


Für alle Entwickler, die Open-Source-Modelle für große Sprachen lokal ausführen möchten, ist dasOllama Es ist zu einem unverzichtbaren Werkzeug geworden. Es hat den Prozess des Herunterladens, der Bereitstellung und der Verwaltung von Modellen erheblich vereinfacht. Mit der explosionsartigen Zunahme der Modellparametergrößen haben jedoch selbst professionelle PCs mit Hunderten von Gigabytes an Video- und Speicheranforderungen zu kämpfen, so dass viele hochmoderne Modelle für die meisten Entwickler unerreichbar sind.
Um diesen zentralen Schmerzpunkt zu beseitigen, hat dieOllama Die Cloud Models-Vorschau wurde kürzlich offiziell vorgestellt. Der neue Dienst soll Entwicklern die Möglichkeit geben, diese riesigen Modelle auf Hardware in Rechenzentrumsqualität in einem cleveren Schema auszuführen, das genauso interaktiv ist wie die lokale Ausführung.
Kernfunktionen: Überwindung von Hardwarebeschränkungen und Beibehaltung der lokalen Erfahrung
Ollama Cloud Die Design-Philosophie besteht nicht darin, einfach eine Cloud-API-Schnittstelle bereitzustellen, sondern die Cloud-Arithmetik nahtlos in die lokalen Arbeitsabläufe zu integrieren, mit denen die Entwickler vertraut sind.
- Hardware-Beschränkungen durchbrechenBenutzer können nun direkt eine Datei wie
deepseek-v3.1:671b(671 Milliarden Parameter) oderqwen3-coder:480b(480 Milliarden Parameter) solche Riesenmodelle. Bei ersterem handelt es sich um ein leistungsstarkes hybrides Denkmodell, während letzteres von Alibaba entwickelt wurde und auf die Codegenerierung und Agentenaufgaben spezialisiert ist. Diese Modelle erfordern Rechenressourcen, die weit über die Möglichkeiten von Privatgeräten hinausgehen, und dieOllama CloudDann ist dieses Hindernis vollständig beseitigt. - Nahtlose LokalisierungserfahrungDies ist
Ollama CloudDer attraktivste Punkt. Die Benutzer brauchen die bestehende Toolchain nicht zu ändern, alle Operationen werden weiterhin über die lokaleOllamaClient zu vervollständigen. Ob Sie dieollama runum einen interaktiven Dialog zu führen, oder über dieollama lsDas Anzeigen einer Liste von Modellen ist genau dasselbe wie die Verwaltung lokaler Modelle. Das Cloud-Modell wird lokal als leichtgewichtige Referenz oder "Verknüpfung" dargestellt, die keinen Speicherplatz beansprucht. - Vorrang für Datenschutz und SicherheitDatenschutz ist ein wichtiger Aspekt bei KI-Anwendungen.
OllamaOffiziell wird ausdrücklich versprochen, dass die Cloud-Server keine Abfragedaten von Nutzern speichern werden, so dass Gespräche und Codeschnipsel privat bleiben. - Kompatibel mit OpenAI API:
Ollamader lokalen Dienstleistungen wegen ihrer Auswirkungen aufOpenAIDie Kompatibilität des API-Formats ist beliebt.Ollama CloudDie Vererbung dieses Merkmals bedeutet, dass alle bestehende Unterstützung fürOpenAIAnwendungen und Arbeitsabläufe mit APIs können без nahtlos zur Nutzung dieser großen Modelle in der Cloud wechseln.
Derzeit verfügbare Cloud-Modelle
Derzeit.Ollama Cloud Die Vorschauversion bietet die folgenden übergroßen parametrischen Modelle, alle mit dem Modellnamen -cloud Suffixe werden zur Unterscheidung verwendet:
- qwen3-coder:480b-cloudAlibabas Vorzeigemodell mit Schwerpunkt auf Codegenerierung und Agentenaufgaben.
- deepseek-v3.1:671b-cloudEin ultragroßes Mehrzweckmodell, das verschiedene Denkweisen unterstützt und sich durch logisches Denken und Kodierung auszeichnet.
- gpt-oss:120b-cloud
- gpt-oss:20b-cloud
Schnellstart-Anleitung
Erfahrungen Ollama Cloud Das Verfahren ist sehr einfach und kann in wenigen Schritten durchgeführt werden.
Schritt 1: Ollama aktualisieren
Stellen Sie sicher, dass die lokal installierten Ollama Versions-Upgrade auf v0.12 oder höher. Sie können die neueste Version von der offiziellen Website herunterladen oder den System Package Manager zur Aktualisierung verwenden.
