

Bei der Erstellung von Wissensbasisanwendungen auf der Grundlage von Retrieval Augmented Generation (RAG) ist die Vorverarbeitung und Zerlegung von Dokumenten (Chunking) ein entscheidender Schritt bei der Ermittlung der endgültigen Suchergebnisse. Offene Quelle RAG Motor (Lehnwort) RAGFlow Bietet eine Vielzahl von Slicing-Strategien, aber in der offiziellen Dokumentation fehlt es an klaren Erklärungen zu den Details der Methoden und zu speziellen Fällen, was bei Entwicklern für viel Verwirrung sorgt.
Dieser Artikel soll anhand einer Reihe von Benchmark-Tests einen Einblick in die RAGFlow Die Funktionsweise und die wichtigsten Unterschiede zwischen den verschiedenen Slicing-Methoden im Im Mittelpunkt des Tests stehen die folgenden allgemeinen Fragen:
- Wie werden die Inhaltsverzeichnisse der Kapitel eines Dokuments beim Zerschneiden behandelt? Werden sie als separate Blöcke behandelt oder mit dem Fließtext zusammengeführt?
- Wie werden Bilder, die in den Text eingebettet sind, beim Ausschneiden zugewiesen?
MANUAL、BOOK、LAWSWas ist die spezifische Grundlage für das Schneiden im Iso-Slicing-Verfahren?TABLEWie stellt die Methode sicher, dass die Tabellenkopfinformationen für jede Datenzeile erhalten bleiben, wenn die Daten zeilenweise zerlegt werden?QAKann die Methode des AufschneidensTABLEMethoden der Substitution?
RAGFlow Die Slicing-Methoden lassen sich grob in die folgenden Kategorien einteilen:
- Generischer Ansatz (
General)Deckt alle Dateitypen und Slices auf der Grundlage von "Länge + Trennzeichen" ab, was zwar weit verbreitet, aber weniger genau ist. - Methoden zur Strukturierung von Dokumenten (
MANUAL,BOOK,LAWS)Slicing: Schneidet Dokumente mit einer klaren hierarchischen Struktur (z. B. DOCX, PDF) auf der Grundlage ihres Inhaltsverzeichnisses oder bestimmter Tags. - Methoden der Tabellenstrukturierung (
TABLE,QA)Für tabellarische Daten (z. B. XLSX), Verarbeitung nach Zeilen oder bestimmten Spalten. - Szenariospezifische Methoden (
ONE,RESUME,PAPER,PRESENTATION)Entwickelt für spezielle Zwecke wie einzelne Dokumente, Lebensläufe, Aufsätze und Präsentationen.
Diese Analyse konzentriert sich auf die gängigsten und verwirrendsten Methoden der Dokumentenstrukturierung und der Tabellenstrukturierung.
Aufteilung nach Dokumentstruktur: HANDBUCH, BUCH, GESETZE
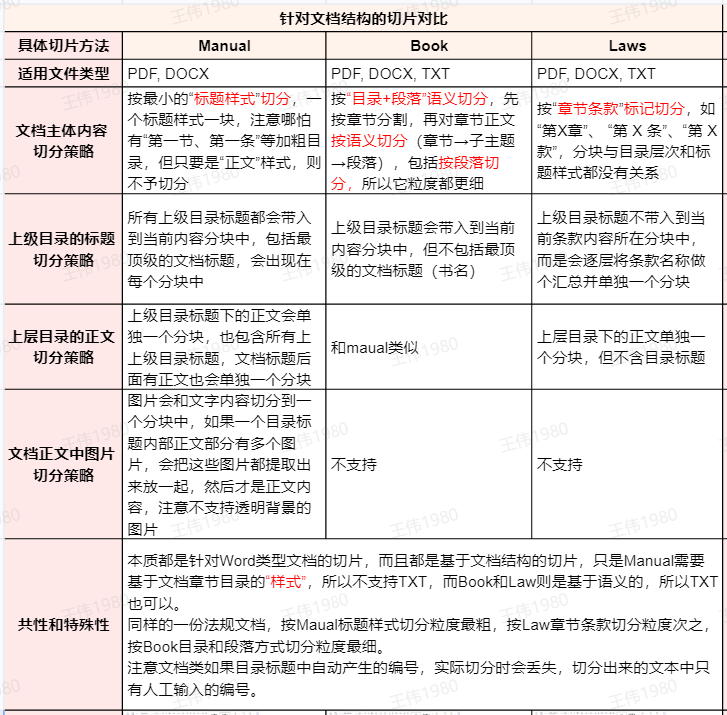
Alle drei Methoden eignen sich für die Verarbeitung strukturierter Dokumente, aber ihre Slicing-Logik und Granularität sind unterschiedlich. Für einen visuellen Vergleich wurde die Datei "Tax Collection and Management Law of the People's Republic of China.docx" als Beispiel gewählt, die eine klare Kapitelstruktur aufweist.
