

Ein Phänomen ist weit verbreitet: Selbst wenn RAG Das System verwendet die stärkste LLM, und Prompt wurde immer und immer wieder optimiert, und das Quiz funktioniert immer noch nicht gut, mit Antworten, die entweder kontextuell unvollständig sind oder sachliche Fehler enthalten.
Die Ingenieure untersuchten den Abrufalgorithmus und optimierten die Embedding Modelle, übersieht aber oft einen entscheidenden Schritt, bevor die Daten in die Vektorbibliothek gelangen: das Chunking von Dokumenten.
Unangemessenes Chunking ist gleichbedeutend damit, das Modell mit einem Haufen "schlechter Daten" mit fehlenden Informationen zu füttern. Ganz gleich, wie gut die Schlussfolgerungen des Modells sind, es wird nicht in der Lage sein, aus dem fragmentierten Wissen eine vollständige Antwort zusammenzusetzen. Die Qualität des Chunking bestimmt direkt die untere Grenze der Leistungsfähigkeit des RAG-Systems.
Anstatt über vage Theorien zu sprechen, konzentriert sich dieser Artikel auf realen Code und technische Erfahrungen mit verschiedenen Chunking-Strategien, um eine solide Grundlage für RAG-Systeme zu schaffen.
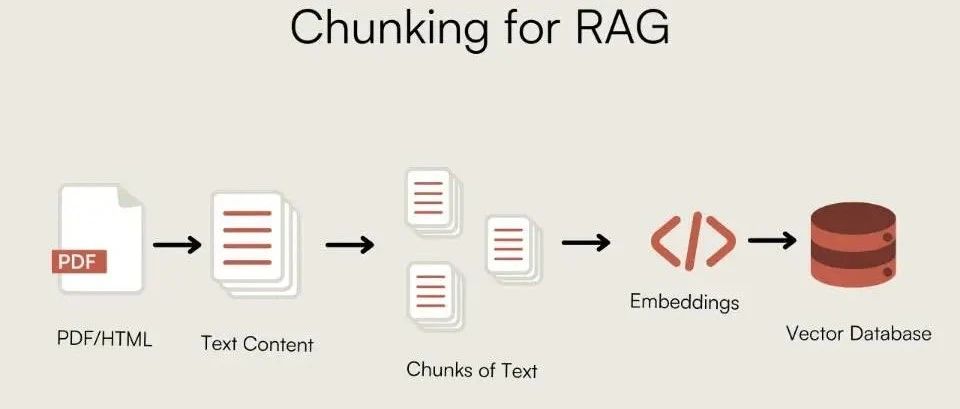
Warum die Klumpen?
Die Notwendigkeit des Chunking ergibt sich aus zwei wesentlichen Einschränkungen:
- Modell-Kontext-FensterDas Large Language Model (LLM) kann keinen Text von unendlicher Länge auf einmal verarbeiten. Beim Chunking wird ein langes Dokument in Teile zerlegt, die das Modell verarbeiten kann.
- Sucheffizienz und RauschenWenn ein Textblock bei der Suche zu viele irrelevante Informationen (Rauschen) enthält, verwässert dies das Kernsignal und erschwert es dem Retriever, die Absicht des Nutzers genau zu erkennen.
Das ideale Chunking liegt in derkontextuelle Integrität与InformationsdichteEin Gleichgewicht finden zwischen.chunk_size 和 chunk_overlap ist der zugrunde liegende Parameter, der dieses Gleichgewicht regelt.chunk_overlap Die semantische Kontinuität über Blockgrenzen hinweg wird dadurch gewährleistet, dass ein Teil des sich wiederholenden Textes zwischen benachbarten Blöcken beibehalten wird.
grundlegende Chunking-Strategie
Chunking mit fester Länge
Dies ist die einfachste Methode, bei der eine voreingestellte Anzahl von Zeichen abgeschnitten wird. Sie berücksichtigt keine logische Struktur des Textes und ist einfach zu implementieren, neigt aber dazu, die semantische Integrität zu zerstören.
- Kerngedanke: nach fester Anzahl von Zeichen
chunk_sizeZerschneiden des Textes. - Anwendbare Szenarien: einfacher Text mit schwacher Struktur oder Vorverarbeitungsstufen mit geringen semantischen Anforderungen.
from langchain_text_splitters import CharacterTextSplitter
sample_text = (
"LangChain was created by Harrison Chase in 2022. It provides a framework for developing applications "
"powered by language models. The library is known for its modularity and ease of use. "
"One of its key components is the TextSplitter class, which helps in document chunking."
