



OCRFlux ist ein quelloffenes, leichtgewichtiges Tool, das sich auf die Konvertierung von PDF-Dateien und Bildern in das klare Markdown-Format konzentriert. Es wurde vom ChatDOC-Team entwickelt, basiert auf den 3B-Parametern des multimodalen Modells für den Bau von großen, kann auf gewöhnlicher Hardware wie GTX 3090 laufen. Das Tool kann gut mit komplexen Dokumentenlayouts umgehen, mehrspaltige Formate und komplexe Tabellen genau analysieren und unterstützt die automatische Zusammenführung von Inhalten über mehrere Seiten hinweg. Im Vergleich zu anderen Open-Source-OCR-Modellen zeichnet sich OCRFlux durch seine hohe Genauigkeit aus, insbesondere bei der Verarbeitung von Tabellen und Absätzen. Es bietet eine einfach zu bedienende Kommandozeilenfunktion, die sich für Entwickler, Forscher und Benutzer eignet, die Dokumente in das Markdown-Format konvertieren müssen. Das Projekt ist Open Source auf GitHub unter der Apache 2.0 Lizenz, mit einer aktiven Community und 1,7k Sternen.
Funktionsliste
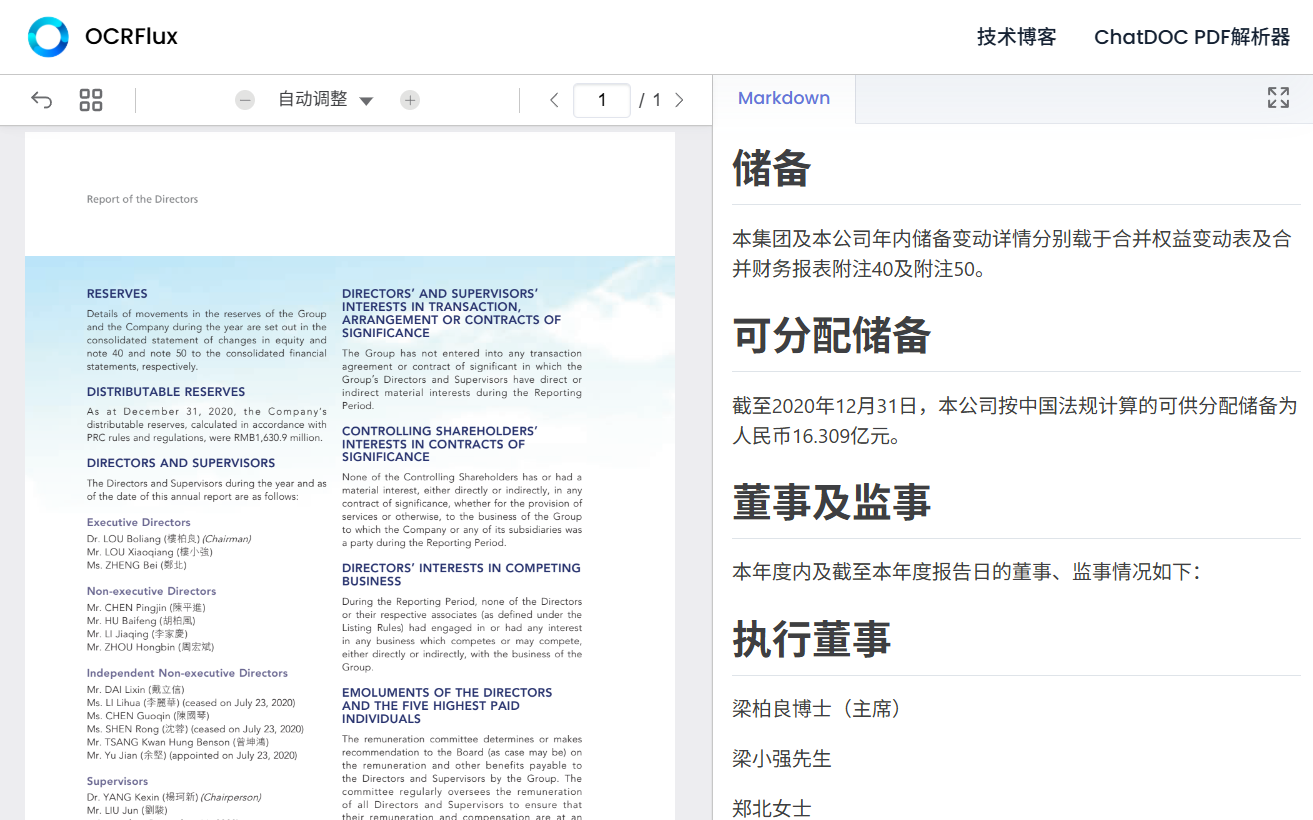
- Konvertieren Sie PDFs und Bilder in das Markdown-Format, wobei die natürliche Lesereihenfolge erhalten bleibt.