Die Struktur des Originaldokuments wird unten abgefangen:

MANUELLE Methode: basierend auf dem Stil "Titel".
MANUAL Die Methode unterteilt das Dokument streng nach dem in Word oder PDF definierten Überschriftenstil (z. B. Überschrift 1, Überschrift 2). Es wird bis zur feinsten Granularität der Überschriftsebene unterteilt. Es ist zu beachten, dass nur der "Stil" erkannt wird, da die Überschrift des Textes den Schnitt auslöst, normaler fettgedruckter oder vergrößerter Text (wie der Text von "Artikel 15", "Artikel 16 ") wird als Fließtext behandelt.
Testdokumentation Verwendung MANUAL Das Ergebnis der Methode ist unten dargestellt:

Die Ergebnisse der Analyse zeigen, dass das Dokument in insgesamt 6 Teile (Chunks) zerlegt ist. Jeder Chunk erbt alle Titel seiner übergeordneten Verzeichnisse bis zum Stammtitel des Dokuments. Beispielsweise enthält der Inhaltsblock unter "Kapitel 2 Steuerverwaltung" zwei Überschriften, "Steuererhebungs- und Verwaltungsgesetz der Volksrepublik China" und "Kapitel 2 Steuerverwaltung".
Befindet sich unter der Kopfzeile der obersten Ebene ein direkt angehängter Inhalt, wird dieser ebenfalls in einen separaten Block geschnitten.

BUCH-Methodik: basierend auf "Katalog + Absatz"
BOOK Die Methode verwendet eine tiefere semantische Aufteilungsstrategie. Sie unterteilt zunächst das Inhaltsverzeichnis eines Kapitels und dann den Inhalt innerhalb jedes Kapitels nach semantischen Gesichtspunkten (Unterthemen oder Absätze). Dies ermöglicht BOOK Die Granularität der Methode ist die feinste der drei Methoden.
ausnutzen BOOK Methode verarbeitet dasselbe Dokument mit folgenden Ergebnissen:
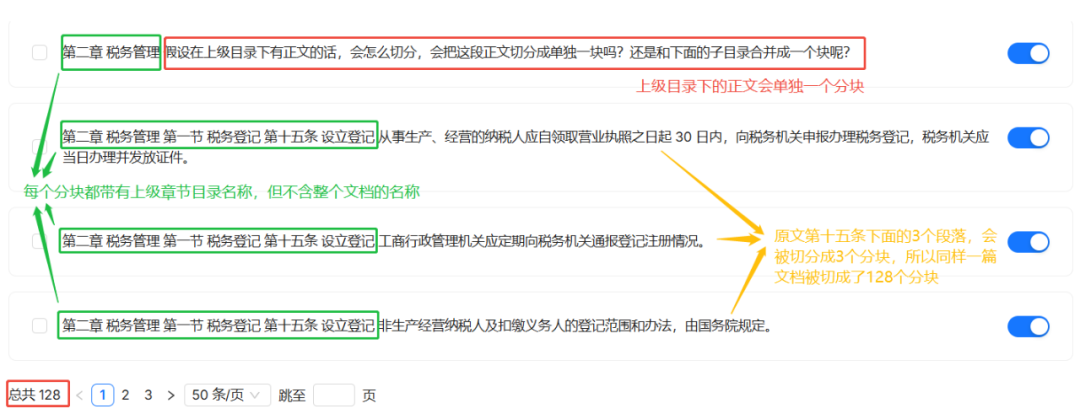
与 MANUAL Der Hauptunterschied zwischen den Methoden besteht darin, dass die drei Absätze unter "Artikel 15" in drei separate Teile zerlegt werden. Das gesamte Dokument wurde schließlich in 128 Abschnitte zerlegt.
