes Einbettungsmodell listet der MTEB eine Reihe von Metriken auf, darunter Modellparameter, Speicher, Einbettungsdimensionen, maximale Anzahl von Token und ihre Ergebnisse bei Aufgaben wie Retrieval und Zusammenfassung.
Die folgenden Faktoren müssen bei der Auswahl eines Einbettungsmodells für eine RAG-Anwendung berücksichtigt werden:
MandateOben auf dem MTEB-Leaderboard sehen wir verschiedene Registerkarten für Aufgaben. Für eine RAG-Anwendung müssen wir uns vielleicht mehr auf die Aufgabe "Abrufen" konzentrieren, wo wir wählen können Retrial Diese Registerkarte.
MehrsprachigkeitRAG: Basierend auf der Sprache des Datensatzes, in dem die RAG angewendet wird, um das Einbettungsmodell für die entsprechende Sprache auszuwählen.
ErgebnisBenchmark: Gibt die Leistung des Modells bei einem bestimmten Benchmark-Datensatz oder mehreren Benchmark-Datensätzen an. Je nach Aufgabe werden unterschiedliche Bewertungsmetriken verwendet. In der Regel nehmen diese Metriken Werte zwischen 0 und 1 an, wobei höhere Werte eine bessere Leistung anzeigen.
Modellgröße und SpeichernutzungDiese Metriken geben uns eine Vorstellung von den für die Ausführung des Modells erforderlichen Rechenressourcen. Während sich die Abrufleistung mit der Modellgröße verbessert, ist es wichtig zu beachten, dass die Modellgröße sich auch direkt auf die Latenzzeit auswirkt. Darüber hinaus können größere Modelle überangepasst sein und eine geringe Generalisierungsleistung aufweisen, so dass sie in der Produktion schlecht abschneiden. Daher müssen wir ein Gleichgewicht zwischen Leistung und Latenzzeit in einer Produktionsumgebung finden. Im Allgemeinen können wir mit einem kleinen, leichtgewichtigen Modell beginnen und die RAG-Anwendung zunächst schnell aufbauen. Nachdem der der Anwendung zugrunde liegende Prozess ordnungsgemäß funktioniert, können wir zu einem größeren, leistungsfähigeren Modell wechseln, um die Anwendung weiter zu optimieren.
Dimensionen einbettenLänge des Einbettungsvektors: Dies ist die Länge des Einbettungsvektors. Während größere Einbettungsdimensionen feinere Details in den Daten erfassen können, sind die Ergebnisse nicht unbedingt optimal. Brauchen wir zum Beispiel wirklich 8192 Dimensionen für Dokumentendaten? Wahrscheinlich nicht. Andererseits ermöglichen kleinere Einbettungsdimensionen eine schnellere Inferenz und sind effizienter in Bezug auf die Speicherung und den Speicherplatz. Daher müssen wir ein gutes Gleichgewicht zwischen der Erfassung des Dateninhalts und der Ausführungseffizienz finden.
Maximale Anzahl von Token: gibt die maximale Anzahl von Token für ein einzelnes Embedding an. Für gewöhnliche RAG-Anwendungen ist die beste Größe für ein Embedding normalerweise ein einzelner Absatz. In diesem Fall sollte ein Embedding-Modell mit einer maximalen Token-Anzahl von 512 ausreichend sein. In einigen speziellen Fällen können wir jedoch Modelle mit einer größeren Anzahl von Token benötigen, um längere Texte zu verarbeiten.
03. die Bewertung von Modellen in RAG-Anwendungen
Wir können zwar generische Modelle in den MTEB-Ranglisten finden, aber wir müssen ihre Ergebnisse mit Vorsicht behandeln. Wenn man bedenkt, dass diese Ergebnisse von den Modellen selbst angegeben werden, ist es möglich, dass einige Modelle ihre Leistung aufblähen, weil sie möglicherweise die MTEB-Datensätze in ihre Trainingsdaten aufgenommen haben, die ja öffentlich zugänglich sind. Auch die Datensätze, die die Modelle zum Benchmarking verwenden, repräsentieren möglicherweise nicht genau die Daten, die in unserer Anwendung verwendet werden. Daher müssen wir die Embedding-Modelle anhand unserer eigenen Datensätze bewerten.
3.1 Datensätze
Wir können aus den von der RAG-Anwendung verwendeten Daten einen kleinen getaggten Datensatz erzeugen. Nehmen wir den folgenden Datensatz als Beispiel.