)
text_splitter = CharacterTextSplitter(
separator=" ", # Split on spaces
chunk_size=100, # Size of each chunk
chunk_overlap=20, # Overlap between chunks
length_function=len,
)
docs = text_splitter.create_documents([sample_text])
for i, doc in enumerate(docs):
print(f"--- Chunk {i+1} ---")
print(doc.page_content)
Rekursives Chunking von Zeichen
LangChain Empfohlene allgemeine Richtlinie. Sie wird durch eine vordefinierte Liste von Zeichen festgelegt (z. B. ["\n\n", "\n", " ", ""]) führt eine rekursive Segmentierung durch, bei der versucht wird, logische Einheiten wie Absätze und Sätze vorrangig beizubehalten.
- KerngedankeRekursive Aufteilung nach hierarchischer Liste von Trennzeichen.
- Anwendbare SzenarienDie bevorzugte generische Strategie für die große Mehrheit der Textarten.
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Using the same sample_text from the previous example
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
# Default separators are ["\n\n", "\n", " ", ""]
)
docs = text_splitter.create_documents([sample_text])
for i, doc in enumerate(docs):
print(f"--- Chunk {i+1} ---")
print(doc.page_content)
ParameterabstimmungFür Chunking mit fester Länge und rekursives Chunking wird diechunk_size 和 chunk_overlap Die Einstellung ist entscheidend.
chunk_sizeBestimmen Sie die Größe der einzelnen Blöcke. Ein zu kleiner Block bietet nicht genügend Kontextinformationen; ein zu großer Block führt zu viel Rauschen ein und erhöht dieAPIDie Kosten des Anrufs. Dieser Wert basiert in der Regel auf demEmbeddingEingaben in das ModelltokenBeschränkungen zur Auswahl, gemeinsame256,512,1024Äquivalenz, um genau dieBERTisomorph512tokenKontext-Fenster.chunk_overlapBestimmt die Anzahl der sich überlappenden Zeichen zwischen benachbarten Blöcken. Stellen Sie eine angemessene Überlappung ein (z. B.chunk_sizevon 10%-20%) kann wirksam verhindern, dass komplette semantische Einheiten an Blockgrenzen abgeschnitten werden, was der Schlüssel zur Gewährleistung semantischer Kontinuität ist.
Satzbasiertes Chunking
Die Kombination von Sätzen als kleinste Einheit gewährleistet die grundlegendste semantische Integrität.
- KerngedankeAufteilung des Textes in Sätze und anschließende Zusammenfassung von Sätzen zu Blöcken.
- Anwendbare SzenarienSzenarien, die ein hohes Maß an Satzvollständigkeit erfordern, z. B. juristische Dokumente, Nachrichtenberichte.
import nltk
try:
nltk.data.find('tokenizers/punkt')
except nltk.downloader.DownloadError:
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
def chunk_by_sentences(text, max_chars=500, overlap_sentences=1):
sentences = sent_tokenize(text)
chunks = []
current_chunk = ""
for i, sentence in enumerate(sentences):
if len(current_chunk) + len(sentence) <= max_chars:
current_chunk += " " + sentence
else:
chunks.append(current_chunk.strip())
# Create overlap
start_index = max(0, i - overlap_sentences)
current_chunk = " ".join(sentences[start_index:i+1])
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
long_text = "This is the first sentence. This is the second sentence, which is a bit longer. Now we have a third one. The fourth sentence follows. Finally, the fifth sentence concludes this paragraph."
chunks = chunk_by_sentences(long_text, max_chars=100)
for i, chunk in enumerate(chunks):
print(f"--- Chunk {i+1} ---")
print(chunk)
zur Kenntnis nehmenWenn Sie mit Chinesen zu tun habennltk.tokenize.sent_tokenize Das englische Standardmodell wird nicht funktionieren. Es müssen für Chinesisch geeignete Segmentierungsmethoden verwendet werden, z. B. basierend auf chinesischen Satzzeichen (.!?) ), oder unter Verwendung eines regulären Ausdrucks, der mit dem chinesischen Modell der spaCy 或 HanLP usw. Bibliothek.
Strukturbewusstes Chunking
Die Verwendung der inhärenten Strukturinformationen des Dokuments (z. B. Überschriften, Listen) als Chunk-Grenzen ist logisch und erhält den Kontext besser.