Im Kontext der kontextuellen Vererbung ist dieBOOK Jeder Block der Methode enthält ebenfalls den Titel des übergeordneten Verzeichnisses, jedoch auf die gleiche Weise wie die Methode MANUAL Im Gegensatz zu dieser enthält sie nicht die Überschriften der obersten Ebene des Dokuments. Dieses Design ist möglicherweise besser geeignet, um sich bei einer Suche auf den Inhalt eines bestimmten Abschnitts zu konzentrieren, als auf den Kontext des gesamten Dokuments.
LAWS-Methodik: auf der Grundlage der "Abschnittsklausel"-Kennzeichnung
LAWS Methode ist für juristische oder behördliche Dokumente gedacht und verwendet reguläre Ausdrücke, um bestimmte Token wie "Kapitel X", "Artikel X" usw. zu identifizieren und zu zerschneiden, wobei der "Titel"-Stil des Textes oder die Ebene des Inhaltsverzeichnisses des Textes.
ausnutzen LAWS Methode verarbeitet das Dokument und zerlegt das Ergebnis in 87 Teile (Chunks).

LAWS Die Merkmale der Methodik sind wie folgt:
- Kennung:: Obwohl "Artikel 15" und "Artikel 16" im normalen Textstil des Dokuments stehen, werden sie erfolgreich ausgeschnitten, da sie mit der "Artikel"-Auszeichnung übereinstimmen.
- Absatzgestaltung: mit
BOOKAnders.LAWSMehrere Absätze unter den Artikeln werden nicht neu gegliedert, sondern in einem Block zusammengefasst. - Kontextualisierung:
LAWSDie Handhabung des Kontexts ist sehr einzigartig. Anstatt die übergeordneten Katalogrubriken direkt in jeden Artikelblock einzubetten, werden die Katalogrubriken auf jeder Ebene in einem separaten Block zusammengefasst (wie im grünen Drahtgitter in der obigen Abbildung dargestellt), um eine Trennung zwischen Inhalt und Katalogindex zu erreichen.
Zusammenfassung des Vergleichs von drei Methoden zum Aufteilen von Dokumenten
Auf der Grundlage der oben genannten Tests lassen sich die Merkmale der drei Methoden wie folgt zusammenfassen:
Es sollte hinzugefügt werden, dassMANUAL Die Anwendung der Methode ist sehr klar, d.h. Produkthandbücher, technische Dokumente und andere Dokumente mit einer standardmäßigen "Titel"-Stilhierarchie. Und LAWS Spezialisiert auf Gesetze, Verordnungen und politische Dokumente.BOOK Andererseits ist es mit seiner feinkörnigen Segmentierung auf Absatzebene besser für lange Berichte oder Bücher geeignet, die ein tiefes semantisches Verständnis und Fragen und Antworten erfordern.