- Unterstützung für die Verarbeitung komplexer Layouts, einschließlich mehrspaltiger Dokumente, Abbildungen und eingebetteter Inhalte.
- Analysiert automatisch komplexe Tabellen und unterstützt die Ausgabe von HTML-Tabellen mit rowspan und colspan.
- Die seitenübergreifende Zusammenführung von Inhalten, die automatisch Tabellen und Absätze auf verschiedenen Seiten erkennt und integriert.
- Bietet eine hochpräzise Texterkennung mit einer Edit Distance Similarity (EDS) von bis zu 0,967.
- Basierend auf einem 3B parametrischen multimodalen Modell, das mit dem normalen GPU-Betrieb kompatibel ist.
- Open Source und kostenlos, Code und Dokumentation sind öffentlich auf GitHub verfügbar, und Beiträge der Community werden unterstützt.
Hilfe verwenden
Einbauverfahren
OCRFlux ist ein Docker-basiertes Tool, das zur Installation und Ausführung eine Docker-Umgebung benötigt. Im Folgenden finden Sie die detaillierten Installationsschritte:
- Installation von Docker
Vergewissern Sie sich, dass Docker auf Ihrem System installiert ist; falls nicht, besuchen Sie die Docker-Website, um die entsprechende Version für Ihr Betriebssystem herunterzuladen und zu installieren. Führen Sie nach Abschluss der Installation den folgenden Befehl aus, um sie zu überprüfen:docker --version
- OCRFlux-Spiegel ziehen
Führen Sie den folgenden Befehl in einem Terminal aus, um das neueste OCRFlux-Image von Docker Hub zu beziehen:docker pull chatdoc/ocrflux:latest - Vorbereiten des Dateipfads
Erstellen Sie ein lokales Arbeitsverzeichnis (z. B./path/to/localworkspace) wird verwendet, um Eingabe- und Ausgabedateien zu speichern. Stellen Sie sicher, dass Sie die folgenden Verzeichnisse haben:- Geben Sie das Verzeichnis der PDF-Datei an (z. B.
/path/to/test_pdf_dir)。 - OCRFlux-Modelldateiverzeichnis (z. B.
/path/to/OCRFlux-3B). Die Modelldateien sollten vom offiziellen GitHub-Repository oder über einen von ChatDOC bereitgestellten Link heruntergeladen werden.
- Geben Sie das Verzeichnis der PDF-Datei an (z. B.
- OCRFlux ausführen
Verwenden Sie den folgenden Befehl, um den OCRFlux-Container zu starten, das lokale Verzeichnis zu mounten und die Eingabepfade für PDF und Modell anzugeben:docker run -it --gpus all \ -v /path/to/localworkspace:/localworkspace \ -v /path/to/test_pdf_dir:/test_pdf_dir \ -v /path/to/OCRFlux-3B:/OCRFlux-3B \ chatdoc/ocrflux:latest /localworkspace --data /test_pdf_dir/* --model /OCRFlux-3B/--gpus allAktivieren Sie die GPU-Beschleunigung (entfernen Sie diesen Parameter, wenn keine GPU vorhanden ist).-vMounte ein lokales Verzeichnis in den Container.--data: Geben Sie den Pfad zur PDF-Eingabedatei an.--model: Gibt den Pfad der Modelldatei an.
- Erzeugen von Markdown-Dateien
Wenn der Lauf abgeschlossen ist, wird die Markdown-Ausgabedatei in der Datei./localworkspace/markdowns/DOCUMENT_NAMEVerzeichnis. Verwenden Sie den folgenden Befehl, um das JSONL-Format in Markdown zu konvertieren:python -m ocrflux.jsonl_to_markdown ./localworkspace
Verwendungsprozess
Die Kernfunktion von OCRFlux ist die Konvertierung von PDFs oder Bildern in Markdown, hier die einzelnen Schritte:
- Vorbereiten der Eingabedatei
Platzieren Sie die PDF-Datei oder das Bild, das konvertiert werden soll, in/path/to/test_pdf_dirKatalog. Unterstützung für gängige PDF-Formate und Bildformate (z.B. PNG, JPG). - Führen Sie die Konvertierungsaufgabe aus
Verwenden Sie die oben genannten Docker-Befehle, um die Konvertierung zu starten. ocRFlux analysiert automatisch das Dokumentenlayout und identifiziert Text, Tabellen und seitenübergreifende Inhalte. Der Konvertierungsprozess kann einige Minuten dauern, je nach Dateigröße und Hardwareleistung. - Überprüfung der Ausgabe
Nachdem die Konvertierung abgeschlossen ist, öffnen Sie die./localworkspace/markdowns/DOCUMENT_NAMEKatalog, um die generierten Markdown-Dateien anzuzeigen. Die Datei behält die natürliche Lesereihenfolge des Dokuments bei, und Tabellen werden im Markdown- oder HTML-Format wiedergegeben. - Handhabung komplexer Formulare
OCRFlux kann komplexe Tabellen mit rowspan und colspan verarbeiten. Die resultierende Markdown-Datei strukturiert die Tabelle in ein klares Format, das sich zur direkten Bearbeitung oder zum Import in andere Tools eignet. - Seitenübergreifende Zusammenführung von Inhalten
Bei Tabellen oder Absätzen, die sich über mehrere Seiten erstrecken, erkennt OCRFlux den Inhalt automatisch und führt ihn zusammen. So werden beispielsweise Tabellen, die sich über zwei Seiten erstrecken, zu einer vollständigen Tabelle zusammengefasst und Absätze in einer logischen Reihenfolge zusammengefügt.
