

Viele Nutzer laden wichtige Daten (wie einfache Bilddateien oder gescannte PDF-Dokumente) auf die LLM-Anwendungsentwicklungsplattform hoch. Dify Ein kniffliges Problem tritt häufig auf, wenn die Wissensbasis desDify Es ist nicht möglich, diese Nicht-Text-Formate direkt zu lesen und zu parsen. Dies ist hauptsächlich auf die Dify Die nativen Funktionen der Wissensdatenbank sind eher auf die Verarbeitung und das Verständnis von reinen Textdaten ausgerichtet. Um diese Einschränkung zu überwinden, ist es möglich, Folgendes einzuführen MinerU-API Instrument zur Ermächtigung Dify Knowledge Base die leistungsstarken OCR-Funktionen (Optical Character Recognition). Anschließend wird erläutert, wie ein Arbeitsablauf aufgebaut wird, der die Dify Die Knowledge Base ist in der Lage, Textinformationen in Bildern und gescannten Dokumenten effizient zu analysieren. Dieses Lernprogramm basiert auf dem Dify Version 1.3.1.
vorläufige Vorbereitung
Es gibt zwei wichtige Vorbereitungen, die abgeschlossen werden müssen, bevor Sie mit der Erstellung eines Workflows beginnen können: die Bereitstellung der MinerU-API Dienstleistung und Kreation Dify Wissensbasis.
Einsatz der MinerU-API
MinerU-API ist ein Werkzeug, das das Parsen von Dokumenten in mehreren Formaten (einschließlich OCR) unterstützt. Eine ausführliche Einführung und die Schritte, um den Code zu erhalten, finden Sie in den beiden verwandten Artikeln "Extracting PDF with MinerU in Dify" und "MinerU-API | Supporting Multi-Format Parsing to Further Enhance Dify's Document Capabilities". Dies setzt voraus, dass der Benutzer Folgendes erhalten hat MinerU-API Code und beschreiben Sie kurz dessen Docker Einsatzbefehle.
docker run -d --gpus all --network docker_ssrf_proxy_network --name mineru-api -v minerupaddleocr:/root/.paddleocr mineru-api:v0.3
Dieser Befehl startet im Hintergrund einen Befehl namens mineru-api 的 Docker Container und weist GPU-Ressourcen (falls verfügbar) zu, während er mit dem angegebenen Netzwerk verbunden und ein Datenvolumen für persistente PaddleOCR der relevanten Daten.
Erstellen einer Dify Wissensdatenbank
Erstens, in Dify Eine neue Wissensbasis wird in der Plattform erstellt. Der Erstellungsprozess umfasst die Einrichtung des zugrundeliegenden Einbettungsmodells, das für die Umwandlung von Textdaten in hochdimensionale Vektoren für das semantische Verständnis und die Ähnlichkeitsberechnung durch die Maschine verantwortlich ist, sowie des Rerank-Modells, das für die Neueinstufung der ursprünglichen Suchergebnisse verwendet wird, um die Genauigkeit und Relevanz der endgültigen Antworten zu verbessern.

Abbildung 1: Dify Wissensdatenbank erstellen Schnittstelle
Sobald die Wissensdatenbank erstellt wurde, öffnen Sie die Wissensdatenbank mit der BrowserfunktionAdressleisteDiese ID ist ein wichtiger Parameter für nachfolgende API-Aufrufe.

Abbildung 2: Abrufen der Wissensdatenbank-ID aus der Adressleiste des Browsers
Navigieren Sie dann zuWissensdatenbank -> API Einstellungen, um einen neuen API-Schlüssel zu erzeugen. Dieser Schlüssel wird verwendet, um die verschiedenen Operationen zu autorisieren, die der Workflow in der Wissensdatenbank durchführt.
Abbildung 3: Schnittstelle zum Generieren von Wissensdatenbank-API-Schlüsseln
Aufbau von MinerU Knowledge Base Workflows
Workflow-Übersicht
Der konstruierte Arbeitsablauf besteht aus drei wichtigen Code-Ausführungsknoten, die zusammenarbeiten, um Bilder oder gescannte Dokumente zu analysieren und zu bibliothekieren.