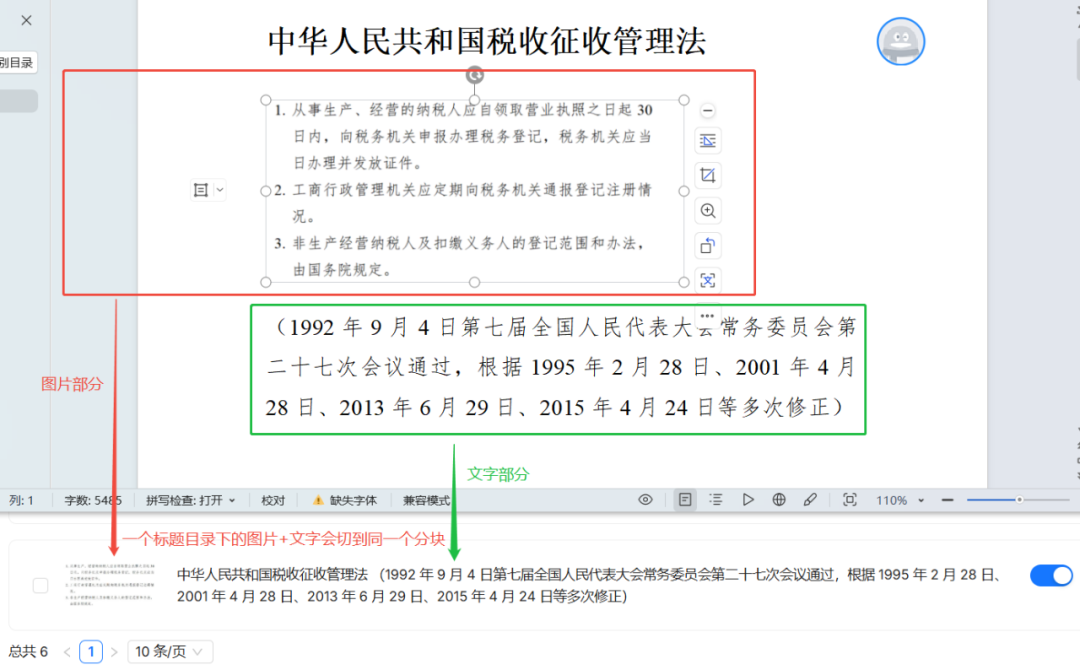
Darüber hinaus ergab der Test, dass MANUAL Methode ist in der Lage, das Bild und den angrenzenden Textinhalt im selben Block zu dokumentieren, was für die Verarbeitung von Grafikdokumenten sehr nützlich ist.
Aufteilung nach Tabellenstruktur: TABLE, QA
Als Nächstes wenden wir uns der Validierung der Slicing-Methode für tabellenartige Daten wie Excel-Dateien zu.
TABELLEN-Methode
Der Test verwendet ein Formular für O&M-Wissen, das Felder für Produkt, Region, Geschäftsfeld, Problembeschreibung, Ursache und Lösung enthält.
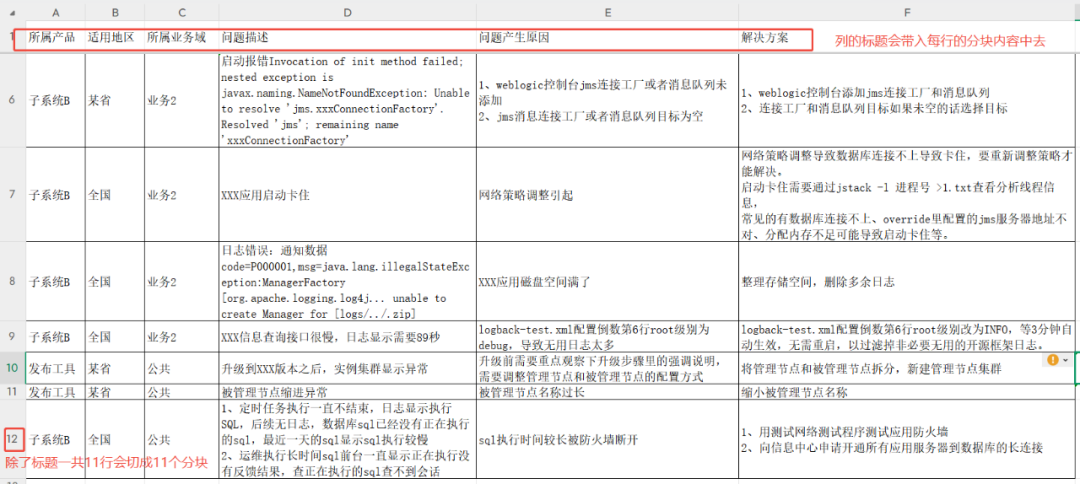
ausnutzen TABLE Beim Schneiden nach der MethodeRAGFlow Die erste Zeile der Tabelle wird als Spaltenüberschrift erkannt. Bei der Verarbeitung werden die Zeilen (mit Ausnahme der Kopfzeilen) durchgeschnitten und die gesamte Information der Spaltenüberschrift in den Inhaltsblock jeder Zeile eingefügt, so dass ein "Schlüssel: Wert"-Format entsteht.