Featured Function Bedienung
- Komplexe Layout-VerarbeitungOCRFlux unterstützt das Parsen von mehrspaltigen Dokumenten und eingebetteten Abbildungen. Zur Laufzeit ist keine zusätzliche Konfiguration erforderlich, und das Tool erkennt die Dokumentstruktur automatisch.
- Hochpräzise ErkennungIm OCRFlux-Bench-Single-Test erreicht das Tool einen EDS-Wert von 0,967 und übertrifft damit olmOCR-7B (0,872), Nanonets-OCR-s (0,858) und MonkeyOCR (0,780).
- seitenübergreifende ZusammenführungDies ist eine einzigartige Funktion von OCRFlux. Das Tool analysiert aufeinanderfolgende Seiten, erkennt Tabellen oder Absätze, die zusammengeführt werden müssen, und gibt den vollständigen Inhalt aus.
caveat
- Vergewissern Sie sich, dass die eingegebenen PDF-Dateien lesbar sind und dass die empfohlene Auflösung der Scans höher als 300 DPI ist.
- Wenn der Grafikprozessor nicht verfügbar ist, kann die Konvertierung langsam sein, und es wird eine leistungsstarke CPU empfohlen.
- Überprüfen Sie die Integrität der Modelldateien, fehlende Dateien können zu einem Konvertierungsfehler führen.
- Besuchen Sie das GitHub-Repository regelmäßig, um die neueste Version und Anweisungen zur Aktualisierung zu erhalten.
Anwendungsszenario
- akademische Forschung
OCRFlux verarbeitet mehrspaltige Layouts und komplexe Tabellen und gewährleistet eine klare Formatierung von Formeln und Referenzen. - Technische Dokumentation
Entwickler können technische Handbücher oder API-Dokumentation von PDF in Markdown konvertieren, um sie in eine Wissensdatenbank oder einen Blog zu importieren. Zusammenführen von Seiten, um Fragmentierung zu vermeiden. - Bearbeitung von Rechnungen und Formularen
Mitarbeiter der Finanzabteilung können Rechnungen oder PDF-Formulare in Markdown konvertieren und dabei wichtige Informationen wie Käufer, Stückpreis und Preis-/Steuersummen für eine einfache Datenanalyse extrahieren. - Ersteller von Inhalten
Ersteller können gescannte Bücher oder Notizen in das Markdown-Jellybean-Format konvertieren und in veröffentlichungsfähige Markdown-Dateien umwandeln, die direkt auf Websites oder in Dokumenten verwendet werden können.
QA
- Welche Dateiformate werden von OCRFlux unterstützt?
Es unterstützt PDF und gängige Bildformate (z. B. PNG, JPG). Die Eingabedateien müssen eindeutige Dokumente oder Scans sein. - Sie brauchen leistungsstarke Hardware?
Nein. OCRFlux basiert auf einem 3B-Parametermodell und kann auf einem normalen Grafikprozessor (z. B. GTX 3090) oder einer Hochleistungs-CPU ausgeführt werden. - Wie gehe ich mit seitenübergreifenden Formularen um?
OCRFlux erkennt automatisch seitenübergreifende Tabellen und Absätze und führt sie zusammen, um das vollständige Markdown-Format ohne manuellen Eingriff auszugeben. - Was ist, wenn die Umrechnungsergebnisse ungenau sind?
Überprüfen Sie die Auflösung der Eingabedatei (300 DPI oder höher wird empfohlen). Wenn das Problem weiterhin besteht, reichen Sie ein Problem auf GitHub ein, um Hilfe von der Community zu erhalten. - Muss es zum Betrieb vernetzt sein?
OCRFlux wird in einer lokalen Docker-Umgebung ausgeführt und die Modelle und Daten werden offline verarbeitet.