Markdown Text Chunking
- Kerngedanke: Basierend auf
Markdownder Titelhierarchie, um die Grenzen des Blocks zu definieren. - Anwendbare Szenarienformal
MarkdownDokumente wieGitHubREADMETechnische Dokumentation.
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = """
# Chapter 1: The Beginning
## Section 1.1: The Old World
This is the story of a time long past.
## Section 1.2: A New Hope
A new hero emerges.
# Chapter 2: The Journey
## Section 2.1: The Call to Adventure
The hero receives a mysterious call.
"""
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
for split in md_header_splits:
print(f"Metadata: {split.metadata}")
print(split.page_content)
print("-" * 20)
chunking
- KerngedankeChunking auf der Grundlage von Sprechern oder Dialogrunden.
- Anwendbare SzenarienDialog mit dem Kundendienst, Gesprächsprotokolle, Sitzungsprotokolle.
dialogue = [
"Alice: Hi, I'm having trouble with my order.",
"Bot: I can help with that. What's your order number?",
"Alice: It's 12345.",
"Alice: I haven't received any shipping updates.",
"Bot: Let me check... It seems your order was shipped yesterday.",
"Alice: Oh, great! Thank you.",
]
def chunk_dialogue(dialogue_lines, max_turns_per_chunk=3):
chunks = []
for i in range(0, len(dialogue_lines), max_turns_per_chunk):
chunk = "\n".join(dialogue_lines[i:i + max_turns_per_chunk])
chunks.append(chunk)
return chunks
chunks = chunk_dialogue(dialogue)
for i, chunk in enumerate(chunks):
print(f"--- Chunk {i+1} ---")
print(chunk)
Semantisches und thematisches Chunking
Diese Art von Ansatz geht über die physische Struktur des Textes hinaus und schneidet den Inhalt auf der Grundlage seiner Semantik in Scheiben und Würfel.
semantisches Chunking
- KerngedankeBerechnen Sie die Vektorähnlichkeit benachbarter Sätze oder Absätze und schneiden Sie an den Stellen, an denen es eine abrupte Änderung der Semantik gibt (geringe Ähnlichkeit).
- Anwendbare SzenarienDokumente, die eine hochpräzise semantische Kohäsion erfordern, wie z. B. Wissensdatenbanken und Forschungsarbeiten.
import os
from langchain_experimental.text_splitter import SemanticChunker
from langchain_huggingface import HuggingFaceEmbeddings
os.environ["TOKENIZERS_PARALLELISM"] = "false"
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# LangChain's SemanticChunker offers different threshold types:
# "percentile": Threshold based on the percentile of similarity score differences. Good for adaptability.
# "standard_deviation": Threshold based on standard deviation of similarity scores.
# "interquartile": Uses the interquartile range, robust to outliers.
# "gradient": Looks for sharp changes in similarity, useful for detecting abrupt topic shifts.
text_splitter = SemanticChunker(
embeddings,
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=95 # A higher percentile means it only breaks on very significant semantic shifts.
)
long_text = (
"The Wright brothers, Orville and Wilbur, were two American aviation pioneers "
"generally credited with inventing, building, and flying the world's first successful motor-operated airplane. "
"They made the first controlled, sustained flight of a powered, heavier-than-air aircraft on December 17, 1903. "
"In the following years, they continued to develop their aircraft. "
"Switching topics completely, let's talk about cooking. "
"A good pizza starts with a perfect dough, which needs yeast, flour, water, and salt. "
"The sauce is typically tomato-based, seasoned with herbs like oregano and basil. "
"Toppings can vary from simple mozzarella to a wide range of meats and vegetables. "
"Finally, let's consider the solar system. "
"It is a gravitationally bound system of the Sun and the objects that orbit it. "
"The largest objects are the eight planets, in order from the Sun: Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, and Neptune."
)
docs = text_splitter.create_documents([long_text])
for i, doc in enumerate(docs):
print(f"--- Chunk {i+1} ---")
print(doc.page_content)
print()
Parameterabstimmung:SemanticChunker Die Wirksamkeit des Programms ist in hohem Maße abhängig von den breakpoint_threshold_amountDieser Schwellenwert steuert die "Empfindlichkeit für semantische Änderungen". Dieser Schwellenwert steuert die "Empfindlichkeit für semantische Änderungen". Ein niedriger Schwellenwert führt zu einer großen Anzahl kleiner, zusammenhängender Chunks, während ein hoher Schwellenwert nur bei einer signifikanten Veränderung des Themas schneidet. Die Experimente müssen je nach Inhalt des Dokuments wiederholt werden.
