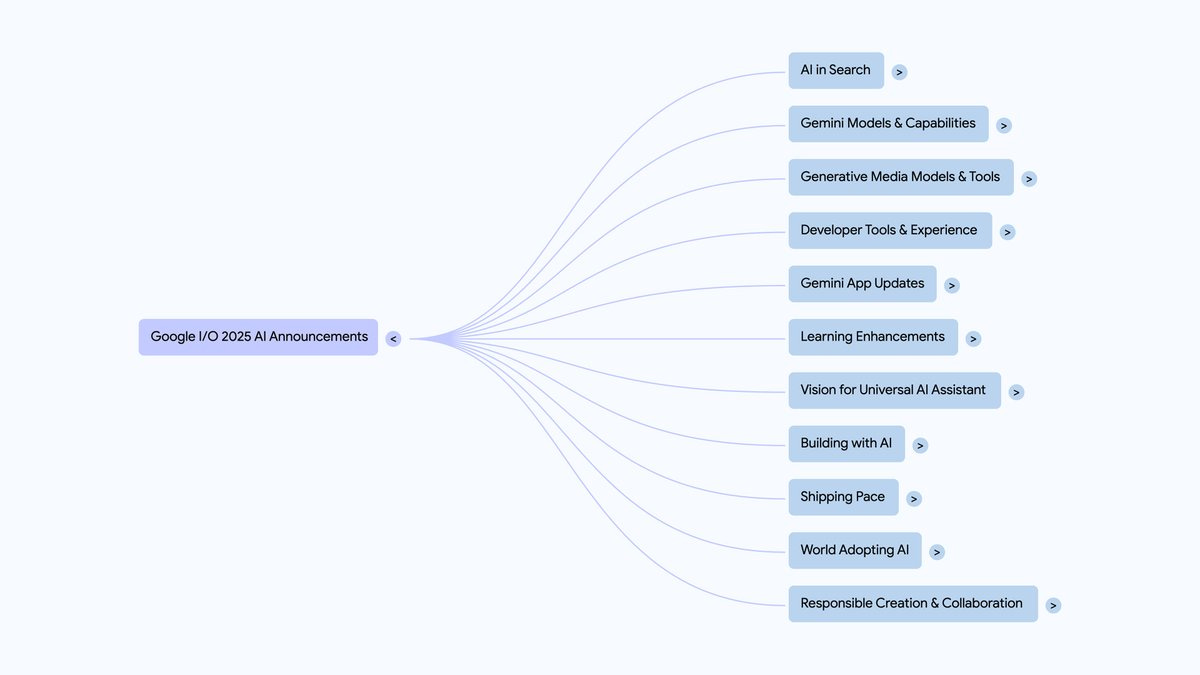
Transformatoren.js 是 Hugging Face 提供的一个 JavaScript 库,旨在将最先进的机器学习模型直接在浏览器中运行,无需服务器支持。该库与 Hugging Face 的 Python 版 transformers 库功能相当,支持多种预训练模型和任务,包括自然语言处理、计算机视觉和音频处理等。该项目中的 “llama-3.2-reasoning-webgpu” 示例旨在演示 LLama-3.2 模型在 WebGPU 上的推理能力,允许用户在浏览器中直接体验高效的语言模型推理。这个示例不仅展示了技术的先进性,还提供了如何利用现代浏览器的计算能力来处理复杂的 AI 任务。
Funktionsliste
- Ausführen des LLama-3.2-Modells in einem BrowserLeveraging WebGPU technology for efficient model inference.
- Demonstration der WebGPU-LeistungHervorhebung der Überlegenheit von WebGPUs durch Vergleich der Leistung auf verschiedenen Geräten.
- Bieten Sie eine interaktive BenutzererfahrungBenutzer können über eine einfache Schnittstelle mit dem Modell interagieren, Text eingeben und die Ergebnisse des Modells abrufen.
- Codebeispiele und TutorialsEnthält vollständige Code-Beispiele und Anweisungen zur Einrichtung und Ausführung des LLama-3.2-Modells.
