


LMCache ist ein quelloffenes Key-Value (KV) Cache-Optimierungstool, das entwickelt wurde, um die Effizienz der Argumentation in Large Language Models (LLMs) zu verbessern. Es reduziert die Inferenzzeit und den GPU-Ressourcenverbrauch durch Zwischenspeicherung und Wiederverwendung von Berechnungsergebnissen (Key-Value-Caching) des Modells erheblich, was besonders für Szenarien mit langem Kontext geeignet ist.LMCache ist kompatibel mit dem vLLM Es lässt sich nahtlos in andere Inferenz-Engines integrieren und unterstützt GPU-, CPU- und Festplattenspeicher für Szenarien wie Multi-Runden-Q&A und Retrieval Augmented Generation (RAG). Das Projekt wird von der Community betrieben, steht unter der Apache 2.0-Lizenz und wird häufig für die Optimierung von KI-Inferenzen auf Unternehmensebene verwendet.
Funktionsliste
- Wiederverwendung von Schlüsselwerten im CacheLLM-Schlüssel-Wert-Paare zwischenspeichern, Wiederverwendung von Text ohne Vorzeichen unterstützen, Doppelzählungen reduzieren.
- Unterstützung für mehrere Speicherplätze im BackendUnterstützt Speicher wie GPU, CPU DRAM, Festplatte und Redis für Flexibilität bei Speicherbeschränkungen.
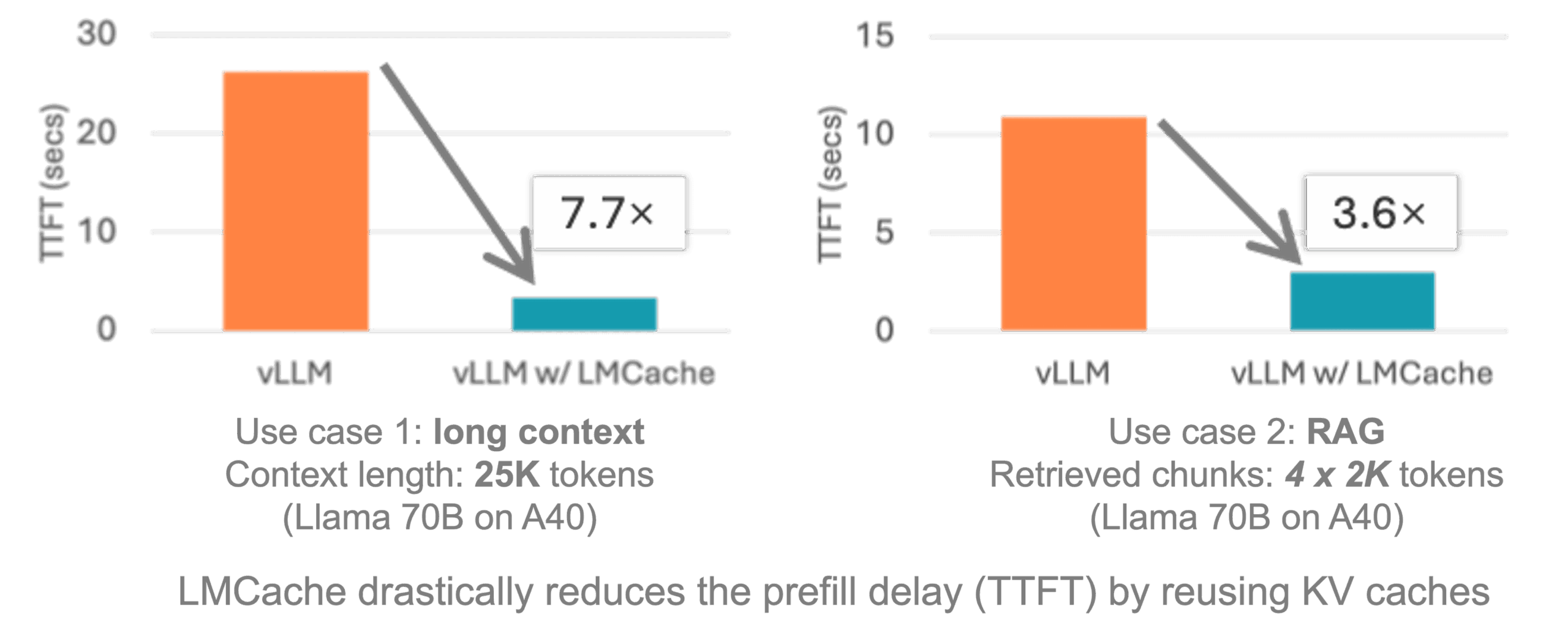
- Integration mit vLLMNahtloser Zugang zu vLLM, der eine 3-10fache Optimierung der Inferenzlatenz ermöglicht.
