



MCPMark ist ein Benchmark-Test zur Bewertung der Fähigkeiten großer Modellintelligenzen (Agentic). Er misst den Grad der Autonomie eines Modells bei der Planung, Argumentation und Ausführung komplexer Aufgaben durch Stresstests in einer Reihe von realen Softwareumgebungen, die das Model Context Protocol (MCP) integrieren. Die Testumgebungen umfassen eine breite Palette von Mainstream-Tools wie Notion, GitHub, Dateisysteme, Postgres-Datenbanken und Playwright. Das für Forscher und Ingenieure konzipierte Projekt bietet eine objektive und zuverlässige Bewertungsplattform durch einen sicheren Sandbox-Mechanismus, reproduzierbare automatisierte Aufgaben und einheitliche Bewertungsmetriken.
Funktionsliste
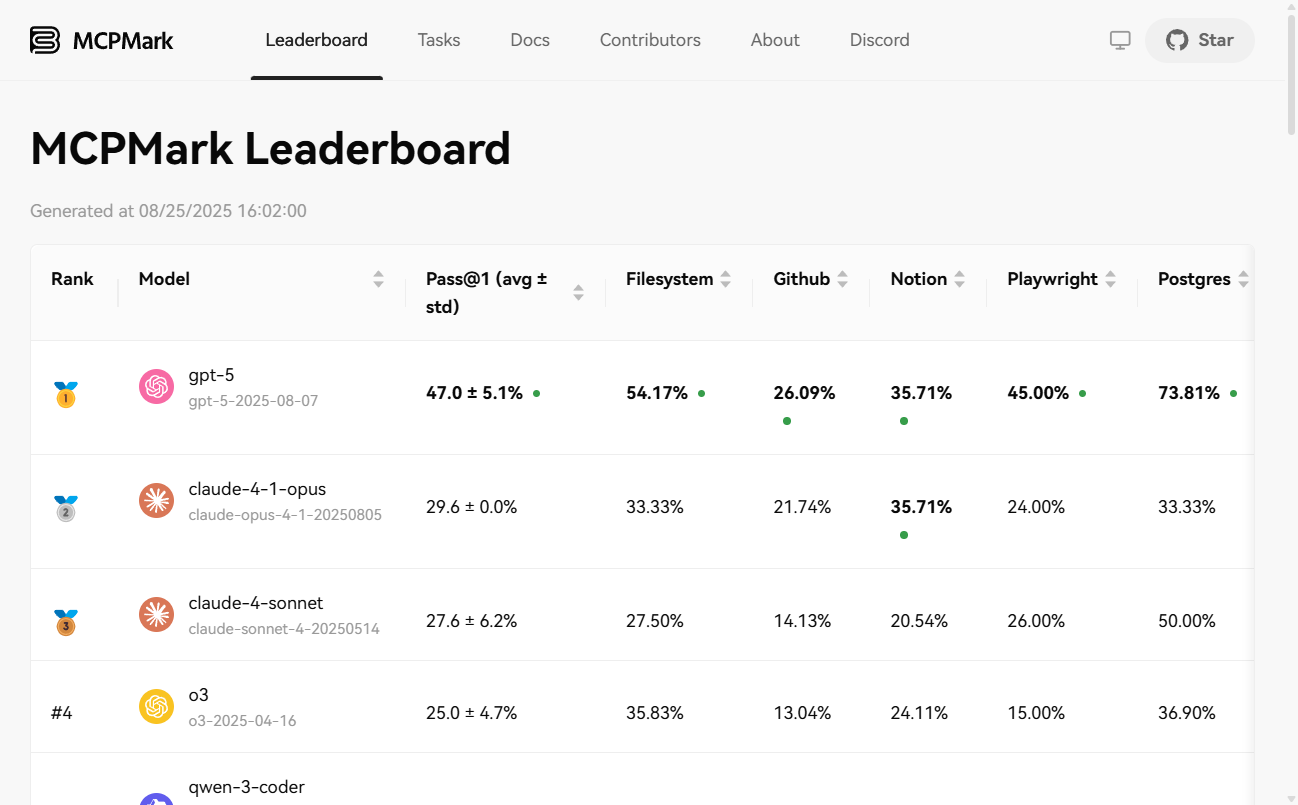
- Vielseitige TestumgebungenUnterstützung beim Testen in sechs realistischen und komplexen Softwareumgebungen, darunter
Notion、GitHub、Filesystem、Postgres、Playwright和Playwright-WebArena。 - Automatisierte Aufgabenvalidierung:: Jede Testaufgabe wird von einem strengen automatischen Validierungsskript begleitet, das eine objektive und reproduzierbare Bewertung der Aufgabenerfüllung ermöglicht.
- Sicherer Sandboxing-MechanismusAlle Aufgaben werden in einer separaten Sandbox-Umgebung ausgeführt, die am Ende der Aufgabe zerstört wird, ohne dass die persönlichen Daten des Benutzers nach außen dringen oder kontaminiert werden.
- Nichterneuerung der automatischen VerlängerungWenn ein Experiment durch einen Pipeline-Fehler (z. B. eine Netzwerkschwankung) unterbrochen wird, wird die abgeschlossene Aufgabe automatisch übersprungen, und die zuvor fehlgeschlagene Aufgabe wird bei der erneuten Durchführung des Experiments erneut versucht.
- Reiche Palette von Bewertungsindikatoren:: Unterstützung für die Erstellung mehrerer aggregierter Metriken, einschließlich
pass@1、pass@K、pass^K和avg@Kdie ein umfassendes Maß für die einmalige Erfolgsquote und die Stabilität des Modells über mehrere Versuche hinweg darstellt. - Flexible EinsatzmöglichkeitenUnterstützt die lokale (macOS, Linux) Installation über Pip und bietet auch Docker-Images für die schnelle Bereitstellung und den Betrieb.