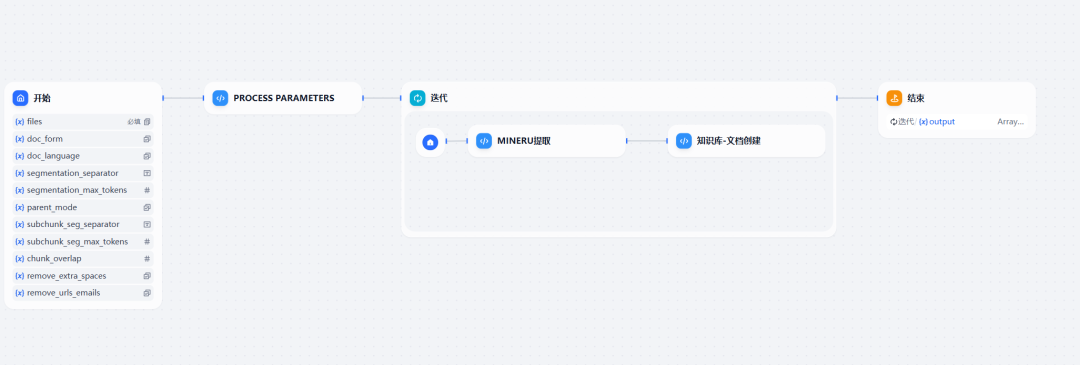
Abbildung 4: Überblick über den MinerU Knowledge Base Workflow
Die Funktionen der drei Codeblöcke sind wie folgt:
- Process ParametersDieser Knoten ist hauptsächlich für die Bearbeitung von Aufrufen an
DifyErstellen Sie eine Dokumentschnittstelle (/datasets/{dataset_id}/document/create-by-text), wenn die erforderlichen Parameter. - MinerU-ExtraktionDie Hauptaufgabe dieses Knotens ist der Aufruf von
MinerU-APIEin Dienst, der eingehende PDF- oder Bilddateien mithilfe von OCR-Technologie in einfache Textinhalte im Markdown-Format umwandelt. - Wissensdatenbank - DokumentenerstellungDieser Knoten wird durch den Aufruf der Funktion
DifyFlachdach/datasets/{dataset_id}/document/create-by-textAPI-Schnittstelle, die im vorherigen Schritt durch dieMinerUDer extrahierte Textinhalt wird als neues Dokument in der Wissensdatenbank erstellt. Im Folgenden finden Sie ein Beispiel für Python-Code für diesen Knoten:
import requests
def main(api_key, file_name, content, api_params, dataset_id):
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json',
}
# 更新API参数,加入文件名和提取的文本内容
api_params.update({
"name": file_name,
"text": content,
})
# 构建Dify API的请求URL
# 注意:实际部署时,'http://api:5001' 可能需要根据Dify服务的实际地址和端口进行调整
url = f'http://api:5001/v1/datasets/{dataset_id}/document/create-by-text'
response = requests.post(
url,
headers=headers,
json=api_params,
)
return {"result": response.text}
Effektivitätstest
Um die Effektivität des Arbeitsablaufs zu überprüfen, nehmen Sie als Beispiel ein PDF-Dokument, das direkt von einer Webseite gedruckt wird, und vergleichen Sie es mit einem PDF-Dokument, das direkt in das Dify Die Wissensbasis ist die gleiche wie die Wissensbasis, die durch die neu erstellte MinerU Effektivität der Workflow-Bearbeitung.