- verteilter CacheUnterstützung für gemeinsames Caching auf mehreren GPUs oder in Container-Umgebungen für groß angelegte Implementierungen.
- multimodale UnterstützungCaching: Zwischenspeicherung von Schlüssel-Wert-Paaren von Bildern und Text zur Optimierung der multimodalen Modellinferenz.
- Generierung von ArbeitslastenBereitstellung von Testwerkzeugen zur Erzeugung von Workloads wie Mehrrunden-Quiz, RAGs usw. zur Leistungsüberprüfung.
- Unterstützung der Open-Source-GemeinschaftBereitstellung von Dokumentation, Beispielen und Community-Treffen zur Erleichterung der Beiträge und des Austauschs der Nutzer.
Hilfe verwenden
Einbauverfahren
LMCache ist einfach zu installieren und unterstützt Linux-Plattformen und NVIDIA-GPU-Umgebungen. Nachfolgend finden Sie die detaillierten Installationsschritte, basierend auf der offiziellen Dokumentation und den Empfehlungen der Community.
- Vorbereiten der Umgebung:
- Stellen Sie sicher, dass Ihr System Linux, Python Version 3.10 oder höher, und CUDA Version 12.1 oder höher ist.
- Installieren Sie Conda (empfohlen wird Miniconda), um eine virtuelle Umgebung zu schaffen:
conda create -n lmcache python=3.10 conda activate lmcache
- Klon-Lager:
- Verwenden Sie Git, um Ihr LMCache-Repository lokal zu klonen:
git clone https://github.com/LMCache/LMCache.git cd LMCache
- Verwenden Sie Git, um Ihr LMCache-Repository lokal zu klonen:
- Installieren von LMCache:
- Installieren Sie die neueste stabile Version über PyPI:
pip install lmcache - Oder installieren Sie die neueste Vorabversion (die möglicherweise experimentelle Funktionen enthält):
pip install --index-url https://pypi.org/simple --extra-index-url https://test.pypi.org/simple lmcache==0.2.2.dev57 - Wenn Sie von der Quelle installieren müssen:
pip install -e .
- Installieren Sie die neueste stabile Version über PyPI:
- Installation von vLLM:
- LMCache muss mit vLLM verwendet werden, installieren Sie die neueste Version von vLLM:
pip install vllm
- LMCache muss mit vLLM verwendet werden, installieren Sie die neueste Version von vLLM:
- Überprüfen der Installation:
- Überprüfen Sie, ob LMCache korrekt installiert ist:
python import lmcache from importlib.metadata import version print(version("lmcache"))Die Ausgabe sollte die Versionsnummer der Installation sein, z. B.
0.2.2.dev57。
- Überprüfen Sie, ob LMCache korrekt installiert ist:
- Optional: Docker-Bereitstellung:
- LMCache bietet vorgefertigte Docker-Images mit vLLM-Integration:
docker pull lmcache/lmcache:latest - Starten Sie den Docker-Container und konfigurieren Sie vLLM und LMCache gemäß der Dokumentation.
- LMCache bietet vorgefertigte Docker-Images mit vLLM-Integration:
Verwendung der Hauptfunktionen
Die Kernfunktion von LMCache ist die Optimierung des Key-Value-Cache zur Beschleunigung der LLM-Inferenz. Im Folgenden finden Sie eine detaillierte Anleitung für die wichtigsten Funktionen.
1. die Wiederverwendung von Schlüsselwerten im Cache
LMCache vermeidet die wiederholte Berechnung desselben Textes oder Kontextes, indem es den Key Value Cache (KV-Cache) des Modells speichert. Benutzer können LMCache in vLLM aktivieren:
- Umgebungsvariablen konfigurieren:
export LMCACHE_USE_EXPERIMENTAL=True export LMCACHE_CHUNK_SIZE=256 export LMCACHE_LOCAL_CPU=True export LMCACHE_MAX_LOCAL_CPU_SIZE=5.0Diese Variablen legen fest, dass LMCache die experimentelle Funktion verwendet, 256 Token pro Block verwendet, das CPU-Backend aktiviert und den CPU-Speicher auf 5 GB begrenzt.
- Ausführen einer vLLM-Instanz:
LMCache lädt und speichert automatisch Schlüssel-Wert-Paare, wenn Sie vLLM starten. Beispielcode:from vllm import LLM from lmcache.integration.vllm.utils import ENGINE_NAME from vllm.config import KVTransferConfig ktc = KVTransferConfig(kv_connector="LMCacheConnector", kv_role="kv_both") llm = LLM(model="meta-llama/Meta-Llama-3.1-8B-Instruct", kv_transfer_config=ktc)
2. mehrere Speicherplätze im Backend
LMCache unterstützt die Speicherung von Key-Value-Cache auf GPU, CPU, Festplatte oder Redis. Benutzer können die Speichermethode entsprechend der Hardware-Ressourcen wählen:
- Lokaler Plattenspeicher:
python3 -m lmcache_server.server localhost 9000 /path/to/diskDadurch wird der LMCache-Server gestartet, der den Cache im angegebenen Pfad speichert.