Themenbezogenes Chunking
- KerngedankeThematische Modelle verwenden (z. B.
LDA) oder Clustering-Algorithmen, die Dokumente entsprechend ihrer Makrothematik zerschneiden und zerlegen. - Anwendbare SzenarienLange, mehrere Themen umfassende Berichte oder Bücher.
import numpy as np
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import nltk
from nltk.corpus import stopwords
try:
stopwords.words('english')
except LookupError:
nltk.download('stopwords')
def lda_topic_chunking(text: str, n_topics: int = 3) -> list[str]:
# 1. Preprocessing: Treat each paragraph as a "document"
paragraphs = [p.strip() for p in text.split('\n\n') if p.strip()]
if len(paragraphs) <= 1:
return [text]
cleaned_paragraphs = [re.sub(r'[^a-zA-Z\s]', '', p).lower() for p in paragraphs]
# 2. Bag of Words + Stopword Removal
vectorizer = CountVectorizer(min_df=1, stop_words=stopwords.words('english'))
X = vectorizer.fit_transform(cleaned_paragraphs)
if X.shape == 0:
return paragraphs
# 3. LDA Topic Modeling
lda = LatentDirichletAllocation(n_components=n_topics, random_state=42)
lda.fit(X)
# 4. Determine dominant topic for each paragraph
topic_dist = lda.transform(X)
dominant_topics = np.argmax(topic_dist, axis=1)
# 5. Chunking based on topic changes
chunks = []
current_chunk_paragraphs = []
current_topic = dominant_topics
for i, paragraph in enumerate(paragraphs):
if dominant_topics[i] == current_topic:
current_chunk_paragraphs.append(paragraph)
else:
chunks.append("\n\n".join(current_chunk_paragraphs))
current_chunk_paragraphs = [paragraph]
current_topic = dominant_topics[i]
chunks.append("\n\n".join(current_chunk_paragraphs))
return chunks
zur Kenntnis nehmenThemenbasiertes Chunking ist sehr empfindlich gegenüber der Textlänge, der Themenunterscheidung und den Vorverarbeitungsschritten und erfordert eine vorgegebene Anzahl von Themen. Diese Methode eignet sich eher als exploratives Werkzeug für lange Dokumente mit klaren Themengrenzen.
Erweiterte Chunking-Strategie
Klein bis groß
- KerngedankeHochpräzises Retrieval unter Verwendung kleiner Chunks (z.B. Sätze), wobei der ursprüngliche Chunk (z.B. Absatz), der den Chunk enthält, als Kontext an die
LLM. Es kombiniert die hohe Auffindungsgenauigkeit von kleinen Chunks mit dem reichhaltigen Kontext großer Chunks. - Anwendbare SzenarienKomplexe Q&A-Szenarien, die eine hohe Abfragegenauigkeit und einen umfangreichen Generierungskontext erfordern.
在 LangChain Mitte.ParentDocumentRetriever setzt diese Idee um. Es verwaltet zwei parallele Verarbeitungsströme im Hintergrund:
- Teilen Sie das Dokument in große "übergeordnete Blöcke" auf.
- Jeder übergeordnete Block ist weiter in kleinere "Kindblöcke" unterteilt.
- Erstellen Sie Vektorindizes nur für Teilblöcke.
- Die Suche wird durchgeführt, indem zuerst der relevante Teilblock gefunden wird und dann durch eine separate
docstoreDas Extrahieren ihrer entsprechenden übergeordneten Blöcke wird an dieLLM。
# from langchain.embeddings import OpenAIEmbeddings
# from langchain_text_splitters import RecursiveCharacterTextSplitter
# from langchain.retrievers import ParentDocumentRetriever
# from langchain_community.document_loaders import TextLoader
# from langchain_chroma import Chroma
# from langchain.storage import InMemoryStore
# Assume 'docs' are loaded documents
# parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), collection_name="split_parents")
# store = InMemoryStore() # This store holds the parent documents
# retriever = ParentDocumentRetriever(
# vectorstore=vectorstore,
# docstore=store,
# child_splitter=child_splitter,
# parent_splitter=parent_splitter,
# )
# retriever.add_documents(docs)
# sub_docs = vectorstore.similarity_search("query") # Retrieves small chunks
# retrieved_docs = retriever.get_relevant_documents("query") # Retrieves large parent chunks
# print(retrieved_docs.page_content)
Agentisches Chunking
- Kerngedanke: Mit einer
LLMAgentum den menschlichen Leseverstehensprozess zu simulieren und Chunk-Grenzen dynamisch zu bestimmen. Zum Beispiel kann der HinweisLLMZerlegung eines Textes in mehrere "in sich geschlossene Wissenseinheiten". - Anwendbare SzenarienExperimentelle Projekte oder Umgang mit hochkomplexen, unstrukturierten Texten. Äußerst kostspielig, Stabilität muss nachgewiesen werden.
