



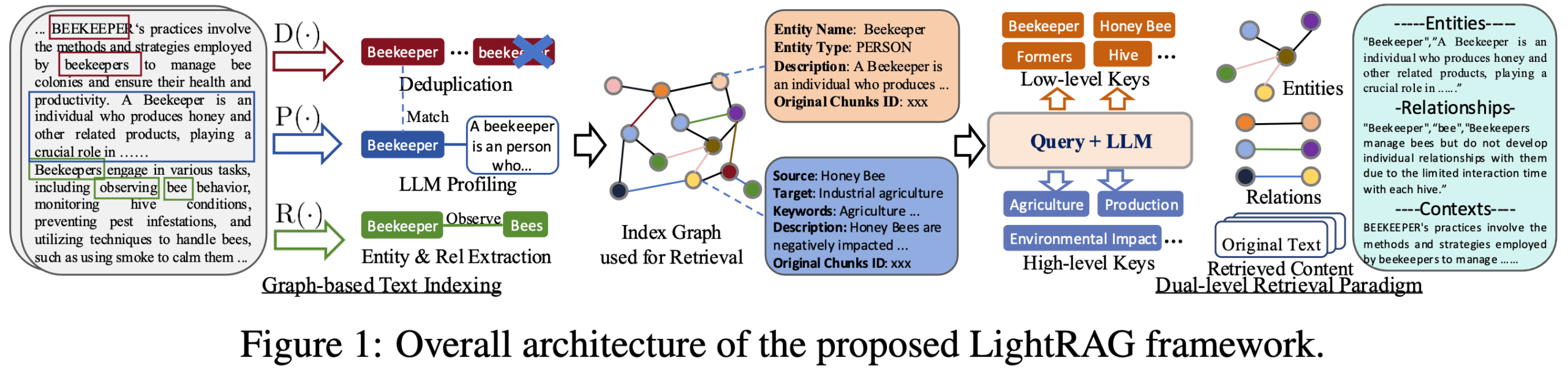
LightRAG ist ein quelloffenes Python-Framework, das von einem Team der School of Data Science an der Universität Hongkong entwickelt wurde, um den Aufbau von Retrieval Augmented Generation (RAG)-Anwendungen zu vereinfachen und zu beschleunigen. Es verbessert die Qualität der generierten Inhalte durch die Kombination von Wissensgraphen mit traditionellen Vektor-Retrieval-Techniken, um genauere und kontextuell relevante Informationen für Large Language Models (LLMs) zu liefern. Das Kernmerkmal des Frameworks ist sein leichtgewichtiges und modulares Design, das den komplexen RAG-Prozess in mehrere unabhängige Komponenten aufteilt, wie z.B. Dokumenten-Parsing, Indexaufbau, Information Retrieval, Inhaltsumordnung und Textgenerierung. Dieses Design senkt nicht nur die Schwelle für Entwickler, sondern bietet auch ein hohes Maß an Flexibilität, so dass Benutzer verschiedene Module leicht ersetzen oder an ihre spezifischen Bedürfnisse anpassen können, z. B. durch die Integration verschiedener Vektordatenbanken, Graphdatenbanken oder großer Sprachmodelle. LightRAG wurde für Szenarien entwickelt, in denen komplexe Informationen und tiefe Beziehungen verarbeitet werden müssen, und löst das Problem der fragmentierten Textinformationen und des Mangels an tiefen Verbindungen in traditionellen RAG-Systemen.
Funktionsliste
- Modularer AufbauRAG: Zerlegung des RAG-Prozesses in klare, leicht verständliche und anpassbare Module für das Parsen, Indizieren, Abrufen, Umformatieren und Generieren von Dokumenten.
- Integration von WissensgraphenDie Fähigkeit, automatisch Entitäten und Beziehungen aus unstrukturiertem Text zu extrahieren und Wissensgraphen zu erstellen, die ein tieferes Verständnis und die Korrelation von Informationen ermöglichen.
- zweistufiger SuchmechanismusKombiniert vektorbasierte Ähnlichkeitssuche und wissensgraphenbasiertes Assoziationsretrieval und ist in der Lage, Abfragen sowohl nach spezifischen Details (lokal) als auch nach Makrokonzepten (global) zu bearbeiten.
- Flexible SpeicheroptionenUnterstützt eine Vielzahl von Speicher-Backends, einschließlich Json, PostgreSQL und Redis für die Speicherung von Schlüssel-Wert-Paaren; FAISS, Chroma und Milvus für die Vektorspeicherung; und Neo4j und PostgreSQL AGE für die Graphenspeicherung.