Das Ergebnis der Aufteilung sieht wie folgt aus, wobei jede Zeile ein separates Wissensstück mit vollständigen Kontextinformationen darstellt:

QA-Methodik
QA Die Methode ist eine spezielle Formularscheibe, die die ersten beiden Spalten des Formulars standardmäßig als "Frage" und "Antwort" erkennt. Wenn das vorherige O&M-Wissensformular direkt für die Prüfung verwendet wird.RAGFlow Es werden nur die Spalten "Produkt" und "Region" extrahiert, alle anderen Informationen werden ignoriert.
Für genaue Tests erstellen wir ein Standardformular im QA-Format mit nur zwei Spalten, "Problembeschreibung" und "Lösung".
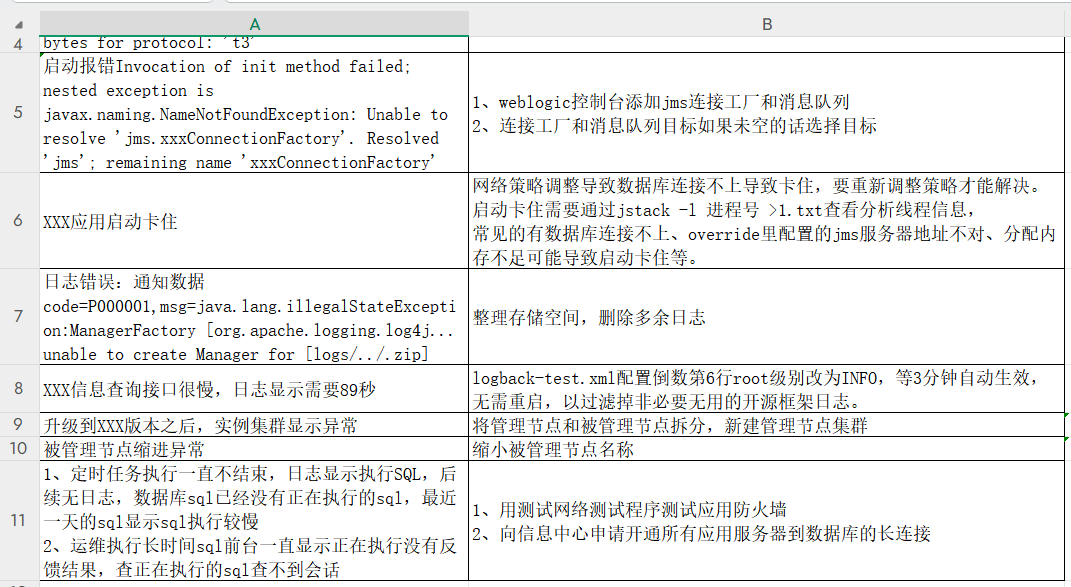
durchlaufen QA Nachdem die Methode zerlegt wurde, wird jede Zeile ebenfalls in einen Block zerlegt und automatisch mit "Frage:" und "Antwort:" eingeleitet.
Zusammenfassung des Vergleichs von zwei Methoden zum Schneiden von Tabellen
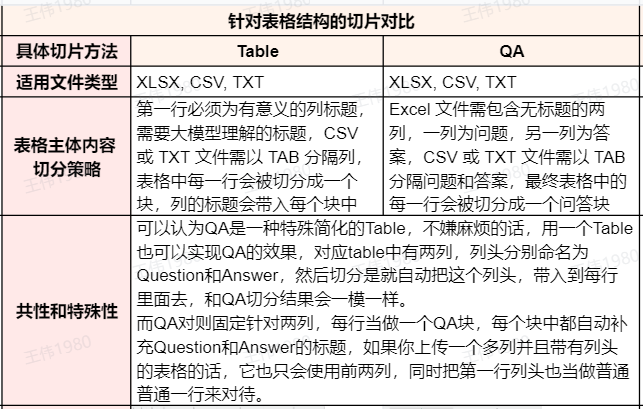
Eine genauere Analyse zeigt, dassQA Die Methoden sind im Wesentlichen TABLE Ein vereinfachter Spezialfall der Methode. Es steht dem Benutzer völlig frei, die TABLE Methodenimplementierung QA Der Effekt der Tabelle besteht einfach darin, dass die beiden Spalten "Frage" und "Antwort" genannt werden.