import textwrap
# from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
class KnowledgeChunk(BaseModel):
chunk_title: str = Field(description="A concise title for this knowledge chunk.")
chunk_text: str = Field(description="A self-contained text extracted and synthesized from the original paragraph.")
representative_question: str = Field(description="A typical question that can be answered by this chunk.")
class ChunkList(BaseModel):
chunks: List[KnowledgeChunk]
parser = PydanticOutputParser(pydantic_object=ChunkList)
prompt_template = """
[ROLE]: You are a top-tier document analyst. Your task is to decompose complex text into a set of core, self-contained "Knowledge Chunks".
[TASK]: Read the provided text, identify the distinct core concepts, and create a knowledge chunk for each.
[RULES]:
1. Self-Contained: Each chunk must be understandable on its own.
2. Single Concept: Each chunk should focus on only one core idea.
3. Extract and Restructure: Pull all relevant sentences for a concept and combine them into a coherent paragraph.
4. Follow Format: Strictly adhere to the JSON format instructions below.
{format_instructions}
[TEXT TO PROCESS]:
{paragraph_text}
"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["paragraph_text"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# The following part is a simulation, as it requires a running LLM model.
# model = ChatOpenAI(model="gpt-4", temperature=0.0)
# chain = prompt | model | parser
# result = chain.invoke({"paragraph_text": document_text})
Mixed Chunking: Gleichgewicht zwischen Effizienz und Qualität
In der Praxis ist es schwierig, alle Situationen mit einer einzigen Strategie zu bewältigen. Mixed Chunking ist eine sehr praktische Technik.
- KerngedankeGrobkörniges Slicing mit einer Makrostrategie (z. B. strukturiertes Chunking), gefolgt von einem sekundären Slicing übergroßer Chunks mit einer feineren Strategie (z. B. rekursives Chunking).
- Anwendbare SzenarienHandhabung von Dokumenten mit komplexen Strukturen und ungleichmäßiger Inhaltsdichte.
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
from langchain_core.documents import Document
markdown_document = """
# Chapter 1: Company Profile
Our company was founded in 2017...
## 1.1 Development History
The company has experienced rapid growth...
# Chapter 2: Core Technology
This chapter describes our core technologies in detail. Our framework is based on advanced distributed computing concepts... (A very long paragraph with multiple sentences describing different technical aspects like CNNs, Transformers, data pipelines, etc.)
## 2.1 Technical Principles
Our principles combine statistics, machine learning...
# Chapter 3: Future Outlook
Looking ahead, we will continue to invest in AI...
"""
def hybrid_chunking(
markdown_document: str,
coarse_chunk_threshold: int = 400,
fine_chunk_size: int = 100,
fine_chunk_overlap: int = 20
) -> list[Document]:
# 1. Coarse-grained splitting by structure
headers_to_split_on = [("#", "Header 1"), ("##", "Header 2")]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
coarse_chunks = markdown_splitter.split_text(markdown_document)
# 2. Fine-grained recursive splitter for oversized chunks
fine_splitter = RecursiveCharacterTextSplitter(
chunk_size=fine_chunk_size,
chunk_overlap=fine_chunk_overlap
)
final_chunks = []
for chunk in coarse_chunks:
if len(chunk.page_content) > coarse_chunk_threshold:
# If a chunk is too large, split it further
finer_chunks = fine_splitter.split_documents([chunk])
final_chunks.extend(finer_chunks)
else:
final_chunks.append(chunk)
return final_chunks
final_chunks = hybrid_chunking(markdown_document)
for i, chunk in enumerate(final_chunks):
print(f"--- Final Chunk {i+1} (Length: {len(chunk.page_content)}) ---")
print(f"Metadata: {chunk.metadata}")
print(chunk.page_content)
print("-" * 80)
Wie wählt man die beste Chunking-Strategie?
Angesichts einer Vielzahl von Strategien ist es wichtiger, einen vernünftigen Weg zu wählen, als eine nach der anderen auszuprobieren. Es wird empfohlen, den folgenden hierarchischen Entscheidungsrahmen zu befolgen.
