



OpusLM_7B_Anneal ist ein Open-Source-Sprachverarbeitungsmodell, das vom ESPnet-Team entwickelt und auf der Hugging Face-Plattform gehostet wird. Es konzentriert sich auf eine Vielzahl von Aufgaben wie Spracherkennung, Text-zu-Sprache, Sprachübersetzung und Sprachverbesserung und ist für Forscher und Entwickler geeignet, um im Bereich der Sprachverarbeitung zu experimentieren und anzuwenden. Das Modell basiert auf dem PyTorch-Framework und kombiniert Datenverarbeitung im Stil von Kaldi, um eine effiziente End-to-End-Sprachverarbeitungslösung zu bieten.OpusLM_7B_Anneal ist Teil des ESPnet-Ökosystems, das mehrsprachige und vielfältige Sprachaufgaben für eine breite Palette von akademischen Forschungs- und realen Entwicklungsanwendungen unterstützt.
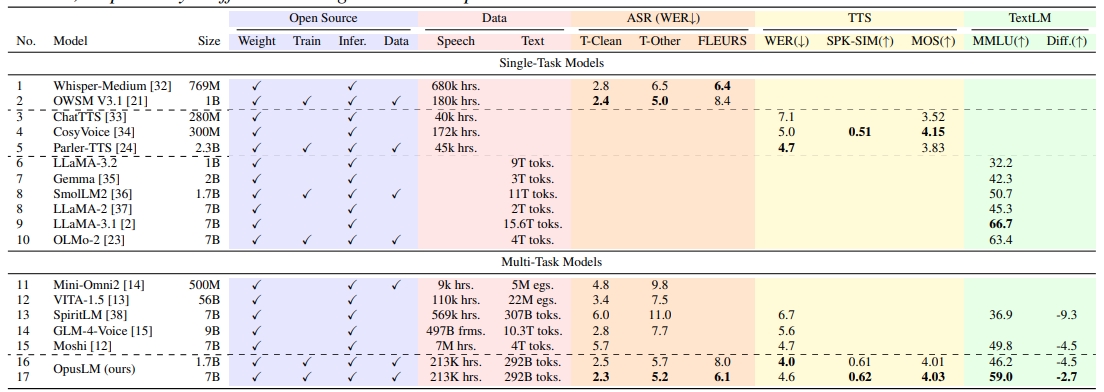
Funktionsliste
- SpracherkennungKonvertiert Audioeingaben in Text und unterstützt mehrsprachige Spracherkennung.
- Text-to-SpeechGenerieren Sie eine natürliche und flüssige Sprachausgabe aus Texteingaben.
- SprachübersetzungErmöglicht die Umwandlung von Text oder Sprache von einer Sprache in eine andere.
- SprachverbesserungOptimieren Sie die Audioqualität, reduzieren Sie Hintergrundgeräusche und verbessern Sie die Sprachverständlichkeit.
- Feinabstimmung der ModelleUnterstützung der Benutzer bei der Feinabstimmung des Modells auf bestimmte Aufgaben.
- Open-Source-UnterstützungBietet vollständige Modellgewichte und Profile für eine einfache Integration und Sekundärentwicklung durch Entwickler.
Hilfe verwenden
Einbauverfahren
Um das Modell OpusLM_7B_Anneal zu verwenden, müssen Sie zunächst das ESPnet-Toolkit und die zugehörigen Abhängigkeiten installieren. Im Folgenden finden Sie die detaillierten Installationsschritte:
- Vorbereitung der Umwelt
Stellen Sie sicher, dass Sie Python 3.7 oder höher auf Ihrem System installiert haben, und es wird eine virtuelle Umgebung empfohlen, um Abhängigkeitskonflikte zu vermeiden:python -m venv espnet_env source espnet_env/bin/activate # Linux/Mac espnet_env\Scripts\activate # Windows - Installation von ESPnet
Installieren Sie ESPnet mit pip:pip install espnet - Installieren zusätzlicher Abhängigkeiten
OpusLM_7B_Anneal hängt von PyTorch und den Soundfile-Bibliotheken ab, stellen Sie sicher, dass Sie die richtige Version installieren:pip install torch torchaudio soundfile - Modelle herunterladen
Laden Sie die Modelldatei OpusLM_7B_Anneal von der Hugging Face-Plattform herunter. Dies kann über diehuggingface-cliWerkzeuge:huggingface-cli download espnet/OpusLM_7B_Anneal --local-dir ./OpusLM_7B_AnnealDadurch werden die Modellgewichte (
model.pth), Konfigurationsdateien (config.yaml) und Dekodierungsprofile (decode_default.yaml) wird in das angegebene Verzeichnis heruntergeladen. - Überprüfen der Installation
Führen Sie den folgenden Code aus, um zu überprüfen, ob die Umgebung korrekt ist:from espnet2.bin.tts_inference import Text2Speech text2speech = Text2Speech.from_pretrained("espnet/OpusLM_7B_Anneal") print("Model loaded successfully!")