- Redis-Speicher:
Um das Redis-Backend zu konfigurieren, müssen Sie einen Benutzernamen und ein Passwort einrichten, siehe Dokumentation:export LMCACHE_REDIS_USERNAME=user export LMCACHE_REDIS_PASSWORD=pass
3. verteiltes Caching
In Umgebungen mit mehreren GPUs oder Containern unterstützt LMCache die gemeinsame Zwischenspeicherung auf mehreren Knoten:
- Starten Sie den LMCache-Server:
python3 -m lmcache_server.server localhost 9000 cpu - Konfigurieren Sie die vLLM-Instanz für die Verbindung mit dem Server, siehe
disagg_vllm_launcher.shBeispiel.
4. multimodale Unterstützung
LMCache unterstützt ein multimodales Modell zur Optimierung der visuellen LLM-Inferenz durch die Zwischenspeicherung von Schlüssel-Wert-Paaren über Hash-Bild-Token (mm_hashes):
- Um die multimodale Unterstützung in vLLM zu aktivieren, sehen Sie sich das offizielle Beispiel an
LMCache-ExamplesLagerhaus.
5) Prüfwerkzeuge
LMCache stellt Testwerkzeuge zur Verfügung, um Workloads zu generieren und die Leistung zu überprüfen:
- Clone Test Warehouse:
git clone https://github.com/LMCache/lmcache-tests.git cd lmcache-tests bash prepare_environment.sh - Führen Sie die Testfälle aus:
python3 main.py tests/tests.py -f test_lmcache_local_cpu -o outputs/Die Ausgabe wird in der Datei
outputs/test_lmcache_local_cpu.csv。
Vorsichtsmaßnahmen bei der Handhabung
- UmweltinspektionenUm sicherzustellen, dass die CUDA- und Python-Versionen kompatibel sind, wird empfohlen, die Conda-Verwaltungsumgebung zu verwenden.
- Log-Überwachung: Inspektion
prefiller.log、decoder.log和proxy.logum das Problem zu beheben. - Unterstützung der GemeinschaftTreten Sie dem LMCache-Slack bei oder besuchen Sie ein zweiwöchentliches Community-Treffen dienstags um 9 Uhr PT, um Hilfe zu erhalten.
Anwendungsszenario
- Multicast-Frage-Antwort-System
LMCache speichert Schlüssel-Werte-Paare im Kontext, um Dialogszenarien mit mehreren Runden zu beschleunigen. Wenn ein Benutzer aufeinanderfolgende Fragen im Chatbot stellt, verwendet LMCache die vorherigen Berechnungsergebnisse wieder, um die Latenz zu verringern. - Retrieval Augmentation Generation (RAG)
在 RAG In der Anwendung zwischenspeichert LMCache Schlüssel-Wert-Paare von Dokumenten und antwortet schnell auf ähnliche Abfragen, wodurch es sich für die intelligente Dokumentensuche oder Wissensdatenbanken in Unternehmen eignet. - Multimodale Modellinferenz
Bei visuell-linguistischen Modellen speichert LMCache Schlüssel-Wert-Paare von Bildern und Text im Cache, wodurch der Speicherbedarf der GPU reduziert und die Reaktionszeit verbessert wird. - Massiv verteilter Einsatz
In Umgebungen mit mehreren GPUs oder Containern unterstützen die verteilten Caching-Fähigkeiten von LMCache die gemeinsame Nutzung durch mehrere Knoten, um die KI-Inferenz auf Unternehmensebene zu optimieren.
QA
- Welche Plattformen werden von LMCache unterstützt?
Derzeit werden Linux und NVIDIA GPU-Umgebungen unterstützt, und Windows kann über WSL verwendet werden. - Wie funktioniert die Integration mit vLLM?
passieren (eine Rechnung oder Inspektion etc.)pip install lmcache vllmund aktivieren Sie LMCacheConnector in der vLLM-Konfiguration, siehe den offiziellen Beispielcode. - Wird die Zwischenspeicherung von Nicht-Präfixen unterstützt?
Unterstützung verwendet LMCache Techniken zur teilweisen Neuberechnung, um nicht vorangestellten Text in RAG-Workloads zu cachen. - Wie lassen sich Leistungsprobleme beheben?
Prüfen Sie Protokolldateien und führen Sie Testfälle aus, geben Sie CSV-Dateien aus, um Latenz und Durchsatz zu analysieren.




