Schritt 1: Beginnen Sie mit einer grundlegenden Strategie
- Standardoption:
RecursiveCharacterTextSplitter. Dies ist der sicherste Ausgangspunkt, unabhängig davon, welche Art von Text verarbeitet wird. Verwenden Sie ihn, um eine Leistungsgrundlage zu schaffen.
Schritt 2: Untersuchen Sie strukturierte Merkmale
- vorrangige Option: Strukturiertes Chunking. Wenn das Dokument eine explizite Struktur hat (
MarkdownTitel,HTMLRegisterkarte), wechseln Sie zumMarkdownHeaderTextSplitterund andere Methoden. Dies ist die Optimierung mit den geringsten Kosten und den offensichtlichsten Vorteilen.
Schritt 3: Wenn die Genauigkeit zum Engpass wird
- Erweiterte OptionenSemantisches Chunking oder klein-großes Chunking. Wenn die Suchergebnisse der grundlegenden und strukturierten Strategien immer noch unbefriedigend sind, deutet dies auf den Bedarf an höherdimensionalen semantischen Informationen hin.
SemanticChunkerFür Szenarien, die ein hohes Maß an semantischer Konsistenz innerhalb eines Blocks erfordern.ParentDocumentRetriever(kleine-große Brocken): geeignet sowohl für die Suchgenauigkeit als auch für die Notwendigkeit, ein klareres Verständnis für dieLLMKomplexe Q&A-Szenarien, die einen vollständigen Kontext bieten.
Schritt 4: Umgang mit extrem komplexen Dokumenten
- Fortgeschrittene PraxisHybrides Chunking. Für Dokumente mit komplexen Strukturen und ungleichmäßiger Inhaltsdichte ist hybrides Chunking die beste Methode, um Kosten und Effektivität in Einklang zu bringen.
In der folgenden Tabelle sind alle diskutierten Chunking-Strategien zusammengefasst.
| Chunking-Strategie | Zentrale Logik | Blickwinkel | Nachteile und Kosten |
|---|---|---|---|
| Chunking mit fester Länge | um eine bestimmte Anzahl von Zeichen oder token Teil einer Zahl (z. B. Dezimalzahl oder römische Zahl) |
Einfach und schnell zu implementieren | Zerstört leicht die Semantik und ist am wenigsten effektiv |
| rekursives Chunking | Rekursive Aufteilung nach vordefinierten Trennzeichen (Absätze, Sätze) | Vielseitigkeit, bessere Erhaltung der Struktur | Ziemlich wirksam bei unregelmäßigen Dokumenten |
| Satzbasiertes Chunking | Sätze als kleinste Einheit, dann zu Blöcken zusammengefasst | Satzintegrität sicherstellen | Der Kontext eines einzelnen Satzes kann unzureichend sein; lange Sätze müssen behandelt werden |
| Strukturiertes Chunking | Nutzung der inhärenten Struktur des Dokuments (z. B. Überschriften) zum Zerschneiden und Zerlegen | Logisch und klar im Kontext | Starke Abhängigkeit vom Dokumentenformat, nicht generisch |
| semantisches Chunking | Slicing auf der Grundlage lokaler semantischer Ähnlichkeitsänderungen | Hohe Kohäsion der Konzepte innerhalb eines Blocks, hohe Abrufgenauigkeit | Hohe Berechnungskosten (Embedding Berechnungen), die sich auf die Modellqualität stützen |
| Themenbezogenes Chunking | Slicing nach globalen Themengrenzen unter Verwendung von Themenmodellen | Die Informationen innerhalb des Blocks sind stark korreliert | Komplexe Implementierung, empfindlich gegenüber Daten und Parametern, instabile Ergebnisse |
| hybrides Chunking | Makro-Segmentierung + Mikro-Segmentierung | Ein Gleichgewicht zwischen Effizienz und Qualität und Zweckmäßigkeit | Komplexere Implementierungslogik |
| kleine-große Brocken | Kleine Blöcke für den Abruf, große Blöcke für die Erzeugung | Kombiniert hochpräzise Suche mit umfangreichem Kontext | Komplexität der Pipeline, Notwendigkeit der Verwaltung von zwei Indexsätzen, Verdoppelung der Speicherkosten |
| Proxy-Bündelung | AI Agenten-Dynamik-Analyse und Slicing-Dokumentation |
Theoretisch optimal | Experimentell und extrem kostspielig (API Aufruf) mit einer großen Verzögerung |
