Verwendung
OpusLM_7B_Anneal unterstützt eine breite Palette von Sprachverarbeitungsaufgaben. Im Folgenden wird der detaillierte Ablauf der Hauptfunktionen beschrieben:
1. text-to-speech
Die Text-to-Speech-Funktion kann den eingegebenen Text in natürliche Sprache umwandeln. Die Arbeitsschritte sind wie folgt:
- Modelle laden: Mit ESPnets
Text2SpeechModell zum Laden von Klassen:from espnet2.bin.tts_inference import Text2Speech import soundfile text2speech = Text2Speech.from_pretrained("espnet/OpusLM_7B_Anneal") - Sprache generierenEingabe von Text, um die entsprechende Sprachwellenform zu erzeugen:
speech = text2speech("你好,这是一个测试文本。")["wav"] - Audio speichernSpeichern: Speichert die erzeugte Stimme als WAV-Datei:
soundfile.write("output.wav", speech.numpy(), text2speech.fs, "PCM_16") - caveatStellen Sie sicher, dass der Eingabetext mit den vom Modell unterstützten Sprachen übereinstimmt (z. B. Chinesisch, Englisch usw.). Sprachton oder Geschwindigkeit können über eine Konfigurationsdatei eingestellt werden.
2. die Spracherkennung
Die Spracherkennungsfunktion wandelt Audiodateien in Text um. Das Verfahren ist wie folgt:
- Audio vorbereitenVergewissern Sie sich, dass die Audiodatei im WAV-Format vorliegt und die Abtastrate 16 kHz beträgt oder mit dem Modell kompatibel ist.
- Modelle laden: Mit ESPnets
Speech2TextKlasse:from espnet2.bin.asr_inference import Speech2Text speech2text = Speech2Text.from_pretrained("espnet/OpusLM_7B_Anneal") - Anerkennung der Führungskräfte: Geben Sie den Pfad der Audiodatei ein, um das Erkennungsergebnis zu erhalten:
text, *_ = speech2text("input.wav")[0] print("识别结果:", text) - Tipps zur OptimierungWenn die Audioqualität schlecht ist, verwenden Sie zunächst die Sprachverbesserungsfunktion, um den Ton zu bearbeiten.
3. die Sprachübersetzung
Die Sprachübersetzungsfunktion unterstützt die Umwandlung von Sprache aus einer Sprache in Text oder Sprache in einer anderen Sprache. Die Arbeitsschritte sind wie folgt:
- Laden des Übersetzungsmodells:
from espnet2.bin.st_inference import Speech2Text speech2text = Speech2Text.from_pretrained("espnet/OpusLM_7B_Anneal", task="st") - Ausführender Übersetzer: Eingabe der Audiodatei, Angabe der Zielsprache (z. B. Englisch):
text, *_ = speech2text("input_chinese.wav", tgt_lang="en")[0] print("翻译结果:", text) - Sprache generierenWenn Sie die Übersetzungsergebnisse in Sprache umwandeln möchten, können Sie diese mit der Text-to-Speech-Funktion kombinieren:
text2speech = Text2Speech.from_pretrained("espnet/OpusLM_7B_Anneal") speech = text2speech(text)["wav"] soundfile.write("translated_output.wav", speech.numpy(), text2speech.fs, "PCM_16")
4. die Verbesserung der Stimme
Die Funktion Sprachverbesserung verbessert die Audioqualität und eignet sich für die Bearbeitung von Aufnahmen, die Rauschen enthalten. Das Verfahren ist wie folgt:
- Modelle laden:
from espnet2.bin.enh_inference import SpeechEnhancement speech_enh = SpeechEnhancement.from_pretrained("espnet/OpusLM_7B_Anneal") - Verarbeitung von AudioEingang für rauschbehaftete Frequenzen und Ausgang für verbesserten Ton:
enhanced_speech = speech_enh("noisy_input.wav")["wav"] soundfile.write("enhanced_output.wav", enhanced_speech.numpy(), speech_enh.fs, "PCM_16") - caveatAudioformat: Vergewissern Sie sich, dass das Audioformat mit den Anforderungen des Modells übereinstimmt, um einen Speicherüberlauf aufgrund von zu langen Audiodaten zu vermeiden.