In praktischen Anwendungen, wenn eine Wissensbasis semantische Abfragen auf der Grundlage mehrdimensionaler Informationen wie Problembeschreibung, Ursache und Lösung erfordert.TABLE Dieser Ansatz ist vorzuziehen. Wenn das Suchszenario strikt auf "Frage-Antwort"-Paare beschränkt ist und Sie Produkt-, Regional- usw. Informationen für eine präzise Filterung verwenden möchten, dann wäre eine bessere Architektur die Verwendung der QA Die Methode schneidet den Q&A-Inhalt in Scheiben und speichert auch Informationen wie Produkte, Regionen usw. in den Metadaten (Metadata) des Blocks.
Doch in RAGFlow Bei unseren Tests haben wir festgestellt, dass das System Metadaten nur auf der Dokumentenebene unterstützt, nicht aber auf der granulareren Chunk-Ebene. Es scheint auch keine direkten Parameter für die metadatenbasierte Filterung in seiner Abruf-API zu geben. Dies ist eine erhebliche Einschränkung beim Aufbau komplexer RAG-Systeme und einer der Gründe, die das Team dazu veranlassten, den Aufbau einer eigenen Wissensdatenbank in Betracht zu ziehen.
Andere spezielle Aufschnittmethoden
RAGFlow Außerdem wird eine Reihe von szenariospezifischen Slicing-Methoden angeboten:
- OneDie Funktion führt keine Aufteilung durch und behandelt das gesamte Dokument als einen einzigen Block.
- ResumeStructured Parsing of CVs to extract key information.
- PaperExtrahieren von Zusammenfassungen, Autoren, Kapiteln, usw. für das Papierformat.
- PresentationFür PPT oder PDF, die aus PPT konvertiert wurden, konvertieren Sie jede Seite in einen separaten Block, der die Screenshots der Seite und den extrahierten Textinhalt enthält.
PRESENTATION Die Testergebnisse der Methode sind wie folgt:
Jenseits des Slicings: Vertiefte Überlegungen zum RAG-Engineering
(tun Sie es einfach) ohne zu zögern RAGFlow Es werden umfangreiche Slicing-Werkzeuge bereitgestellt, aber ein produktionsreifes RAG-System ist viel mehr als das. Die Wahl einer unternehmensinternen Wissensdatenbanklösung basiert in der Regel auf tieferen technischen Anforderungen:
- Benutzerdefinierte Slicing-LogikGeschäftsszenarien erfordern oft hochgradig angepasste Slicing-Regeln, z. B. für Code-Repositories, Datenwörterbücher oder internes Wissen in einem bestimmten Format, das mit On-Premises-Ansätzen nur schwer abgedeckt werden kann.
- Feinkörnige MetadatenverwaltungWie bereits erwähnt, ist das Anhängen umfangreicher Metadaten (z. B. Version, Quelle, verantwortliche Person, Business-Tag) an jeden Wissensblock und die Unterstützung einer effizienten Filterung von zentraler Bedeutung für eine genaue Suche, die Fokussierung des Umfangs und die Verbesserung der Effizienz.
- Versionskontrolle und Lebenszyklusmanagement von Wissensdatenbanken:: Wissensdatenbanken in Produktionsumgebungen müssen über gut etablierte Arbeitsabläufe verfügen. Wenn Wissen hinzugefügt oder aktualisiert wird, muss es getestet und validiert werden, um sicherzustellen, dass es die Stabilität und Genauigkeit des Online-Dienstes nicht beeinträchtigt, bevor es schließlich sicher freigegeben wird.
- Wissensverfeinerung und -erweiterungDas RAG-System muss auch das ursprüngliche Wissen verarbeiten, z.B. Zusammenfassungen erstellen, Wissensgraphenbeziehungen konstruieren, Synonymerweiterungen hinzufügen usw., und die Assoziation dieses abgeleiteten Wissens mit dem ursprünglichen Wissen aufzeichnen, um eine effektive Nachverfolgung und Synchronisation im Falle von Quellenänderungen zu ermöglichen.
Diese komplexen technischen Herausforderungen bilden zusammen den Weg von einem einfachen RAG-Prototyp zu einem zuverlässigen und wartbaren Wissensdienst der Unternehmensklasse.


































