



MOSS-TTSD ist ein Open-Source-Modell zur Erzeugung von Dialogsprache, das chinesische und englische Zweisprachigkeit unterstützt. Es kann Zwei-Personen-Dialogtext in natürliche und ausdrucksstarke Sprache umwandeln, die sich für die Produktion von KI-Podcasts, Sprachforschung usw. eignet. Das Modell basiert auf einer Low-Bit-Codierungstechnologie und unterstützt das Klonen von Null-Samples und die Single-Shot-Sprachgenerierung von bis zu 960 Sekunden. Das Modell basiert auf einer Kodierungstechnologie mit niedriger Bitrate und unterstützt das Klonen von Zwei-Personen-Sprache ohne Stichproben und die Generierung von Sprache in einer einzigen Aufnahme mit einer Dauer von bis zu 960 s. MOSS-TTSD stellt die vollständigen Modellgewichte und den Inferenzcode zur Verfügung und ist für die kommerzielle Nutzung kostenlos. Die neueste Version, derzeit v0.5, ist über GitHub verfügbar und optimiert das Timbre Switching und die Modellstabilität.
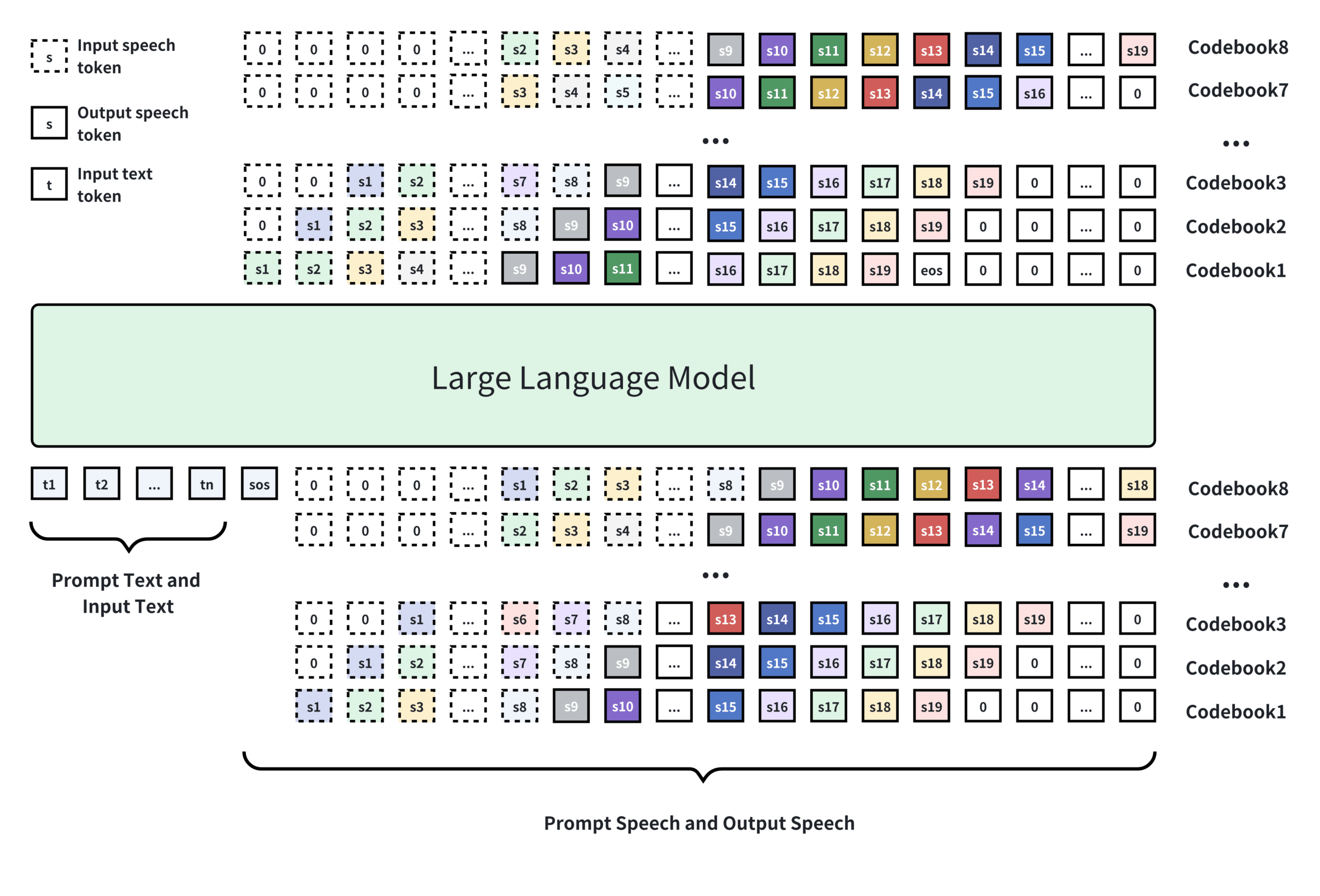
Funktionsliste
- Unterstützt zweisprachige Dialogstimmerzeugung, Ausgabe natürlicher und ausdrucksstarker Stimmen.