5. die Feinabstimmung des Modells
Um das Modell für eine bestimmte Aufgabe (z.B. eine bestimmte Sprache oder ein bestimmtes Szenario) zu optimieren, können die von ESPnet bereitgestellten Feinabstimmungswerkzeuge verwendet werden:
- Vorbereiten des DatensatzesVorbereitung von beschrifteten Sprach- und Textdaten in einem Format, das dem Kaldi-Stil entspricht.
- Feinabstimmung der KonfigurationModifikation
config.yamlDatei, um die Trainingsparameter festzulegen. - Operative Feinabstimmung:
espnet2/bin/train.py --config config.yaml --model_file model.pth - Speichern Sie das Modell: Nach Abschluss der Feinabstimmung verwenden Sie die
run.shDas Drehbuch wird auf Hugging Face hochgeladen:./run.sh --stage 13 --model_dir ./exp
Weitere Tipps zur Verwendung
- Beschreibung der ModelldateiDie Modelldateien enthalten
model.pth(gewichtete Datei, ca. 3,77 GB),config.yaml(Modellkonfiguration),decode_default.yaml(Konfiguration dekodieren). Stellen Sie sicher, dass Sie die vollständige Datei herunterladen. - Computerressource: GPU-beschleunigtes Rechnen wird empfohlen, und für einen reibungslosen Betrieb werden mindestens 16 GB Videospeicher empfohlen.
- Unterstützung der Gemeinschaft: siehe die offizielle ESPnet-Dokumentation (
https://espnet.github.io/espnet/) oder Hugging Face Community-Diskussionen für technische Unterstützung.
Anwendungsszenario
- akademische Forschung
Forscher können OpusLM_7B_Anneal zur Durchführung von Sprachverarbeitungsexperimenten verwenden, z. B. zur Entwicklung neuer Spracherkennungsalgorithmen oder zum Testen mehrsprachiger Übersetzungsmodelle. Der Open-Source-Charakter des Modells erleichtert die Sekundärentwicklung und -validierung. - Intelligente Kundenbetreuung
Unternehmen können das Modell in ihre Kundendienstsysteme integrieren, um automatische Antworten und mehrsprachigen Support durch Spracherkennung und Text-to-Speech-Funktionen zu erreichen und so die Effizienz des Kundendienstes zu verbessern. - Pädagogische Hilfsmittel
Bildungseinrichtungen können Sprachübersetzungs- und Text-to-Speech-Funktionen nutzen, um Sprachlerntools zu entwickeln, mit denen Schüler die Aussprache üben oder fremdsprachliche Inhalte übersetzen können. - Erstellung von Inhalten
Inhaltsersteller können die Text-to-Speech-Funktion nutzen, um Kommentare für Videos oder Podcasts zu erstellen, die mehrere Sprachen und Stile unterstützen und die Produktionskosten senken.
QA
- Welche Sprachen werden von OpusLM_7B_Anneal unterstützt?
Das Modell unterstützt mehrere Sprachen, darunter Chinesisch, Englisch, Japanisch und so weiter. Spezifische unterstützte Sprachen finden Sie unterconfig.yamlDatei oder ESPnet-Dokument. - Wie gehen Sie mit großen Audiodateien um?
Bei langen Audiodateien empfiehlt es sich, sie in kurze Segmente (jeweils 10-30 Sekunden) aufzuteilen und diese getrennt zu verarbeiten, um einen Speicherüberlauf zu vermeiden. Die Aufteilung kann mit einem Audiobearbeitungsprogramm wie Audacity vorgenommen werden. - Unterstützt das Modell die Echtzeitverarbeitung?
Das derzeitige Modell wird hauptsächlich für die Offline-Verarbeitung verwendet. Bei Echtzeitanwendungen muss die Inferenzgeschwindigkeit optimiert werden, daher wird empfohlen, Hochleistungs-GPUs zu verwenden und die Stapelgröße anzupassen. - Wie löst man das Problem der Modellbelastung?
Überprüfen Sie, ob die PyTorch- und ESPnet-Versionen kompatibel sind, und stellen Sie sicher, dass Ihre Modelldateien vollständig sind. Wenden Sie sich an die Hugging Face Community oder ESPnet GitHub für Hilfe.
Ein Satz Beschreibung (kurz)






