| Language | Description |
|---|---|
| C/C++ | A general-purpose programming language known for its performance and efficiency. It provides low-level memory manipulation capabilities and is widely used in system/software development, game development, and applications requiring high performance. |
| Java | A versatile, object-oriented programming language designed to have as few implementation dependencies as possible. It is widely used for building enterprise-scale applications, mobile applications (especially Android), and web applications due to its portability and robustness. |
| Python | A high-level, interpreted programming language known for its readability and simplicity. It supports multiple programming paradigms and is widely used in web development, data analysis, artificial intelligence, scientific computing, and automation. |
| JavaScript | A high-level, dynamic programming language primarily used for creating interactive and dynamic content on the web. It is an essential technology for front-end web development and is increasingly used on the server-side with environments like Node.js. |
| C# | A modern, object-oriented programming language developed by Microsoft. It is used for developing a wide range of applications, including web, desktop, mobile, and games, particularly within the Microsoft ecosystem. |
| SQL | A domain-specific language used in programming and managing relational databases. It is essential for querying, updating, and managing data in databases, and is widely used in data analysis and business intelligence. |
| PHP | A server-side scripting language designed primarily for web development. It is embedded into HTML and is widely used for building dynamic web pages and applications, with a strong presence in content management systems like WordPress. |
| Golang | A statically typed, compiled programming language designed by Google. Known for its simplicity and efficiency, it is used for building scalable and high-performance applications, particularly in cloud services and distributed systems. |
| Rust | A systems programming language focused on safety and concurrency. It provides memory safety without using a garbage collector and is used for building reliable and efficient software, particularly in systems programming and web assembly. |
3.2 Einbettung erstellen
Als nächstes verwenden wir diepymilvus[model]Für den obigen Datensatz wird der entsprechende Vektor Embedding erzeugt. über die pymilvus[model] Für die Verwendung, siehe https://milvus.io/blog/introducing-pymilvus-integrations-with-embedding-models.md
def gen_embedding(model_name): openai_ef = model.dense.OpenAIEmbeddingFunction( model_name=model_name, api_key=os.environ["OPENAI_API_KEY"] ) docs_embeddings = openai_ef.encode_documents(df['description'].tolist()) return docs_embeddings, openai_ef
Anschließend wird die erzeugte Einbettung in der Sammlung von Milvus hinterlegt.
def save_embedding(docs_embeddings, collection_name, dim):
data = [
{"id": i, "vector": docs_embeddings[i].data, "text": row.language}
for i, row in df.iterrows()
]
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(collection_name=collection_name, dimension=dim)
res = milvus_client.insert(collection_name=collection_name, data=data)
3.3 Abfragen
Wir definieren Abfragefunktionen, um den Abruf der Vektoreinbettung zu erleichtern.
def query_results(query, collection_name, openai_ef):
query_embeddings = openai_ef.encode_queries(query)
res = milvus_client.search(
collection_name=collection_name,
data=query_embeddings,
limit=4,
output_fields=["text"],
)
result = {}
for items in res:
for item in items:
result[item.get("entity").get("text")] = item.get('distance')
return result
3.4 Bewertung der Leistung des Einbettungsmodells
Wir verwenden zwei Embedding-Modelle von OpenAI.text-embedding-3-small 和 text-embedding-3-largefür die folgenden zwei Abfragen verglichen werden. Es gibt viele Bewertungsmetriken wie Genauigkeit, Wiederaufruf, MRR, MAP, usw. Hier verwenden wir Genauigkeit und Wiederaufruf.
Präzision Bewertet den Prozentsatz der wirklich relevanten Inhalte in den Suchergebnissen, d. h. wie viele der zurückgegebenen Ergebnisse für die Suchanfrage relevant sind.
Precision = TP / (TP + FP)
In diesem Fall sind die "True Positives" (TP) diejenigen, die wirklich relevant für die Suchanfrage sind, während die "False Positives" (FP) sich auf diejenigen beziehen, die in den Suchergebnissen nicht relevant sind.
Der Rückruf bewertet die Anzahl der relevanten Inhalte, die erfolgreich aus dem gesamten Datensatz abgerufen wurden.
Recall = TP / (TP + FN)
Falsche Negative (FN) beziehen sich auf alle relevanten Elemente, die nicht in der endgültigen Ergebnismenge enthalten sind.
Eine genauere Erläuterung dieser beiden Konzepte finden Sie unter
Anfrage 1:auto garbage collection
Verwandte Themen: Java, Python, JavaScript, Golang
| Rank | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ❎ Rost | ❎ Rost |
| 2 | ❎ C/C++ | ❎ C/C++ |
| 3 | ✅ Golang | ✅ Java |
| 4 | ✅ Java | ✅ Golang |
| Precision | 0.50 | 0.50 |
| Recall | 0.50 | 0.50 |
Anfrage 2:suite for web backend server development
Verwandte Themen: Java, JavaScript, PHP, Python (Antworten beinhalten subjektive Beurteilung)
| Rank | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ✅ PHP | ✅ JavaScript |
| 2 | ✅ Java | ✅ Java |
| 3 | ✅ JavaScript | ✅ PHP |
| 4 | ❎ C# | ✅Python |
| Precision | 0.75 | 1.0 |
| Recall | 0.75 | 1.0 |
Bei diesen beiden Abfragen haben wir die beiden Einbettungsmodelle anhand der Genauigkeit und der Wiedererkennung verglichen text-embedding-3-small 和 text-embedding-3-large Das Embedding-Modell kann als Ausgangspunkt verwendet werden. Wir können dies als Ausgangspunkt nutzen, um die Anzahl der Datenobjekte im Datensatz sowie die Anzahl der Abfragen zu erhöhen, damit das Embedding-Modell effektiver evaluiert werden kann.
04. Zusammenfassung
Bei Retrieval Augmented Generation (RAG)-Anwendungen ist die Auswahl geeigneter Vektoreinbettungsmodelle entscheidend. In diesem Beitrag wird gezeigt, dass nach der Auswahl eines generischen Modells aus MTEB anhand der tatsächlichen Geschäftsanforderungen die Genauigkeit und der Abruf zum Testen des Modells auf der Grundlage eines geschäftsspezifischen Datensatzes verwendet werden, um das am besten geeignete Einbettungsmodell auszuwählen, was wiederum die Abrufgenauigkeit der RAG-Anwendung effektiv verbessert.
Der vollständige Code ist als Download verfügbar







