- Ermöglicht das Klonen von Zwei-Personen-Sprache ohne Probenahme und die genaue Unterscheidung zwischen verschiedenen Sprechern in einem Dialog.
- Unterstützt die Generierung von Einzelsprachnachrichten mit einer Länge von bis zu 960 Sekunden, geeignet für Podcasts oder die Produktion von Langform-Inhalten.
- Bietet Podever, ein Tool zur Erstellung von Podcasts, das PDFs, URLs oder lange Texte in hochwertige Podcasts verwandelt.
- Open-Source-Modellgewichte, Inferenzcode und API-Schnittstellen mit kostenloser kommerzieller Unterstützung.
- Bereitstellung von Skripten zur Modellfeinabstimmung, Unterstützung der vollständigen Modellfeinabstimmung und LoRA-Feinabstimmung, Anpassung an benutzerdefinierte Datensätze.
Hilfe verwenden
Einbauverfahren
Die Installation von MOSS-TTSD muss in einer Umgebung durchgeführt werden, die Python unterstützt. Im Folgenden werden die einzelnen Installationsschritte beschrieben:
- Erstellen einer virtuellen Umgebung
Erstellen Sie eine separate Python-Umgebung mit conda oder pip und achten Sie darauf, dass Sie andere Projekte nicht beeinträchtigen. Wir empfehlen die Verwendung von Python 3.10. Führen Sie den folgenden Befehl aus:conda create -n moss_ttsd python=3.10 -y conda activate moss_ttsd
- Klonen der Codebasis
Laden Sie die MOSS-TTSD-Codebasis von GitHub herunter. Öffnen Sie ein Terminal und führen Sie es aus:git clone https://github.com/OpenMOSS/MOSS-TTSD.git cd MOSS-TTSD - Installation von Abhängigkeiten
Die Codebase enthält einerequirements.txtDatei, die die erforderlichen Abhängigkeiten auflistet. Installieren Sie die Abhängigkeiten:pip install -r requirements.txt pip install flash-attnAchtung!
flash-attnist eine Bibliothek zur Beschleunigung des Aufmerksamkeitsmechanismus, der von der GPU-Umgebung unterstützt werden muss. - Download Modellgewichte
Modellgewichte für MOSS-TTSD können von Hugging Face oder der GitHub Release-Seite heruntergeladen werden. Die empfohlene Version ist v0.5. Legen Sie die heruntergeladenen Modellgewichte in das Stammverzeichnis des Projekts oder in einen angegebenen Pfad. - Überprüfen der Installation
Führen Sie das Beispielskript aus, um zu prüfen, ob die Umgebung korrekt konfiguriert ist:python demo.pyBei Erfolg wird eine einfache Dialog-Sprachdatei erzeugt.
Hauptfunktionen
1. die Erzeugung von Dialogstimmen
Die Hauptfunktion von MOSS-TTSD ist die Umwandlung von Dialogtext in Sprache. Der Benutzer muss eine Textdatei vorbereiten, die einen Dialog zwischen zwei Personen im Format des Beispiels enthält:
Speaker1: 你好,今天天气怎么样?
Speaker2: 很好,阳光明媚!
Führen Sie das Inferenzskript aus, um Sprache zu erzeugen:
python inference.py --model_path <path_to_model> --input_text <path_to_text_file> --output_dir <output_directory>
Gibt eine Sprachdatei im WAV-Format aus, die automatisch die Töne der beiden Sprecher unterscheidet.
2. das Klonen von Stimmen
MOSS-TTSD unterstützt das Klonen von Sprache ohne Samples. Der Benutzer stellt ein Audiostück (mindestens 10 Sekunden) des Zielsprechers zur Verfügung, und das Modell kann die Dialogstimme dieser Klangfarbe erzeugen. Arbeitsschritte:
- Bereiten Sie die Ziel-Audiodatei vor (z. B.
speaker1.wav和speaker2.wav)。 - Ändern Sie die Konfigurationsdatei
config.yamlgeben Sie den Audiopfad an:speaker1: path/to/speaker1.wav speaker2: path/to/speaker2.wav - Führen Sie das Klon-Skript aus:
python clone_voice.py --config config.yaml --input_text dialogue.txt --output_dir cloned_output
3. die Erstellung von Podcasts (Podever)
Podever ist das Podcast-Generierungswerkzeug von MOSS-TTSD, das lange Texte, PDFs oder URLs in Podcasts verwandelt. Schritte der Bedienung:
- Installieren Sie die Podever-Erweiterung:
pip install podever - Bereiten Sie die Eingabedatei vor (z. B. PDF oder URL).