- Hohe ModellkompatibilitätUnterstützung des Zugriffs auf eine breite Palette von Large Language Models (LLMs) und Embedding Models, einschließlich solcher, die von Plattformen wie OpenAI, Hugging Face und Ollama bereitgestellt werden.
- Unterstützung mehrerer DateiformateFähigkeit, eine breite Palette von Dokumentenformaten zu verarbeiten, darunter PDF, DOCX, PPTX, CSV und reiner Text.
- Werkzeuge zur VisualisierungBietet eine Webschnittstelle zur Unterstützung der visuellen Erkundung von Wissensgraphen, die es den Benutzern ermöglicht, die Verbindungen zwischen Daten zu visualisieren.
- multimodale FähigkeitErweiterter Umgang mit multimodalen Inhalten wie Bildern, Tabellen, Formeln, etc. durch die Integration mit RAG-Anything.
Hilfe verwenden
LightRAG ist ein leistungsfähiges und benutzerfreundliches Framework, das Entwicklern helfen soll, schnell intelligente Q&A-Systeme auf der Grundlage ihrer eigenen Wissensbasis zu erstellen. Sein größtes Merkmal ist die Kombination von Wissensgraphen, wodurch die Suchergebnisse nicht nur relevant sind, sondern auch stärkere logische Beziehungen aufweisen. Im Folgenden werden die Installation und die Verwendung des Prozesses im Detail vorgestellt.
Montage
Der Einstieg in LightRAG ist sehr einfach und kann direkt über pip, den Paketmanager von Python, installiert werden. Es wird empfohlen, die Vollversion mit API und Webschnittstelle zu installieren, um die volle Funktionalität einschließlich der Visualisierung von Wissensgraphen zu nutzen.
- Installation über PyPI:
Öffnen Sie ein Terminal und führen Sie den folgenden Befehl aus:pip install "lightrag-hku[api]"Dieser Befehl installiert die LightRAG-Kernbibliotheken und die zugehörigen Abhängigkeiten, die von den Servern benötigt werden.
- Umgebungsvariablen konfigurieren:
Nach Abschluss der Installation müssen Sie die Laufzeitumgebung konfigurieren. LightRAG bietet eine Vorlage für die Umgebungsdateienv.example. Sie müssen sie kopieren als.envund passen Sie die Konfiguration an Ihre Situation an, vor allem die API-Schlüssel für das Large Language Model (LLM) und das Embedding Model.cp env.example .envÖffnen Sie sie dann in einem Texteditor
.envDatei, tragen Sie IhreOPENAI_API_KEYoder andere Zugangsdaten für das Modell. - Neue Dienste:
Sobald die Konfiguration abgeschlossen ist, führen Sie den folgenden Befehl direkt über das Terminal aus, um den LightRAG-Dienst zu starten:lightrag-serverSobald der Dienst gestartet ist, können Sie über einen Browser auf die von ihm bereitgestellte Webschnittstelle zugreifen oder über eine API mit ihm interagieren.
Kernnutzungsprozess
Der zentrale Programmierungsprozess der LightRAG folgt einem klaren RAG Logik:Datenzufuhr -> Indexaufbau -> Abfragegenerierung. Nachfolgend finden Sie ein einfaches Python-Codebeispiel, das zeigt, wie ein vollständiger Q&A-Prozess mit LightRAG Core implementiert werden kann.
- Initialisierung einer LightRAG-Instanz
Zunächst müssen Sie die erforderlichen Module importieren und eine LightRAG-Instanz erstellen. Während der Initialisierung müssen Sie das Arbeitsverzeichnis (für Daten und Cache), eingebettete Funktionen und LLM-Funktionen angeben.import os import asyncio from lightrag import LightRAG, QueryParam from lightrag.llm.openai import gpt_4o_mini_complete, openai_embed from lightrag.kg.shared_storage import initialize_pipeline_status # 设置工作目录 WORKING_DIR = "./rag_storage" if not os.path.exists(WORKING_DIR): os.mkdir(WORKING_DIR) # 设置你的OpenAI API密钥 os.environ["OPENAI_API_KEY"] = "sk-..." async def initialize_rag(): # 创建LightRAG实例,并注入模型函数 rag = LightRAG( working_dir=WORKING_DIR, embedding_func=openai_embed, llm_model_func=gpt_4o_mini_complete, ) # 重要:必须初始化存储和处理管道 await rag.initialize_storages() await initialize_pipeline_status() return ragzur Kenntnis nehmen:
initialize_storages()和initialize_pipeline_status()Diese beiden Initialisierungsschritte sind erforderlich, sonst meldet das Programm einen Fehler. - Fütterungsdaten (Einfügen)
Sobald die Initialisierung abgeschlossen ist, können Sie Ihre Textdaten zu LightRAG hinzufügen.ainsertMethode empfängt eine Zeichenkette oder eine Liste von Zeichenketten.async def feed_data(rag_instance): text_to_insert = "史蒂芬·乔布斯是一位美国商业巨头和发明家。他是苹果公司的联合创始人、董事长和首席执行官。乔布斯被广泛认为是微型计算机革命的先驱。" await rag_instance.ainsert(text_to_insert) print("数据投喂成功!")In diesem Schritt zerlegt LightRAG den Text automatisch, extrahiert Entitäten und Beziehungen, erzeugt Vektoreinbettungen und baut den Wissensgraphen im Hintergrund auf.