Die Auswirkungen des direkten Hochladens einer Wissensdatenbank:
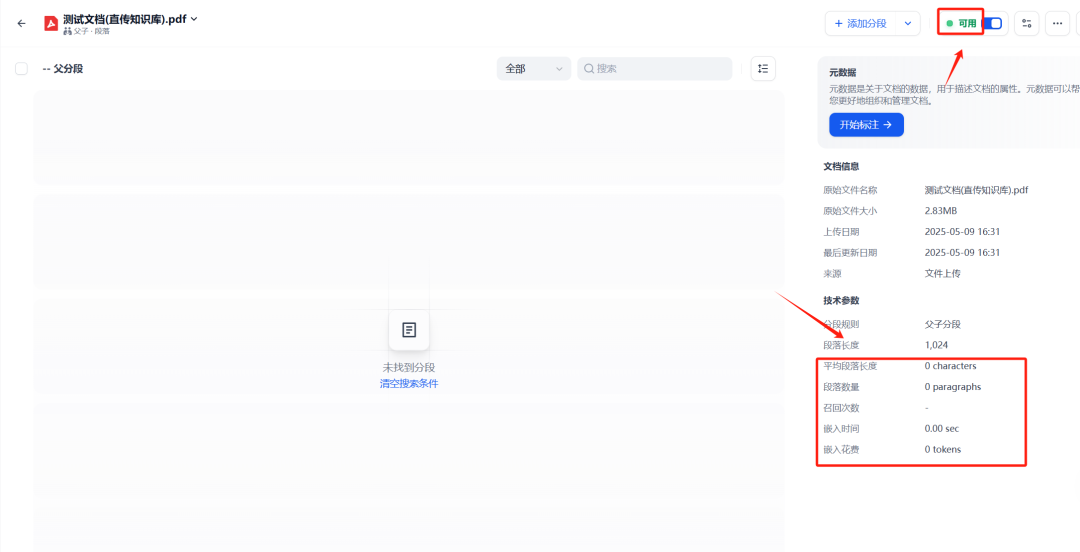
Abbildung 5: Direktes Hochladen von PDF-Dokumenten in die Dify-Wissensdatenbank nach dem Stand der
Wie Sie in der obigen Abbildung sehen können, wurde das Dokument zwar erfolgreich hochgeladen, die Dify Die nativen Funktionen der Wissensdatenbank waren nicht in der Lage, den Text in der gescannten PDF-Datei zu analysieren, so dass das Dokument in der Wissensdatenbank praktisch leer blieb.
Der Effekt der Erstellung eines Dokuments durch einen MinerU-Workflow:
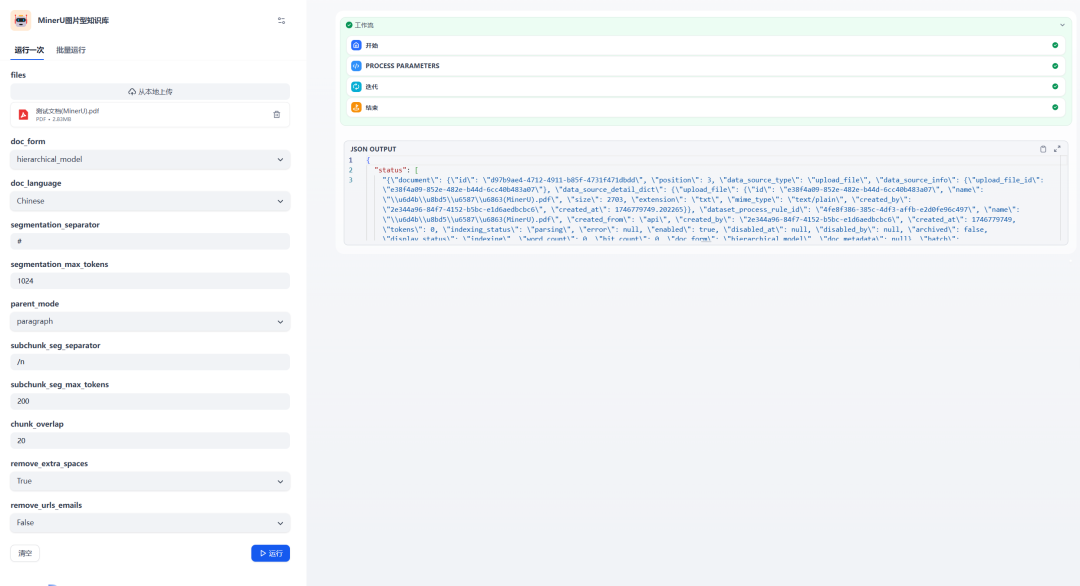
Abbildung 6: Ausführungsergebnisse der Verarbeitung und Erstellung von Dokumenten durch den MinerU-Workflow
Die obige Grafik zeigt, dassMinerU Der Workflow wurde erfolgreich ausgeführt und der Schnittstellenaufruf lieferte ein erfolgreiches Ergebnis. Nun können Sie das neu erstellte Dokument in der Knowledge Base einsehen.
