


Aus Paris. Mistral AI Wieder einmal hat das Unternehmen mit seiner charakteristischen Open-Source-Strategie einen wichtigen Baustein in den Bereich der künstlichen Intelligenz eingebracht - dieVoxtral Audio-Modellierung. Die Familie, die als OpenAI Der stärkste Wettbewerber in Europa, die Einführung des Voxtral Es ist kein reines Sprachtranskriptionstool, sondern erweitert seine leistungsstarken Sprachmodellierungsfähigkeiten auf den Audiobereich und zielt darauf ab, eine sofort einsatzbereite und kostengünstige Sprachverarbeitungslösung für kommerzielle Anwendungen zu bieten.
Voxtral Diese Strategie, die zwei sehr unterschiedliche Versionen des Modells anbietet, zeigt deutlich die Ambitionen des Unternehmens auf dem Markt. Die eine besteht aus 24B Zusammenstellung von Parametern für eine schwergewichtige Version, die für Produktionsumgebungen entwickelt wurde, in denen große Datenmengen verarbeitet werden müssen; eine weitere 3B parametrisch Mini Versionen, die auf ressourcenbeschränkte lokale und Edge-Computing-Szenarien ausgerichtet sind. Beide Versionen sind verfügbar in Apache 2.0 Offen unter Lizenz, was bedeutet, dass Unternehmen und Entwickler die Software nicht nur kostenlos herunterladen, verändern und einsetzen können, sondern auch die mit der kommerziellen Nutzung verbundenen Probleme loswerden.
Mehr als Hören: Eingebautes Verstehen und mehrsprachige Vorteile
与 OpenAI 的 Whisper Im Gegensatz zu Modellen, die sich auf hochpräzise Sprachtranskription (ASR) konzentrieren, wie dasVoxtral Die Hauptstärke der Software liegt in den integrierten Funktionen zum Verstehen natürlicher Sprache (NLU). Es basiert auf Mistral Small 3.1 Das Sprachmodell ist so konstruiert, dass es leistungsstarke Textverarbeitungsfunktionen erbt. Dies bedeutet, dass die Benutzer keine komplexen Verarbeitungsverbindungen zwischen Sprache, Text und Sprachmodellen mehr herstellen müssen, sondern direkt Fragen stellen, Zusammenfassungen erstellen oder strukturierte Informationen aus Audiodateien extrahieren können. Zum BeispielVoxtral Die Fähigkeit, bis zu 30 Minuten Audiotranskription oder 40 Minuten Audioverstehensaufgaben zu bewältigen, wird ermöglicht durch seine 32k Das Kontextfenster des Tokens ist entscheidend für die Handhabung von Szenarien wie Konferenzaufzeichnungen und langen Interviews.
Im Bereich der mehrsprachigen Unterstützung.Voxtral Es zeichnet sich auch besonders durch die Unterstützung europäischer Sprachen aus. Offizielle Benchmarks zeigen, dass es Englisch, Französisch, Deutsch, Spanisch und Italienisch unterstützt. Diese Eigenschaft verschafft ihm einen natürlichen Vorteil bei der Verarbeitung von Audiodaten für internationale Geschäfte.
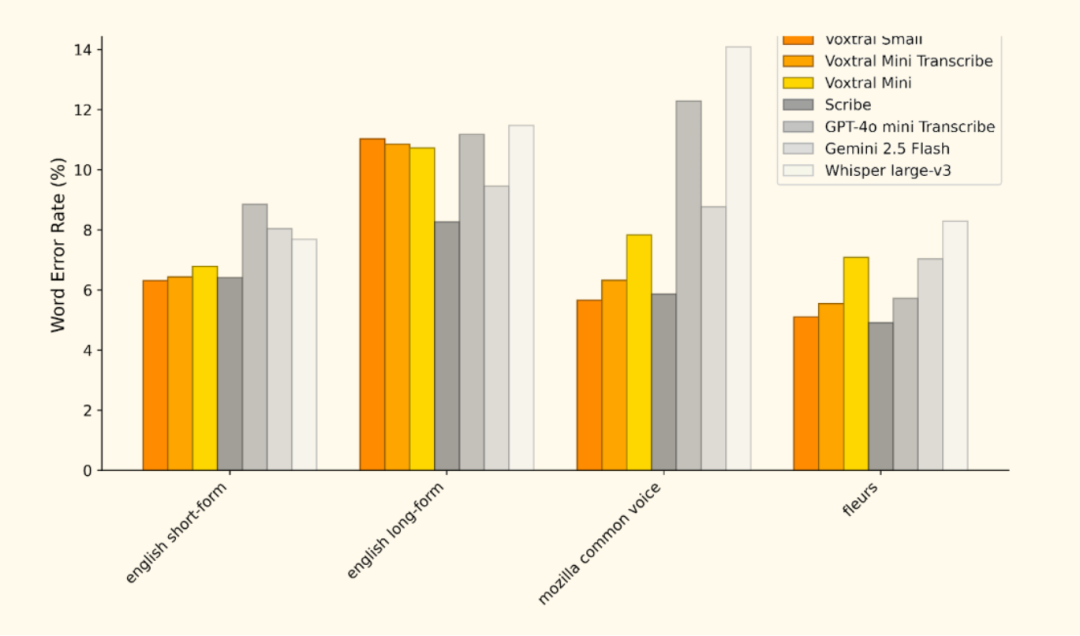
Anwendungsszenarien: von der Cloud zum Edge
Voxtral Das Anwendungspotenzial deckt ein breites Spektrum von Szenarien ab, von der Cloud bis zum Edge:
- KundenbetreuungAutomatische Transkription von Kundendienstanrufen und direkte Erstellung von Arbeitsaufträgen oder Zusammenfassungen zur Verbesserung der Reaktionsfähigkeit.