- Daten abfragen (Query)
Sobald die Daten eingespeist und indiziert sind, können sie abgefragt werden.aqueryMethode empfängt eine Frage und leitet sie durch dieQueryParamObjekt, um das Verhalten der Abfrage zu steuern.async def ask_question(rag_instance): query_text = "谁是苹果公司的联合创始人?" # 使用QueryParam配置查询模式 # "hybrid" 模式结合了向量搜索和图检索,推荐使用 query_params = QueryParam(mode="hybrid") response = await rag_instance.aquery(query_text, param=query_params) print(f"问题: {query_text}") print(f"答案: {response}") - Kombinieren und ausführen
Schließlich fassen wir die oben genannten Schritte in einer Hauptfunktion zusammen und verwenden dieasynciozu laufen.async def main(): rag = None try: rag = await initialize_rag() await feed_data(rag) await ask_question(rag) except Exception as e: print(f"发生错误: {e}") finally: if rag: # 程序结束时释放存储资源 await rag.finalize_storages() if __name__ == "__main__": asyncio.run(main())
Abfrage-Muster erklärt
LightRAG bietet mehrere Abfragemodi für unterschiedliche Anwendungsszenarien:
naive: Einfaches Vektorsuchmuster für einfache Quizfragen.localDie Suche konzentriert sich auf Entitätsinformationen, die für die Anfrage direkt relevant sind, und eignet sich für Szenarien, die präzise, konkrete Antworten erfordern.globalSchwerpunkt: Beziehungen zwischen Entitäten und globales Wissen für Szenarien, die makroskopische, korrelative Antworten erfordern.hybrid:: Kombiniertlocal和globalDie Vorteile dieses Modells liegen darin, dass es am vielseitigsten und in der Regel auch am effektivsten ist.mixIntegration von Knowledge Graph und Vector Retrieval ist das Empfehlungsmodell in den meisten Fällen.
Durch die Verwendung des QueryParam aufstellen mode haben Sie die Möglichkeit, zwischen diesen Modi zu wechseln, um die besten Abfrageergebnisse zu erzielen.
Anwendungsszenario
- Intelligente Kundenbetreuung und Q&A-System
Unternehmen können interne Informationen wie Produkthandbücher, Hilfedateien und historische Kundendienstaufzeichnungen in LightRAG einspeisen, um einen intelligenten Kundendienstroboter aufzubauen, der Kundenfragen präzise und schnell beantworten kann. Dank der Kombination von Wissensgraphen kann das System nicht nur Antworten finden, sondern auch die damit zusammenhängenden Informationen hinter den Fragen verstehen und umfassendere Antworten geben, z. B. kann es bei der Beantwortung einer Frage zu den Funktionen eines Produkts zusammen mit der Antwort entsprechende Tipps oder Links zu häufig gestellten Fragen bereitstellen. - Unternehmensinternes Wissensdatenbankmanagement
Für Organisationen mit einer großen Menge interner Dokumente (z. B. technische Dokumente, Projektberichte, Regeln und Vorschriften) kann LightRAG diese in eine strukturierte, intelligent abfragbare Wissensbasis umwandeln. Die Mitarbeiter können Fragen in natürlicher Sprache stellen, schnell die benötigten Informationen finden und sogar versteckte Verbindungen zwischen verschiedenen Dokumenten entdecken, was die Effizienz der Informationsbeschaffung und die Nutzung des Wissens erheblich verbessert. - Wissenschaftliche Forschung und Literaturanalyse
Forscher können LightRAG verwenden, um eine große Anzahl von akademischen Arbeiten und Forschungsberichten zu verarbeiten. Das System ist in der Lage, automatisch die wichtigsten Entitäten (z. B. Technologien, Wissenschaftler, Experimente), Konzepte und ihre Beziehungen zu extrahieren und sie zu einem Wissensgraphen zusammenzustellen. Dies ermöglicht es den Forschern, auf einfache Weise Wissen über Dokumente hinweg zu erforschen, z. B. die Anwendung einer bestimmten Technologie in verschiedenen Studien oder die Zusammenarbeit zwischen zwei Wissenschaftlern, was den Forschungsprozess beschleunigt. - Analyse von Finanz- und Rechtsdokumenten