- Befehl ausführen:
python podever.py --input <input_file_or_url> --output podcast.wav
Podever extrahiert automatisch Text und generiert Podcasts im Stil eines Zweipersonendialogs, die sich für populärwissenschaftliche Inhalte oder vorgelesene Bücher eignen.
4. die Feinabstimmung des Modells
Der Benutzer kann das Modell mithilfe eines benutzerdefinierten Datensatzes feinabstimmen. Die Schritte sind wie folgt:
- Bereiten Sie den Datensatz im JSON-Format vor, der den Dialogtext und das entsprechende Audio enthält.
- Führen Sie das Feinabstimmungsskript aus:
python finetune/finetune.py --model_path <path_to_model> --data_dir <path_to_processed_data> --output_dir <output_directory> --training_config <training_config_file> - Unterstützt die LoRA-Feinabstimmung, um den Bedarf an Rechenressourcen zu reduzieren:
python finetune/finetune.py --model_path <path_to_model> --data_dir <path_to_processed_data> --output_dir <output_directory> --training_config <training_config_file> --lora_config <lora_config_file>
caveat
- Stellen Sie sicher, dass der DNSMOS-Wert des Eingangssignals ≥ 2,8 ist, um die Klangqualität zu gewährleisten.
- Das Modell reagiert möglicherweise nicht empfindlich genug auf kurze Dialogwiedergaben (z. B. "ähm", "oh"), und es wird empfohlen, den Sprecher im Text ausdrücklich zu kennzeichnen.
- Erfordert mindestens 12 GB GPU-Speicher zur Ausführung, NVIDIA-GPUs werden empfohlen.
Anwendungsszenario
- AI-Podcast-Produktion
MOSS-TTSD verwandelt Artikel, Bücher oder Webinhalte in Podcasts mit Zweipersonendialogen. Die Benutzer müssen nur den Text bereitstellen, und das Podever-Tool generiert natürliche, flüssige Audios für Self-Publishing-Autoren, die schnell Inhalte produzieren können. - Tools zum Sprachenlernen
Lehrer können MOSS-TTSD verwenden, um zweisprachige Dialoge zu erzeugen, mit denen die Schüler das Hören und Sprechen üben können. Die Funktion zum Klonen von Stimmen kann das Timbre echter Menschen simulieren, um den Spaß am Lernen zu erhöhen. - Hilfe bei der Erreichbarkeit
MOSS-TTSD erzeugt Hörbücher oder unterhaltsame Nachrichtensendungen für sehbehinderte Menschen. Die Erzeugung langer Sprache unterstützt die Ausgabe ganzer Kapitel auf einmal, wodurch die Häufigkeit der Bedienung reduziert wird. - akademische Forschung
Forscher können die Vorteile des Open-Source-Charakters von MOSS-TTSD nutzen, um Sprachsynthesetechniken zu erforschen. Das Modell unterstützt die Feinabstimmung und eignet sich für die Entwicklung maßgeschneiderter Sprachanwendungen.
QA
- Welche Sprachen werden von MOSS-TTSD unterstützt?
Unterstützt derzeit die zweisprachige Dialogerstellung in Chinesisch und Englisch, mit der Möglichkeit der Erweiterung auf weitere Sprachen in der Zukunft. - Wie kann die Qualität der Spracherzeugung verbessert werden?
Verwenden Sie eine hohe Audioqualität (DNSMOS ≥ 2.8) und stellen Sie sicher, dass der Dialogtext den Sprecher eindeutig bezeichnet. Die Feinabstimmung des Modells kann die Ergebnisse weiter verbessern. - Ist sie im Handel erhältlich?
Ja, MOSS-TTSD ist unter der Apache 2.0-Lizenz lizenziert und unterstützt die freie kommerzielle Nutzung, vorbehaltlich der Einhaltung rechtlicher und ethischer Vorgaben. - Welche Hardware ist für die Ausführung des Modells erforderlich?
Empfohlen werden NVIDIA-Grafikprozessoren mit mindestens 12 GB Videospeicher. CPUs können langsamer arbeiten und werden für Produktionsumgebungen nicht empfohlen.





