- Erstellung von InhaltenSchnelles Umwandeln von Podcasts und Interviews in Transkripte mit der Möglichkeit, die Kernideen sofort zu destillieren.
- Analyse der SitzungenAufzeichnung und Erstellung von Besprechungsprotokollen in Echtzeit mit Extraktion der wichtigsten Entscheidungen und Aufgaben.
- Edge IntelligenceEinsatz in IoT-Geräten wie intelligenten Häusern und Fahrzeugsystemen
Voxtral MiniDie neueste Ergänzung der Liste ist eine neue Sprachschnittstelle, die eine lokale Sprachinteraktion ohne Internetverbindung ermöglicht.
Schnellstart-Anleitung
Mistral AI Bietet die Möglichkeit, sich über die Cloud mit dem Internet zu verbinden API oder lokal eingesetzt werden, wobei sowohl Voxtral。
(i) Verabschiedung Mistral AI fig. hoch in den Wolken API
Für Entwickler, die eine schnelle Integration suchen, können Sie die offizielle API. Erstens, in Mistral AI Registrieren Sie sich auf der Plattform und erhalten Sie API und übergeben Sie dann die Taste mistralai Python-Clients können sie aufrufen.
(ii) Lokaler Einsatz (vLLM (Empfohlen)
Für Szenarien, die Datenschutz oder Offline-Betrieb erfordern, ist die lokale Bereitstellung die bessere Wahl. Offiziell empfohlen vLLM Rahmen, da er einen Rahmen für die Voxtral Leistungsstarke Inferenzunterstützung wird geboten.
1. die Installationsumgebung
Stellen Sie zunächst sicher, dass Sie Folgendes installiert haben Python Umgebung, und übergeben Sie dann die pip Montage vLLM und die damit verbundenen Abhängigkeiten.
uv pip install -U "vllm
" --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
2. die Aufnahme lokaler Dienste
Verwenden Sie den folgenden Befehl aus dem Hugging Face Laden Sie das Modell herunter und starten Sie eine Anwendung mit dem OpenAI Kompatible lokale Dienste.
python -m vllm.entrypoints.openai.api_server \
--model mistralai/Voxtral-Mini-3B-v0.1 \
--tokenizer-id mistralai/Mistral-7B-Instruct-v0.3 \
--enable-chunked-prefill
3. lokale Dienste anrufen
Nachdem der Dienst gestartet ist, können Sie die OpenAI Client-Bibliothek oder die curl mit dem lokal laufenden Voxtral Modelle zu interagieren. Es folgt eine Beschreibung der Verwendung des Python Beispiele für die Durchführung der Transkription und des Verstehens von Sprache.
- Sprachtranskription
from openai import OpenAI
from huggingface_hub import hf_hub_download
# 配置客户端指向本地vLLM服务
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="vllm" # 本地服务不需要真实密钥
)
# 下载示例音频
audio_file_path = hf_hub_download(
repo_id="patrickvonplaten/audio_samples",
filename="obama.mp3",
repo_type="dataset"
)
# 发起转录请求
with open(audio_file_path, "rb") as audio_file:
transcription = client.audio.transcriptions.create(
model="mistralai/Voxtral-Mini-3B-v0.1",
file=audio_file,
language="en"
)
print(transcription.text)
- Sprachverstehen (Q&A)
from openai import OpenAI
from huggingface_hub import hf_hub_download
import base64
# 配置客户端
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="vllm"
)
# 下载并编码音频文件
def encode_audio_to_base64(filepath):
with open(filepath, 'rb') as audio_file:
return base64.b64encode(audio_file.read()).decode('utf-8')
obama_file = hf_hub_download("patrickvonplaten/audio_samples", "obama.mp3", repo_type="dataset")
bcn_file = hf_hub_download("patrickvonplaten/audio_samples", "bcn_weather.mp3", repo_type="dataset")
obama_base64 = encode_audio_to_base64(obama_file)
bcn_base64 = encode_audio_to_base64(bcn_file)
# 构建包含音频和文本的多模态消息
response = client.chat.completions.create(
model="mistralai/Voxtral-Mini-3B-v0.1",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这是两段音频。第一段是一位著名人物的演讲,第二段是天气预报。请问,哪一段演讲更有启发性?为什么?"},
{"type": "image_url", "image_url": {"url": f"data:audio/mpeg;base64,{obama_base64}"}},
{"type": "image_url", "image_url": {"url": f"data:audio/mpeg;base64,{bcn_base64}"}}
]
}
],
temperature=0.2
)
print(response.choices.message.content)
Projektressourcen
- Offizieller Blog: https://mistral.ai/news/voxtral/
- Modell Download: https://huggingface.co/mistralai/Voxtral-Mini-3B-2507





