In Berufsfeldern wie dem Finanz- und Rechtswesen, wo Dokumente oft komplex und umfangreich sind, kann LightRAG Analysten oder Anwälten helfen, Schlüsselinformationen aus Dokumenten wie Jahresberichten, Prospekten, Rechtsklauseln usw. schnell zu extrahieren und die logischen Beziehungen zwischen ihnen zu erkennen. So ist es beispielsweise möglich, schnell alle verantwortlichen Parteien in einem Vertrag und ihre entsprechenden Rechte und Pflichten zu ermitteln oder die Beschreibungen desselben Geschäfts in den Finanzberichten mehrerer Unternehmen zu analysieren, um die Entscheidungsfindung zu erleichtern.
QA
- Wie unterscheidet sich LightRAG von generischen Frameworks wie LangChain oder LlamaIndex?
Das Hauptunterscheidungsmerkmal von LightRAG ist sein Fokus auf die tiefe Integration von Wissensgraphen in den RAG-Prozess, mit dem Ziel, das Problem der Fragmentierung traditioneller RAG-Informationen zu lösen. Während LangChain und LlamaIndex umfassendere, universell einsetzbare LLM-Anwendungsentwicklungsframeworks sind, die eine Fülle von Werkzeugen und Integrationsoptionen bieten, aber auch eine relativ steile Lernkurve haben, ist LightRAG leichtgewichtiger und zielt darauf ab, Entwicklern eine einfache, schnelle und effiziente RAG-Lösung mit einem eingebauten Wissensgraphen zu bieten. - Gibt es besondere Anforderungen an das Large Language Model (LLM) für die Verwendung von LightRAG?
Ja, da LightRAG LLM verwenden muss, um Entitäten und Beziehungen aus Dokumenten zu extrahieren und einen Wissensgraphen zu erstellen, erfordert dies ein hohes Maß an Befehlsverfolgungsfähigkeit und kontextbezogenem Verständnis des Modells. Offiziell wird empfohlen, ein Modell mit einer Referenzanzahl von mindestens 32 Milliarden und einer Kontextfensterlänge von mindestens 32KB zu verwenden. 64KB werden empfohlen, um sicherzustellen, dass längere Dokumente verarbeitet werden können und die Entitätsextraktion genau durchgeführt werden kann. - Welche Arten von Datenbanken werden von LightRAG unterstützt?
Die Speicherschicht von LightRAG ist modular aufgebaut und unterstützt mehrere Datenbankimplementierungen. Für Key-Value Storage (KV Storage) werden native JSON-Dateien, PostgreSQL, Redis und MongoDB unterstützt. Für Vector Storage (Vector Storage) werden NanoVectorDB (Standard), FAISS, Chroma, Milvus und andere unterstützt. Für die Graphenspeicherung werden NetworkX (Standard), Neo4j und PostgreSQL mit dem AGE-Plugin unterstützt. Dieses Design ermöglicht den Benutzern eine flexible Auswahl je nach ihrem Technologie-Stack und ihren Leistungsanforderungen. - Kann ich meine eigenen Modelle in LightRAG verwenden? Zum Beispiel Modelle, die bei Hugging Face oder Ollama eingesetzt werden?
LightRAG hat einen flexiblen Modellinjektionsmechanismus entwickelt, der es den Nutzern ermöglicht, benutzerdefinierte LLMs und eingebettete Modelle zu integrieren. Der Beispielcode im Repository bietet bereits Zugriff auf das Hugging Face und die Ollama Modellbeispiel. Sie müssen lediglich eine Aufruffunktion schreiben, die der Schnittstellenspezifikation entspricht, und diese bei der Initialisierung einer LightRAG-Instanz übergeben, so dass sie nahtlos mit allen Arten von Open-Source- oder privat bereitgestellten Modellen arbeiten kann.