Schritt 2: Melden Sie sich bei Ihrem Ollama-Konto an.
Da das Cloud-Modell die ollama.com EDV-Ressourcen zu nutzen, müssen sich die Nutzer bei ihren Ollama Konto, um die Authentifizierung abzuschließen. Führen Sie den folgenden Befehl im Terminal aus:
ollama signin
Mit diesem Befehl wird der Benutzer angewiesen, die Anmeldeautorisierung im Browser abzuschließen.
Schritt 3: Ausführen des Wolkenmodells
Sobald Sie sich erfolgreich angemeldet haben, können Sie das Cloud-Modell direkt wie ein lokales Modell ausführen. Um zum Beispiel den Parameter 480 Milliarden zu starten Qwen3-Coder Modell, einfach ausführen:
ollama run qwen3-coder:480b-cloud
Ollama Der Client kümmert sich automatisch um die Weiterleitung aller Anfragen an die Cloud, und der Nutzer wartet einfach auf die Antwort des Modells.
Schritt 4: Verwalten des Cloud-Modells
ausnutzen ollama ls um die Liste der Modelle anzuzeigen, die lokal gezogen wurden. Sie werden feststellen, dass das Wolkenmodell SIZE Die Spalte wird angezeigt als -was intuitiv zeigt, dass es sich nur um einen Verweis handelt, der keinen lokalen Speicherplatz beansprucht.
% ollama ls
NAME ID SIZE MODIFIED
gpt-oss:120b-cloud 569662207105 - 5 seconds ago
qwen3-coder:480b-cloud 11483b8f8765 - 2 days ago
API-Integration und -Aufrufe
Für Entwickler sind API-Aufrufe das Herzstück der Integration.Ollama Cloud Unterstützt zwei Haupttypen von API-Aufrufen: über lokale Proxys und direkten Zugang zu Cloud-Endpunkten.
Option 1: Über den lokalen Ollama Service Agent
Dies ist die einfachste und empfehlenswerteste Methode, die sich perfekt in bestehende Arbeitsabläufe einfügt.
Verwenden Sie zunächst die pull wird die Modellreferenz lokal gezogen:
ollama pull gpt-oss:120b-cloud
Rufen Sie dann, wie bei jedem lokalen Modell, die lokale Ollama Dienstleistungen (http://localhost:11434) Senden Sie die Anfrage.
Python-Beispiel
import ollama
response = ollama.chat(
model='gpt-oss:120b-cloud',
messages=[{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])
JavaScript (Node.js) Beispiele
import ollama from "ollama";
const response = await ollama.chat({
model: "gpt-oss:120b-cloud",
messages: [{ role: "user", content: "Why is the sky blue?" }],
});
console.log(response.message.content);
cURL-Beispiel
curl http://localhost:11434/api/chat -d '{
"model": "gpt-oss:120b-cloud",
"messages": [{
"role": "user",
"content": "Why is the sky blue?"
}],
"stream": false
}'
Weg 2: Direkter Zugriff auf die Cloud-API
In einigen Szenarien, z. B. in einer Server- oder Cloud-Funktion, ist es bequemer, die Cloud-API direkt aufzurufen.
- API-Endpunkte:
https://ollama.com/v1/chat/completions - API-Schlüssel Anwendung: Für den direkten Zugriff auf diesen Endpunkt ist ein spezieller API-Schlüssel erforderlich, den die Benutzer in der Datei
OllamaNachdem Sie sich auf der offiziellen Website angemeldet haben, gehen Sie auf die Seite Schlüssel, um Ihren eigenen Schlüssel zu generieren.
Direkte Aufrufe von Cloud-APIs folgen dem Standard OpenAI Format, tragen Sie einfach die entsprechende Authorization Gutscheine sind ausreichend.
Integration mit Tools von Drittanbietern
Ollama Cloud Die Stärke des Designs liegt in seiner nahtlosen ökologischen Kompatibilität. Die gesamte Unterstützung ist über das Ollama Ein Drittanbieter-Client, der eine Verbindung von einem lokalen API-Endpunkt herstellt, wie z. B. der Open WebUI、LobeChat 或 Cherry StudioDas Wolkenmodell kann ohne jegliche Änderung direkt verwendet werden.