Hilfe verwenden
Die Anwendung des MCPMark-Bewertungsmodells erfolgt in der Regel in den folgenden vier Schritten:
1. die Installation von MCPMark
Sie haben die Wahl zwischen einer lokalen Installation oder der Verwendung von Docker.
Lokale Installation (Pip).
# 从GitHub克隆仓库
git clone https://github.com/eval-sys/mcpmark.git
cd mcpmark
# 安装依赖
pip install -e .
Docker安装:
# 克隆仓库后,直接构建Docker镜像
./build-docker.sh```
### **2. 授权服务**
如果你需要测试GitHub或Notion相关的任务,你需要先根据官方文档进行授权,让MCPMark能够以编程方式访问这些服务。
### **3. 配置环境变量**
在项目根目录创建一个名为<code>.mcp_env</code>的文件,并填入你需要的模型API密钥和相关服务的授权凭证。
```dotenv
# 示例:配置OpenAI模型
OPENAI_BASE_URL="https://api.openai.com/v1"
OPENAI_API_KEY="sk-..."
# 示例:配置GitHub
GITHUB_TOKENS="your_github_token"
GITHUB_EVAL_ORG="your_eval_org"
# 示例:配置Notion
SOURCE_NOTION_API_KEY="your_source_notion_api_key"
EVAL_NOTION_API_KEY="your_eval_notion_api_key"
4) Experiment zur operationellen Bewertung
Sie können je nach Bedarf verschiedene Aufgabenbereiche ausführen.
# 假设实验名为 new_exp,模型为 gpt-4.1,环境为 notion,运行K次
# 评估该环境下的所有任务
python -m pipeline --exp-name new_exp --mcp notion --tasks all --models gpt-4.1 --k K
# 评估一个任务组 (例如 online_resume)
python -m pipeline --exp-name new_exp --mcp notion --tasks online_resume --models gpt-4.1 --k K
5. die Anzeige und Aggregation der Ergebnisse
Die Ergebnisse werden in den Formaten JSON und CSV in der Datei./results/Verzeichnis. Wenn Ihre Laufzahl K größer als 1 ist, können Sie den folgenden Befehl ausführen, um einen Aggregationsbericht zu erstellen.
python -m src.aggregators.aggregate_results --exp-name new_exp
Anwendungsszenario
- Bewertung der Fähigkeiten des intelligenten Körpers von Modellen
Forschungseinrichtungen und Entwickler können diesen Benchmark nutzen, um objektiv die Fähigkeit verschiedener moderner KI-Modelle zu messen, bei der Bewältigung komplexer Arbeitsabläufe - und nicht nur einfacher API-Aufrufe - selbstständig zu planen, zu argumentieren und Werkzeuge zu nutzen. - AI Intelligence Body Regressionstests
Für Teams, die KI-Smartbody-Anwendungen entwickeln, kann MCPMark als Standard-Regressionstest-Set verwendet werden, um sicherzustellen, dass iterative Aktualisierungen des Modells oder der Anwendung nicht zu einer Verschlechterung der Smartbody-Funktionen führen. - Akademische Forschung zu Intelligent Body AI
Wissenschaftler können diese standardisierte Plattform nutzen, um reproduzierbare Forschungsergebnisse über die Fähigkeiten von KI-Intelligenzen zu veröffentlichen und so das gesamte Feld voranzubringen. - Validierung des Autonomiegrads von Geschäftsprozessen
Unternehmen können MCPMark nutzen, um den Grad der autonomen Automatisierung zu testen, den KI-Modelle in bestimmten Geschäftsszenarien erreichen können (z. B. Code-Repository-Verwaltung, Datenbankbetrieb).
QA
- Was genau ist MCPMark?
Es handelt sich um ein Standard-Benchmarking-Tool, nicht um eine KI-Anwendung für allgemeine Benutzer. Sein Hauptzweck besteht darin, eine Reihe zuverlässiger Umgebungen und Aufgaben bereitzustellen, um die Fähigkeit verschiedener KI-Makromodelle, komplexe Aufgaben als "Agenten" autonom auszuführen, wissenschaftlich zu bewerten und zu vergleichen. - Was ist MCP (Model Context Protocol)?
MCP (Model Context Protocol) ist eine Reihe von technischen Standards und Protokollen, die die Interaktion von KI-Makromodellen mit externen Werkzeugen und Softwareumgebungen regeln. MCPMark basiert auf dieser Reihe von Protokollen, um sicherzustellen, dass die Interaktion von Modellen mit ihren Umgebungen kontrolliert, messbar und reproduzierbar ist. - Ist es sicher, den MCPMark-Test durchzuführen?
Ja, es ist sehr sicher. Es läuft in einer völlig isolierten Sandbox-Umgebung, die für jedes Experiment erstellt wird. Sobald die Mission beendet ist, wird diese Umgebung vollständig zerstört, sodass keine persönlichen Dateien oder Kontodaten auf Ihrem lokalen Rechner berührt oder verändert werden. - Was ist der pass@K-Indikator?
pass@Kist ein wichtiges Maß für die Zuverlässigkeit des Modells. Sie gibt die Wahrscheinlichkeit an, dass das Modell die Aufgabe mindestens einmal von K unabhängigen Versuchen erfolgreich abschließen wird. Je höher diese Kennzahl ist, desto stabiler und zuverlässiger ist die Fähigkeit des Modells, die Aufgabe als intelligenter Körper zu erfüllen.
