Hilfe verwenden
Installations- und Konfigurationsumgebung
Da dieses Beispiel in einer Browserumgebung ausgeführt wird, sind keine besonderen Installationsschritte erforderlich, aber Sie müssen sicherstellen, dass Ihr Browser WebGPU unterstützt:
- Überprüfung der Browserunterstützung::
- Wenn Sie die Beispielseite öffnen, prüft der Browser automatisch, ob WebGPU unterstützt wird. Ist dies nicht der Fall, zeigt die Seite eine entsprechende Aufforderung an.
- WebGPU wird derzeit von den neuesten Versionen von Chrome, Edge und Firefox unterstützt. Für Safari-Nutzer müssen möglicherweise bestimmte experimentelle Funktionen aktiviert werden.
- Besuchen Sie die Musterseite::
- Direkter Zugriff über einen Link auf GitHub
llama-3.2-reasoning-webgpuDie Beispielseite der
- Direkter Zugriff über einen Link auf GitHub
Anwendungsbeispiel
- Modelle laden::
- Sobald die Seite geladen ist, wird sie automatisch mit dem Laden des LLama-3.2-Modells beginnen. Der Ladevorgang kann einige Minuten dauern, abhängig von Ihrer Internetgeschwindigkeit und der Leistung Ihres Geräts.
- Eingabetext::
- Sobald die Seite geladen ist, sehen Sie ein Texteingabefeld. Geben Sie in dieses Feld den Text ein, über den Sie nachdenken möchten.
- Prozess der Argumentation::
- Klicken Sie auf die Schaltfläche "Reasoning" und das Modell beginnt mit der Verarbeitung Ihrer Eingaben. Bitte beachten Sie, dass der Reasoning-Prozess je nach Länge und Komplexität des Textes einige Zeit dauern kann.
- Ergebnisse anzeigen::
- Die Ergebnisse werden in einem weiteren Textfeld auf der Seite angezeigt. Das LLama-3.2-Modell generiert Schlussfolgerungsergebnisse auf der Grundlage Ihrer Eingabe, die eine Antwort auf eine Frage, eine Übersetzung oder eine andere Form der Verarbeitung des Textes sein kann.
- Fehlersuche und Leistungsüberwachung::
- Beim Reasoning kann die Seite Leistungsstatistiken wie die Geschwindigkeit des Reasonings (Token pro Sekunde, TPS) anzeigen. Dies hilft Ihnen, die Fähigkeiten der WebGPU und die Leistung des aktuellen Geräts zu verstehen.
Weitere Studien und Erkundungen
- Quellcode-StudieSie können dies tun, indem Sie sich den Quellcode auf GitHub ansehen (insbesondere die
worker.jsDatei), um einen Einblick in die Funktionsweise des Modells im Browser zu erhalten. - Änderungen und BeiträgeWenn Sie interessiert sind, können Sie dieses Projekt klonen, um Änderungen vorzunehmen oder neue Funktionen beizusteuern. Das Projekt verwendet die Reagieren Sie und Vite-Builds, und wenn Sie mit diesen Tools vertraut sind, können Sie relativ einfach entwickeln.
caveat
- Browser-KompatibilitätVergewissern Sie sich, dass Ihr Browser auf dem neuesten Stand ist, um eine optimale Nutzung zu gewährleisten.
- LeistungsabhängigkeitDa die Inferenz auf der Client-Seite stattfindet, wird die Leistung durch die Gerätehardware (insbesondere die GPU) beeinflusst.
- PrivatwirtschaftAlle Daten werden lokal verarbeitet und nicht auf einen Server hochgeladen, wodurch die Privatsphäre der Nutzerdaten geschützt wird.
Mit diesen Schritten und Anweisungen können Sie dieses Beispielprojekt vollständig erforschen und nutzen, um die Fortschritte der KI-Technologie in Ihrem Browser zu erleben.
Darf nicht ohne Genehmigung vervielfältigt werden:Leiter des AI-Austauschkreises " Llama 3.2 Reasoning WebGPU: Ausführen von Llama-3.2 in einem Browser