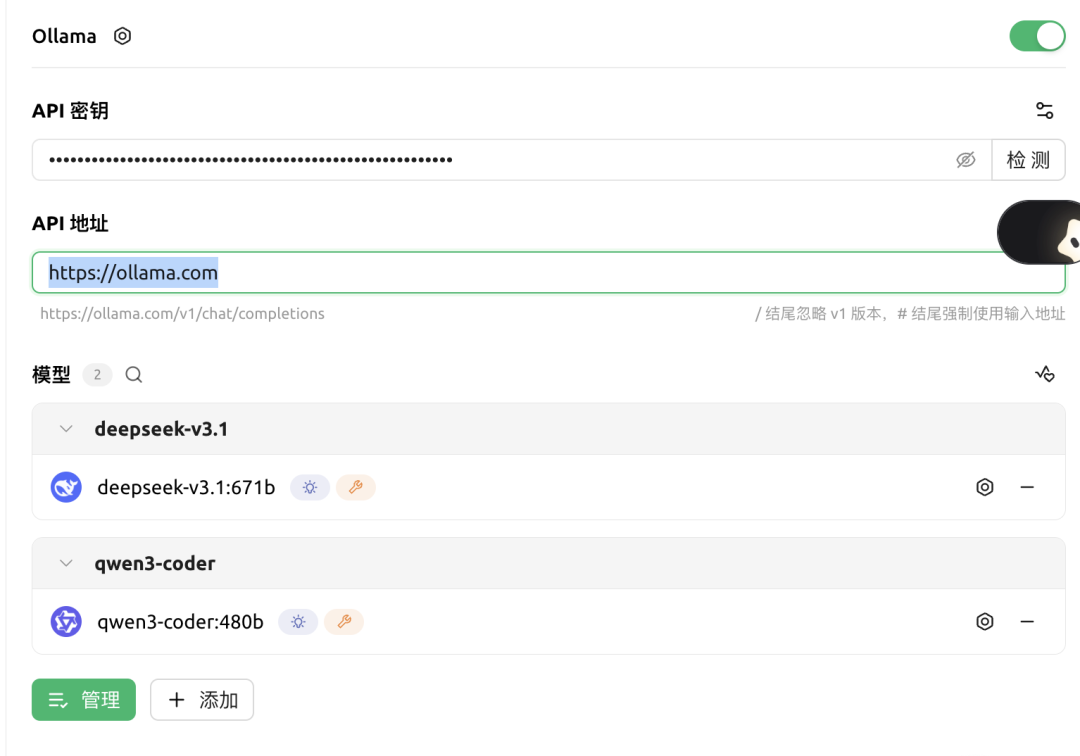
以 Cherry Studio Konfiguration als Beispiel:
- sicher
APIEndpunkte verweisen auf lokaleOllamaBeispiel:http://localhost:11434。 - Geben Sie in der Liste der Modellnamen den Namen des Wolkenmodells ein, das Sie direkt gezogen haben, z. B.
gpt-oss:120b-cloud。 API Keywird in der Regel leer gelassen, da die Authentifizierung bereits erfolgt istollama signinauf dem lokalen Client durchgeführt.
Sobald die Konfiguration abgeschlossen ist, werden Ihre Aufrufe an das Cloud-Modell in diesen Tools lokal erfolgen Ollama Der Client wird automatisch zur Verarbeitung in die Cloud weitergeleitet, und der gesamte Prozess ist für die Anwendung der oberen Schicht völlig transparent.
Strategische Bedeutung und Ausblick
Ollama Cloud Der Start markiert einen bedeutenden Schritt nach vorn in der Nutzbarkeit von Open-Source-KI-Modellen. Sie öffnet nicht nur die Tür zu großen Spitzenmodellen für einzelne Entwickler und Enthusiasten, sondern - was noch wichtiger ist - sie reduziert die Lern- und Migrationskosten für Entwickler, indem sie die Interaktionserfahrung lokalisiert hält.
Der Dienst befindet sich derzeit in der Vorschauphase. Offiziell wird erwähnt, dass es eine vorübergehende Tarifbegrenzung gibt, um die Stabilität des Dienstes zu gewährleisten, und dass für die Zukunft die Einführung eines nutzungsabhängigen Abrechnungsmodells geplant ist. Diese Initiative wird Ollama Es ist als Brücke zwischen lokalen Entwicklungsumgebungen und der Rechenleistung in der Cloud positioniert, so dass es in Verbindung mit dem Groq、Replicate und andere rein cloudbasierte Argumentationsdienste haben einen einzigartigen Vorteil gegenüber der Konkurrenz.

