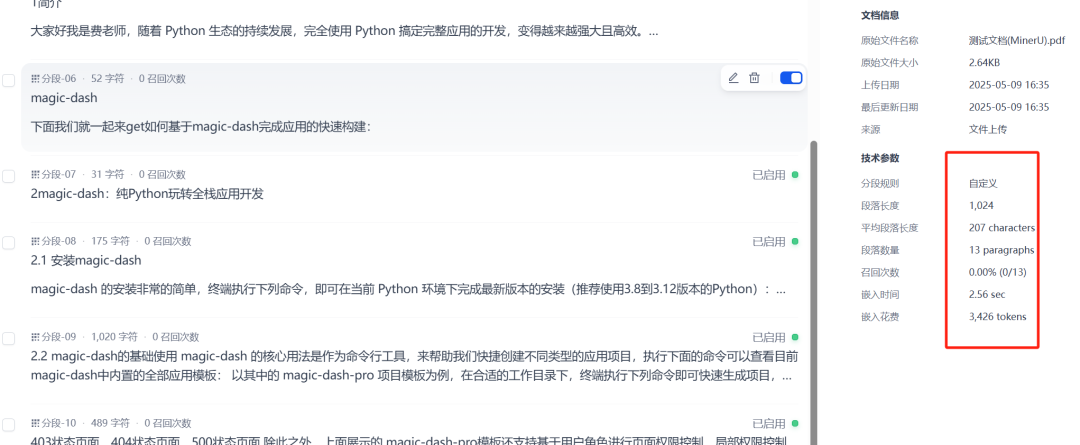
Abbildung 7: Anzeige eines durch einen MinerU-Workflow erstellten Dokuments in der Dify Knowledge Base
Nachdem ein Dokument durch einen Arbeitsablauf erstellt und in die Wissensdatenbank importiert wurde, wird dasDify Sie werden automatisch für die Indizierung verarbeitet. Nachdem die Indizierung abgeschlossen ist, kann ein Abruftest durchgeführt werden, um zu prüfen, ob die Wissensdatenbank in der Lage ist, auf der Grundlage des Textinhalts der Bilder wirksame Fragen und Antworten zu stellen oder Informationen abzurufen.
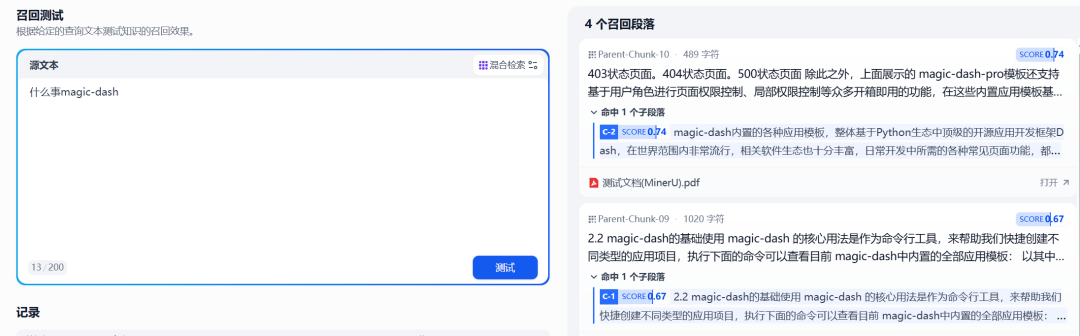
Abbildung 8: Recall-Test für von MinerU verarbeitete und gelagerte Dokumente
Die Testergebnisse zeigen, dass durch MinerU Workflow-verarbeitete Dokumente, die Textinhalte enthalten, die erfolgreich extrahiert und indiziert wurden, so dass die Dify Die Wissensbasis ist in der Lage, Fragen zu verstehen und zu beantworten, die auf diesen ursprünglich gestellten Fragen nach Bildformatinformationen basieren. Dies verbessert erheblich die Dify Die Fähigkeit der Wissensdatenbank, verschiedene Dokumenttypen zu verarbeiten.

































